OpenAI还能领先多久?Meta、微软们正从场景、算力、成本端全面围剿
要点总结
算力竞争:人工智能领域内的大型科技公司正在通过不断增加的GPU采购和开发更先进的AI模型来激烈竞争,OpenAI正在被全面围攻。
技术与成本竞争:中国公司DeepSeek通过开源高效能、低成本的AI模型正在改变市场竞争格局,为企业提供了更多自主选择和成本效益更高的解决方案。
微软是否靠得住:微软在积极发展自己的AI技术和模型,以减少对单一合作伙伴的依赖并应对潜在的控制权风险。
所有人都在关注人工智能领域无利可图的支出会持续多久。H100 的租赁价格每个月都在下降,并且中型集群的可用性正在以合理的价格快速增长。尽管如此,显然需求动力仍然强劲。虽然大型科技公司仍然是最大的买家,但全球范围内越来越多样化的买家名单仍在连续增加 GPU 采购量。
大多数繁荣并不是由于任何形式的收入增长,而是由于基于对未来业务的梦想而急于建立更大的模型。大多数人心中的明确目标是赶上甚至超越 OpenAI。如今,许多公司距离 OpenAI 在 Chatbot ELO 中最新的 GPT-4 仅有很短的距离,并且在上下文长度和视频模式等某些方面,一些公司已经处于领先地位。
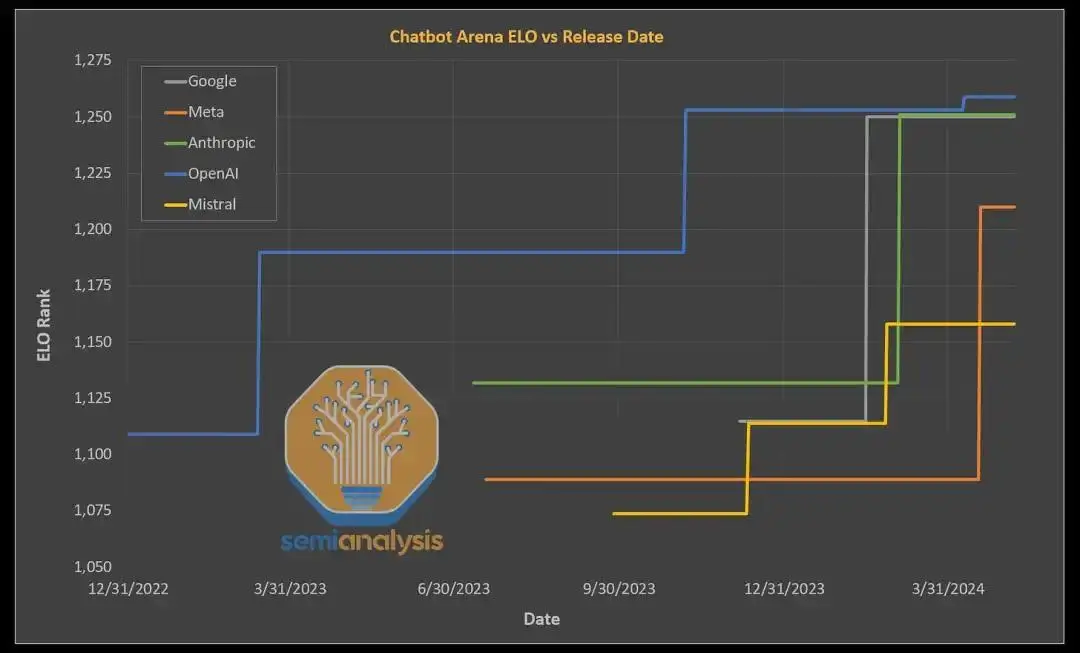
资料来源:SemiAnalysis 、ArtificialAnalysis.ai
很明显,只要有足够的计算能力,最大的科技公司就可以与 OpenAI 的 GPT-4 相媲美。据传 Gemini 2 Ultra 在各方面都超越了 GPT-4 Turbo。此外,Meta 的 Llama 3 405B 在开源的同时也将与 GPT-4 相匹配,这意味着任何可以租用 H100 服务器的人都可以使用 GPT-4 级智能。
