面对OpenAI的贴脸开大,谷歌原地回击:深夜推出多模态Agent
面对OpenAI的贴脸开大,谷歌选择原地回击。
今天凌晨1点(北京时间),谷歌在2024年I/O大会上放出大招——
更强的多模态Agent助手Astra,能实时理解镜头内外的世界。
多模态和长文本是本次发布的关键词,谷歌CEO桑达尔·皮查伊表示,多模态和长文本相结合,扩展了我们可以提出的问题类型,也扩展了我们可以得到的答案类型。

Gemini系列模型卷起了长文本,1.5 Pro的上下文窗口将扩展到200万个token;新发布的Flash是轻量级模型,定价每100万个token35美分,远低于GPT-4o 5美元的价格。
搭载了Gemini的谷歌家族产品也华丽升级:谷歌搜索支持输入视频提问,还将上线“AI概述”的结果页面;安卓系统手机内置AI助手,图上画个圈就能全局搜索。
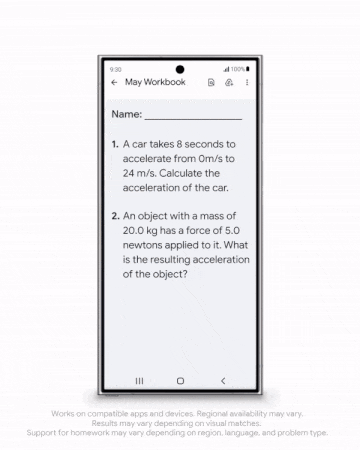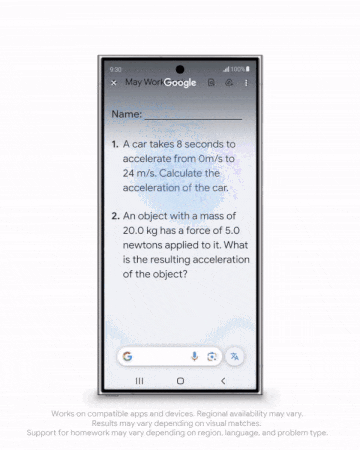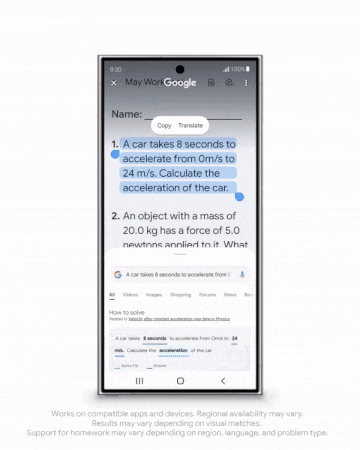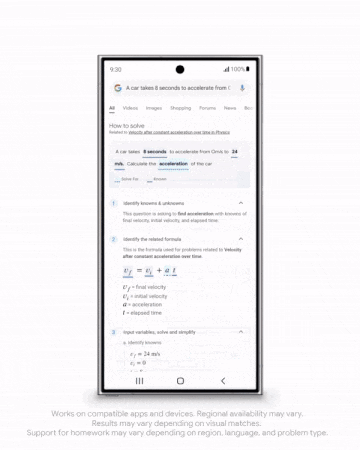
AIGC方面,更逼真的图像生成模型Imagen 3发布;全新的视频生成模型Veo剑指Sora,可生成时长超60秒的高清视频……
皮查伊称目前有20亿用户在使用Gemini,Gemini时代刚刚拉开帷幕,谷歌希望最终让AI造福每个人。
“头号AI玩家”全程围观了直播,以下是我们梳理的本次主旨演讲的要点。