01 DeepSeek奋起直追
迅速迎头赶上的不仅仅是美国大型科技公司。中国的DeepSeek开源了一款新模型,它的运行成本比 Meta 的 Llama 3 70B 更便宜,而且性能更好。虽然该模型更适合中文查询(分词器/训练数据集)和内容审查,但它也恰好在代码(HumanEval)和数学(GSM 8k)的通用语言中获胜。
此外,定价非常便宜。Deepseek 的模型明显比任何其他竞争模型便宜。他们的定价甚至超越了正在进行的风投竞逐,这些风投投资于推理 API 提供商,而这些提供商在服务 Meta 和 Mistral 模型时赔钱。
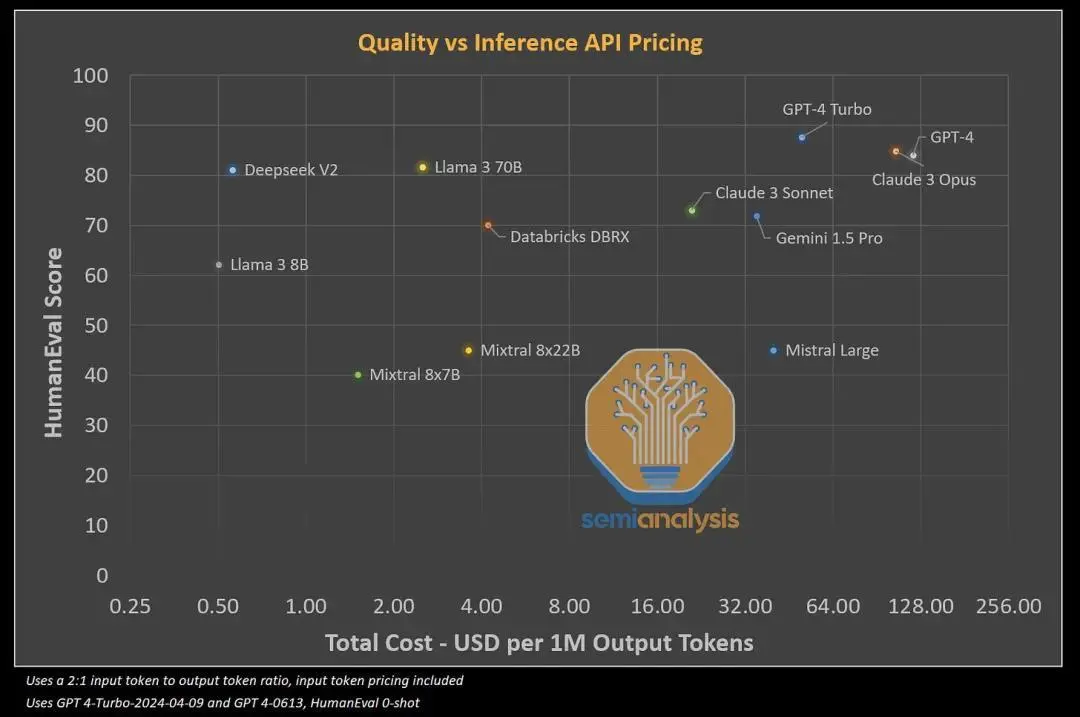
资料来源:SemiAnalysis 、ArtificalAnalysis.ai 、各种模型基准
DeepSeek 声称,8 个H800 GPU 的单个节点可以实现每秒超过 50,000 个解码令牌的峰值吞吐量(或在具有 disagg 预填充的节点中实现 100k 预填充)。仅根据输出代币的 API 报价,每个节点每小时的收入为 50.4 美元。在中国,8xH800 节点的成本约为每小时 15 美元,因此假设利用率完美,每台服务器每小时可赚取 35.4 美元,即毛利率高达 70% 以上。
即使假设服务器从未得到完美利用,并且批量大小低于峰值能力,DeepSeek 仍有足够的赚钱空间,同时在成本上击败竞争对手。毫无疑问的是,Mixtral、Claude 3 Sonnet、Llama 3 和 DBRX 已经击败了 OpenAI 的 GPT-3.5 Turbo。
更有趣的是 DeepSeek 推向市场的新颖架构。他们没有效仿西方公司的做法。MoE、RoPE 和 Attention 都有全新的创新。他们的模型有 160 多名专家,每个前向传递有 6 个专家。总参数为 2360 亿个,每个前向传递有 210 亿个活跃参数。此外,DeepSeek 实现了一种新颖的多头潜在注意力机制,他们声称该机制比其他形式的注意力具有更好的扩展性,同时也更准确。
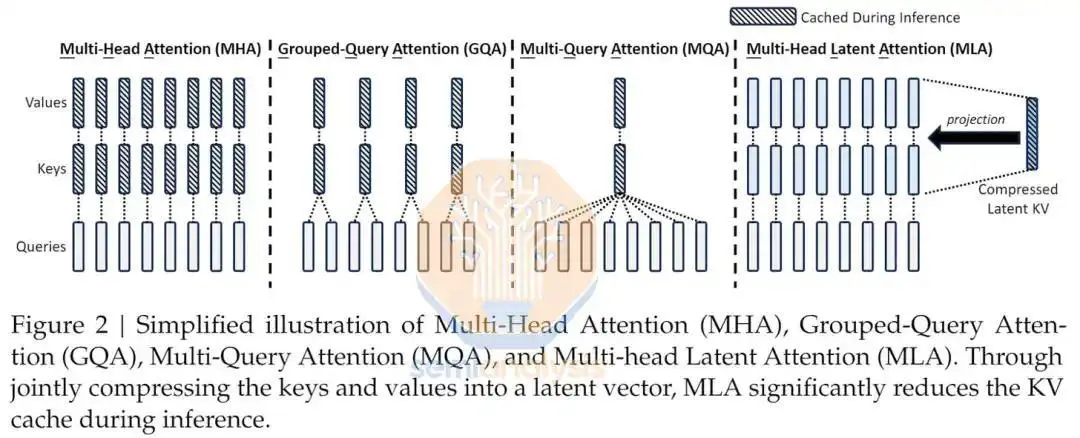
来源:DeepSeek
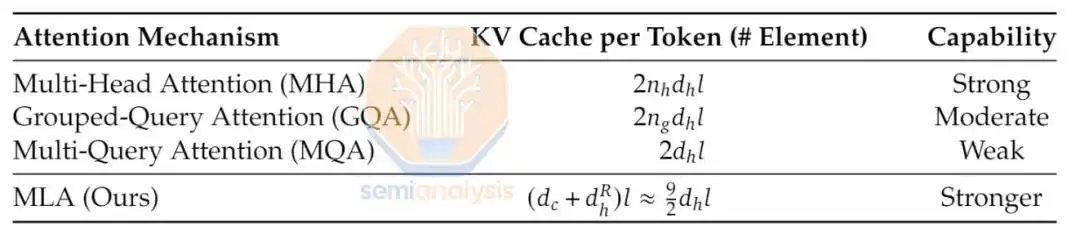
来源:DeepSeek
他们使用 8.1 万亿个代币训练模型。DeepSeek V2 能够实现令人难以置信的训练效率,其模型性能优于其他开放模型,计算量仅为 Meta 的 Llama 3 70B 的1/5 。对于那些跟踪的人来说,DeepSeek V2 训练所需的失败次数是 GPT-4 的1/20,而性能却相差不远。
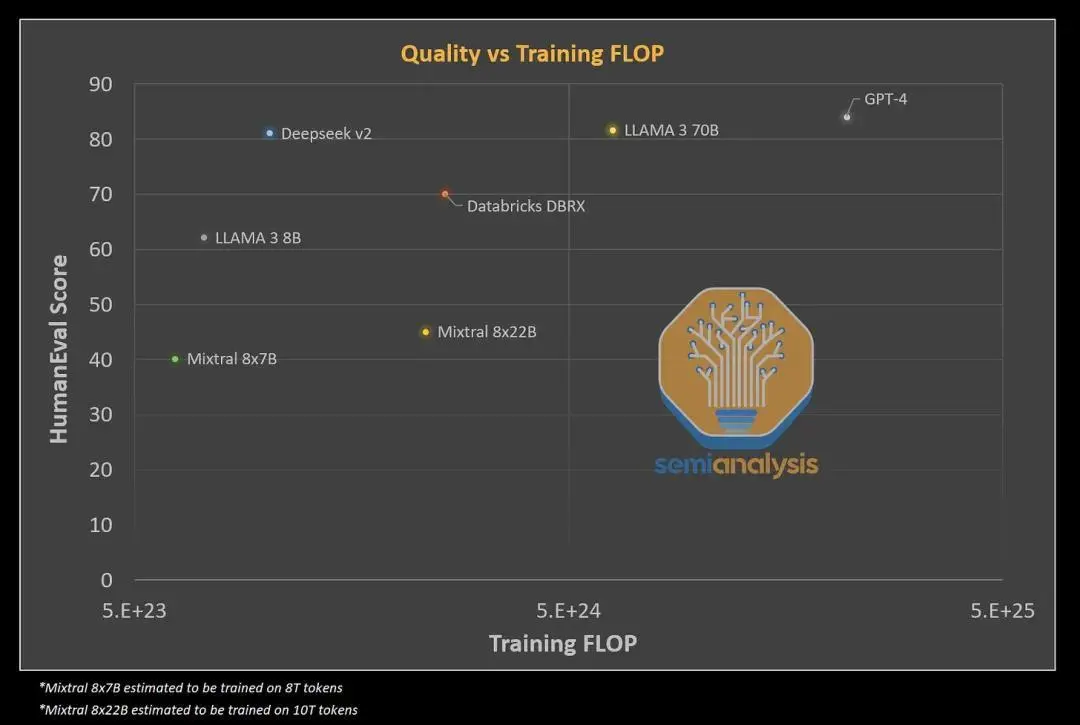
资料来源:SemiAnalysis 、ArtificalAnalysis.ai 、各种模型公告
这些结果表明中国企业现在也具有国际竞争力。此外,就共享的信息和细节而言,这篇论文可能是今年最好的一篇。
虽然国外的竞争对OpenAI来说是一个挑战,但他们最大的合作伙伴也是他们最要提防的。
02 微软靠得住吗?
微软直接为 OpenAI 投入了超过 100 亿美元的资本支出,但他们并没有将大部分 GPU 能力用于 OpenAI。微软计划每年在人工智能数据中心上花费超过 500 亿美元,其中大部分将用于内部工作负载。其中大部分都是为了在自己的产品和服务中部署 OpenAI 模型进行推理,但这种情况正在发生变化。