多模态Agent来了,
Gemini精准打击GPT-4o
众所期待的Agent(AI智能代理)终于来了。
谷歌在I/O大会上分享了新项目Project Astra,一个不亚于GPT-4o的AI智能助手,可以像人一样了解周遭的复杂世界,在日常生活中提供实时帮助。
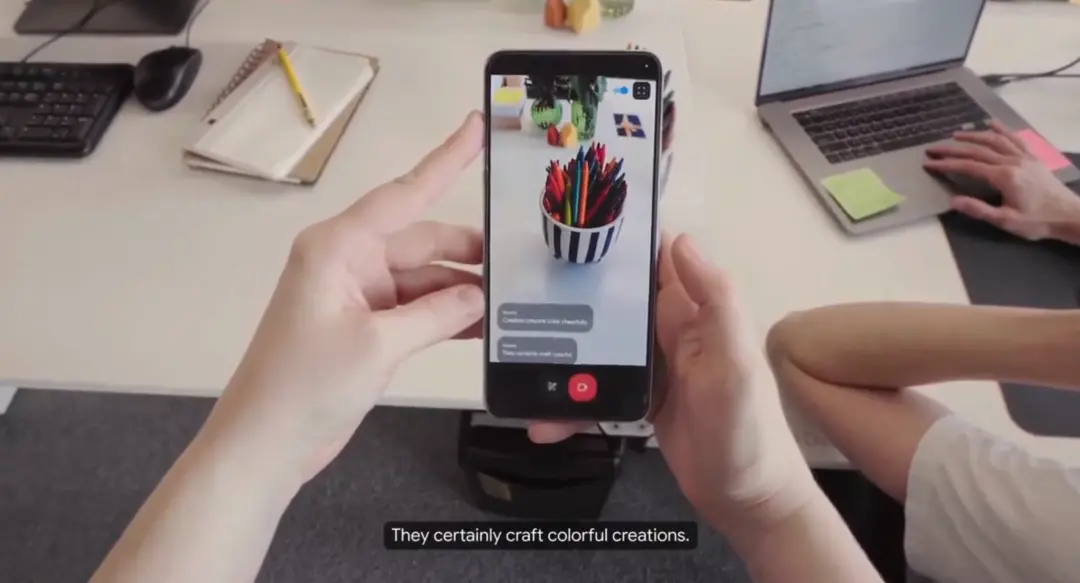
比如在办公室里开着摄像头转一圈,AI能识别出画面中的物品,解释正在写的代码,判断所在的地理位置。
演示视频中,官方还展示了如何将Astra与AR眼镜相结合,这也成为其中一个亮点。戴上眼镜后,Astra的回答会实时显示在眼前,比如帮助修改白板上的流程图时,会用箭头指出修改位置。
不过,与昨天OpenAI推出的GPT-4o相比,后者在演示中展现了更多令人惊喜的情感丰沛的互动,虽然也有即刻网友评论,“感觉OpenAI想为每个人打造自己的专属舔狗”。
此前谷歌刚发布Gemini时,其多模态交互演示视频还需要经过剪辑,如今发布的Astra视频特意强调了是“一次性实时拍摄的”。
Agent是一种智能系统,可以了解多模态信息,提前规划多个步骤,并代表用户采取行动。从演示来看,Astra延迟低、反应快、互动自然,仿佛就是身边的一个专家助理。
此外,谷歌还公布了Gemini系列模型的最新进展。
Gemini 1.5 Pro的上下文窗口将扩展到200万个token,可以处理数百页文档,并向开发人员提供私人预览版。

面向全球开发者开放的Gemini Advanced则提供长达100万token的上下文窗口,支持超过35种语言。
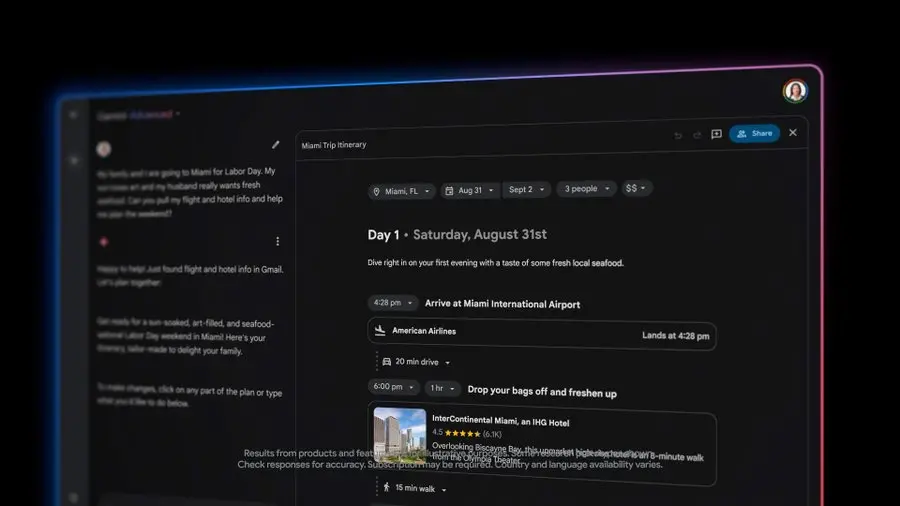
Gemini Advanced将在几周内上线新的数据分析功能,晚些时候还会增加旅行计划功能,通过高级推理创建个性化的行程。
Gemini 1.5 Flash是新推出的轻量级模型,针对低延迟和低成本任务进行了优化,可以更高效率地部署。开发人员即日起可在Google AI Studio和Vertex AI中使用,上下文窗口可达100万token。