由于 OpenAI 的怪异结构,微软被迫寻找应急计划。OpenAI 是一家非营利组织,其主要目标是创造安全且造福全人类的通用人工智能 (AGI)。OpenAI 可以而且将会打破微软能够访问 OpenAI 模型的协议,而微软的追索权为零。
虽然与 Microsoft 的合作伙伴关系包括数十亿美元的投资,但 OpenAI 仍然是一家完全独立的公司,由 OpenAI Nonprofit 管理。微软是无投票权的董事会观察员,没有控制权。
AGI 明确地包含在所有商业和知识产权许可协议中。董事会决定何时实现 AGI。再次强调,AGI 指的是一个高度自治的系统,在最具经济价值的工作中表现优于人类。此类系统不包括在与 Microsoft 签订的 IP 许可和其他商业条款中,这些条款仅适用于 AGI 之前的技术。
对于微软来说,最令人担忧的是,OpenAI 的董事会可以在没有微软任何投票参与的情况下随时决定他们已经实现了 AGI,而微软无权获得用他们的投资创建的 IP。
当你将 OpenAI 与其非营利和营利部门相关的大量治理问题叠加起来时,微软必须制定应急计划。
丨微软计划如何减少对 OpenAI 的依赖
微软正试图将其大部分推理量从 OpenAI 的模型转移到他们直接为其开发 IP 的自己的模型上。这包括 Copilot 和 Bing 计划,它们推动了微软人工智能的发展。当 OpenAI 拥有唯一的模型时,微软当然会在他们的产品中使用它,但除此之外,他们将优先考虑自己的模型来处理大多数查询。
问题是怎么做?
虽然微软在 AI 人才方面与 OpenAI 甚至与 Meta 都没有竞争力,但他们正在迅速尝试尽快培养这些技能。对 Inflection 的伪收购使他们能够快速跳转到一个不错的模型以及坚实的预训练和基础设施团队,但要实现 OpenAI 不断变化的目标,还需要做更多的事情。
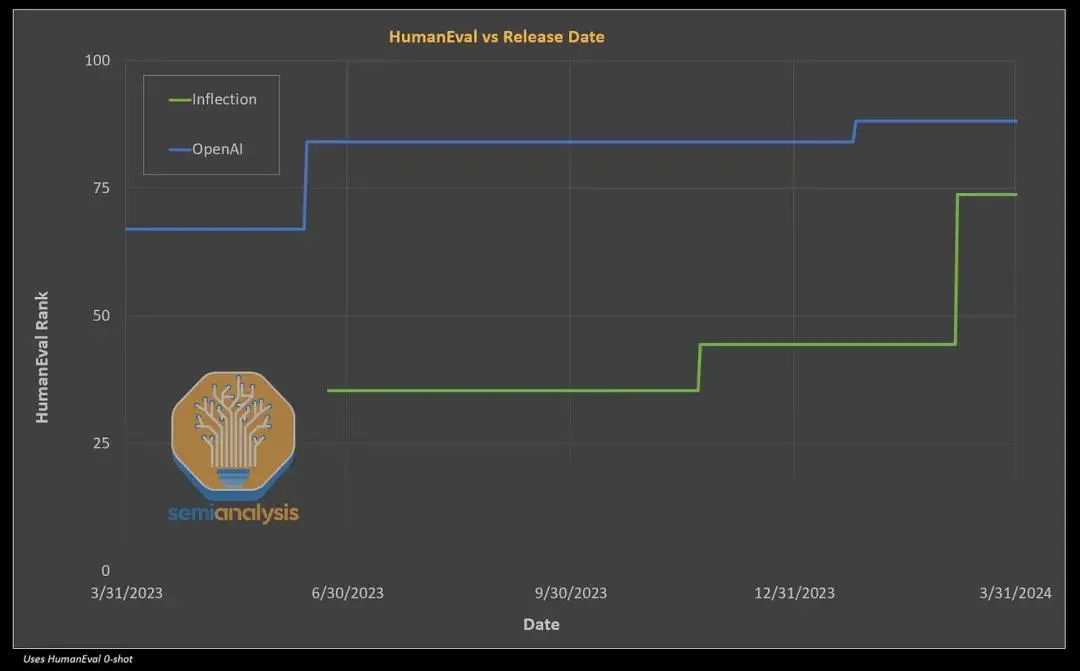
资料来源:SemiAnalysis、OpenAI、Inflection AI
微软已经拥有一些强大的团队致力于合成数据,这可以被认为是下一代模型最重要的战场之一。Microsoft Phi 模型团队因使用来自大型模型的大量合成数据来训练小型模型而闻名。最新发布的 Phi-3 模型令人印象深刻。如果目标只是稍微落后于 OpenAI,那么这个策略将会奏效。
微软的另一个团队 WizardLM 创造了更令人惊奇的东西,称为“Evol-Instruct”。它是一种基于人工智能的方法,用于为大语言模型生成大量不同的指令集。目标是提高法大语言模型遵循复杂指令的能力,而不依赖于人工创建的数据,这些数据可能昂贵、耗时且缺乏数量/多样性。
相反,数据是由人工智能创建和管理的,通过与自身的模拟聊天来递归地改进自身。人工智能将判断质量并迭代以生成更好的数据。它还利用渐进式学习来改变数据组合,从简单开始,逐渐增加训练数据的难度和复杂性,因此模型可以更有效地学习。
Microsoft 目前正在通过 MAI-1 ~500B 参数 MOE 模型进行首次达到 GPT-4 级别的重大努力。它利用 Inflection 预训练团队及其数据集与微软自己的一些合成数据相结合。目标是在本月底之前从头开始拥有自己的内部 GPT-4 级模型。
我们不确定它是否会完全击中目标,但 MAI-1 计划只是积极内部建模工作漫长道路的开始。
许多公司通过 Azure 使用 OpenAI 的技术。超过 65% 的财富 500 强企业现在使用 Azure OpenAI 服务。值得注意的是,这并不是直接通过 OpenAI 实现的。如果 Google Deepmind 或 Amazon Anthropic 仅仅通过微软推出自己的模型来获得份额,OpenAI 可能会失去大量业务。
03 分销和整合为王?