Gemini的Gems功能将在今年夏天推出,类似于GPTs,可通过Prompt设置为不同专长的AI助理。

同时,作为原生的多模态模型,Gemini的语音和视频能力迎来升级,即将上线的“Live”功能,其逼真程度可以说是对标GPT-4o。
你能与Gemini进行更深入的双向对话,回答中可以随时打断,打开摄像头,Gemini就能看见和理解周遭发生的一切。看来AI头号玩家们的理想AI助手都有电影《Her》的影子。

新增图像视频搜索,
AI一键联网总结
随着ChatGPT、Copilot等AI产品席卷全球,用户获取信息的方式正悄然改变,本次谷歌的当家产品“谷歌搜索”率先迎来了重大升级,集成了最新的智能代理助手。
在搜索时,你可以通过视频提问,比如录一段视频问道:“为什么这个放不上去?”

Gemini能理解问题是视频中的唱片为什么不能固定在唱片机上,并迅速搜索文章、论坛、视频等全网信息,给出解决办法。
相比传统的搜索结果罗列,如今有了Gemini加持的谷歌搜索还将上线全新的搜索结果整合功能“AI概述”(AI Overviews)。
比如在现场演示中,当我们想要在波士顿找到最好的瑜伽或普拉提工作室,并在结果中显示它们的入会优惠信息,以及与住址的距离。
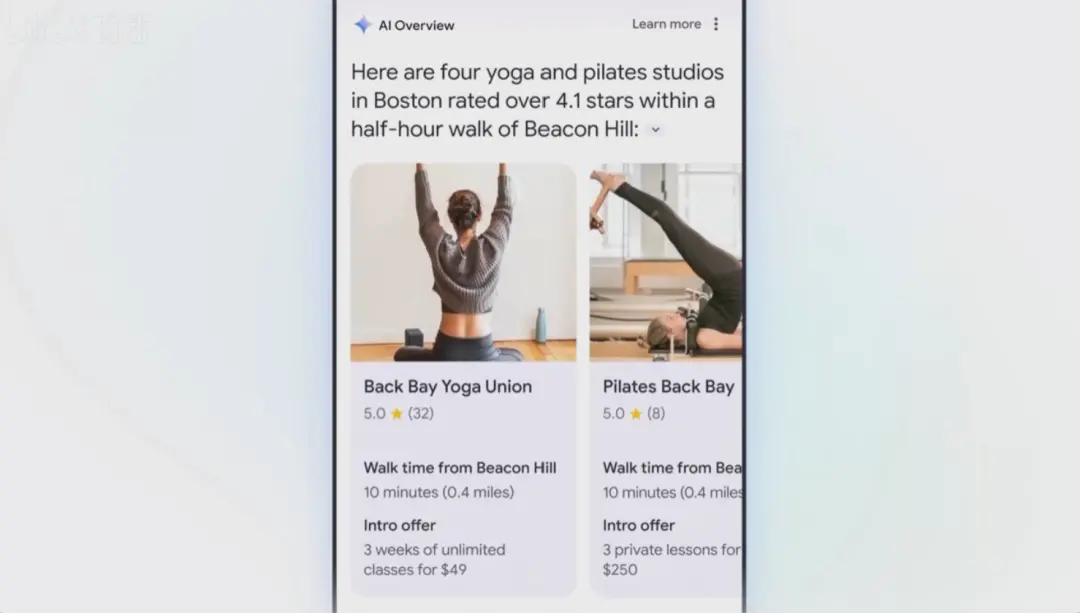