随着 DeepSeek 和 Llama 3 405B 开源,企业没有理由不托管自己的模型。扎克伯格利用开源模式减缓竞争商业采用并吸引更多人才的策略正在创造奇迹。鉴于 Databricks 在从头开始训练优于 GPT 3.5 质量的通用模型方面也非常有能力,因此微调不再是一项艰巨的任务。
OpenAI 的优势之一是他们在收集使用数据方面一直处于领先地位,但这种情况很快就会改变。这是因为 Meta 和 Google 都可以更直接地接触消费者。只有四分之一的美国人曾经尝试过 ChatGPT,而且大多数人不会继续使用它。未来大多数消费者 LLM 使用将通过现有平台、Google、Instagram、WhatsApp、Facebook、iPhone/Android。
虽然 Meta 尚未找到如何将其货币化,但他们的 Meta AI 由 Llama 3 70B 提供支持,可在 Facebook、Instagram、Whatsapp 上使用。宣布的推广已扩展到包括美国在内的 14 个国家,这些国家的人口总数为 11 亿。数量惊人的用户已经可以使用比 ChatGPT 免费模型更好的模型。Meta AI 正处于其增长曲线的早期阶段,仅实现其整个 32.4 亿每日活跃用户群的 1/3。
虽然 Llama 3 70B 可能缺乏更大、功能更强的型号的大部分功能,但它可能是适合其用户的产品市场,其中包括许多新兴市场的移动中心用户,人们会假设这种以移动为中心的用户用户可能会进行较短的一般知识查询,而不是集中于高输入令牌代理用例。Meta 的部署对 Google 搜索的伤害可能比 Bing 或 Perplexity 还要大。
为了服务 3B 人群——显然需要一个小型且高效的模型来降低推理成本。要么 Meta 已经让金融数学发挥作用,要么准备投入巨资在消费者人工智能领域抢占先机。这两种情况对现任者来说都意味着灾难。
不仅仅是 Meta 正在为战斗站集结——谷歌的用户覆盖范围与 Meta 处于同一数量级。如果谷歌与苹果达成协议,让其Gemini 模型专门在 iPhone 上提供服务,那么谷歌十多年前用来巩固其在搜索市场主导地位的策略也将适用于此。
04 算力和资本为王吗?
另一个争论是计算和资本是否为王。在这种情况下,鉴于Google 的 TPU 建设步伐异常激进,他们将成为王者。讽刺的是,谷歌现在已经有了重点,并将所有大规模培训工作都集中到一个合并的 Google Deepmind 团队中,而微软则开始失去重点,将资源转移到与 OpenAI 竞争的自己的内部模型上。
这里有一个资本问题。什么时候开始不再值得投入资金?
马克·扎克伯格
OpenAI 最大的风险之一是资本游戏。如果是这样,投资最多的科技公司就是赢家。虽然微软目前的投资最多,但并没有领先 Meta、Google 和 Amazon/Anthropic。Meta 和谷歌拥有完全的焦点,而亚马逊和微软则由于缺乏对其盟友人工智能实验室的控制而不得不束手无策。
定制芯片是另一个要点,因为与购买 Nvidia 芯片相比,它可以大大降低计算成本。微软在其云中部署的定制人工智能芯片最少,而且这种情况至少持续到 2026 年。与此同时,谷歌、Meta 和亚马逊正在不同程度地增加其内部芯片的数量,这给了他们计算成本优势。
相关内容
- 2024-12-21 OpenAI重磅发布o3!再次突破AI极限,北大校友参与研发
- 2024-12-21 12天人工智能马拉松式直播结束,一口气看完OpenAI所有要点
- 2024-12-21 OpenAI第12天:新品o3发布会的8大看点,第5个让全球都坐不住了
- 2024-12-20 GPT开山一作被曝离职OpenAI,被Ilya感谢,ChatGPT无名英雄选择单飞
- 2024-12-20 阿尔特曼暗示OpenAI明日发布o3,新一代AI推理王者模型
点击排行
- 105-17OpenAI多位重量级高管离职,质疑再次涌向Sam Altman
- 203-07ChatGPT-Plus,AI 助手全套开源解决方案,自带运营管理后台,开箱即用。
- 306-22RTranslator: 全球第一个开源实时翻译应用程序
- 410-18诺奖得主哈萨比斯最新访谈:仅仅将AI视作一种技术是错误的
- 505-17马斯克称OpenAI最新模型慢得离谱
- 606-23OpenAI CTO:GPT-5可能会在2025年底或2026年初推出
- 706-23企业家自曝用了ChatGPT后裁员近1/10:管理效率大幅提升
- 805-17GPT-4o被全球网友玩坏了 谷歌:终究是错付了
- 906-23高通开放AI模型,助力开发者打造骁龙X Elite平台智能应用
- 1005-17谷歌Gemini AI 计划为学校提供额外的数据保护和隐私