Gemini一次搜索就能获得所有信息,并组织呈现出有条理的搜索结果页面。
据介绍,谷歌搜索升级后支持多步骤推理功能,可以将大问题分解为若干部分,并找出要解决的问题以及解决的顺序,因此原本可能需要花费数分钟甚至数小时才能得出的结果,现在可以在几秒钟内完成。
“AI搜索概述”功能将在美国率先推出,未来将覆盖10亿用户。
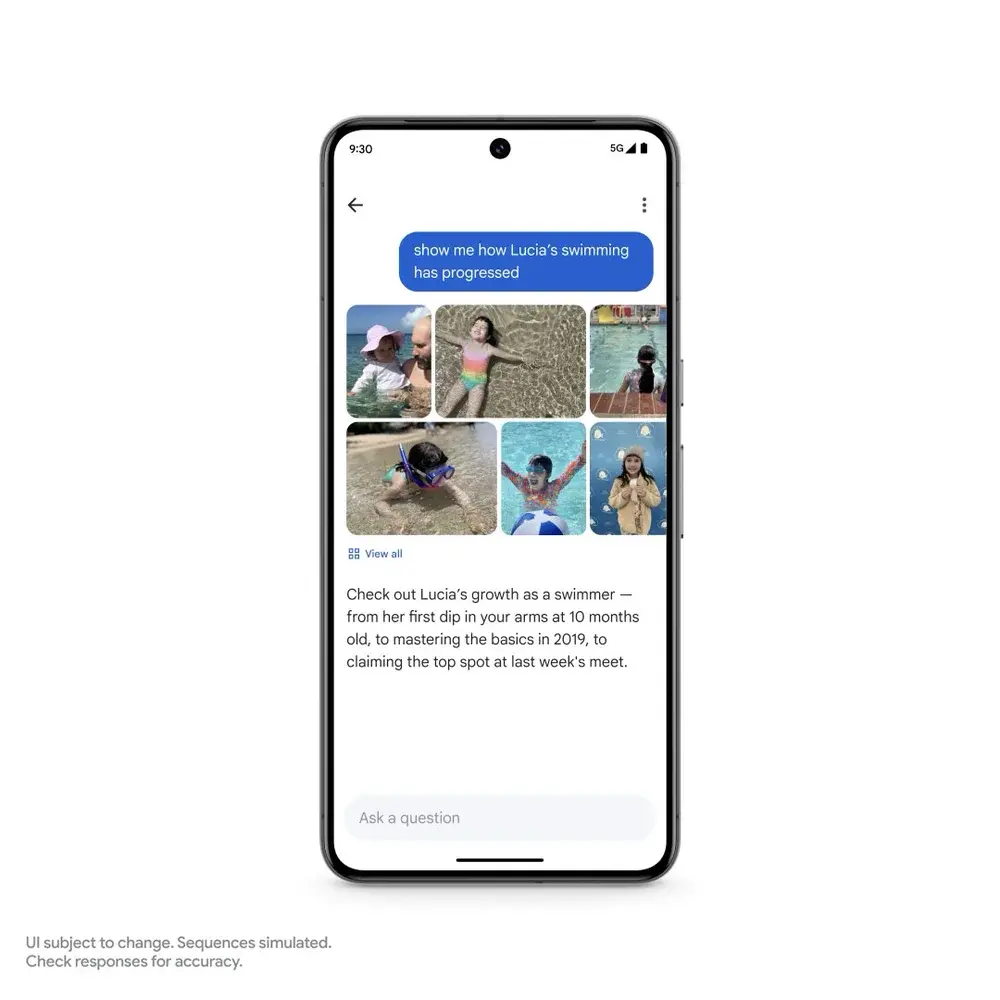
此外,在手机端,谷歌相册(Google Photos)即将推出的一项新功能“Ask Photos”。
在图片上画个圈,就能搜索指定的对象,比如搜索带有车牌号的照片,或者问问“最近女儿游泳学得怎么样”,Gemini能理解复杂的语境,轻松找到对应的照片和视频。

AIGC模型上新,
Veo可生成超60秒高清视频
在图像、音乐、视频领域,谷歌都分别都发布了新的模型或产品。
图像生成
谷歌推出了迄今为止最高质量的文本到图像生成模型Imagen 3,生成的图像细节更丰富、更真实,而且能理解复杂文本提示。

Imagen 3生成
音乐生成
谷歌和YouTube共同打造了Music AI Sandbox,这是一套专业的AI音乐创作工具,可以帮助创作者从0开始快速创作。

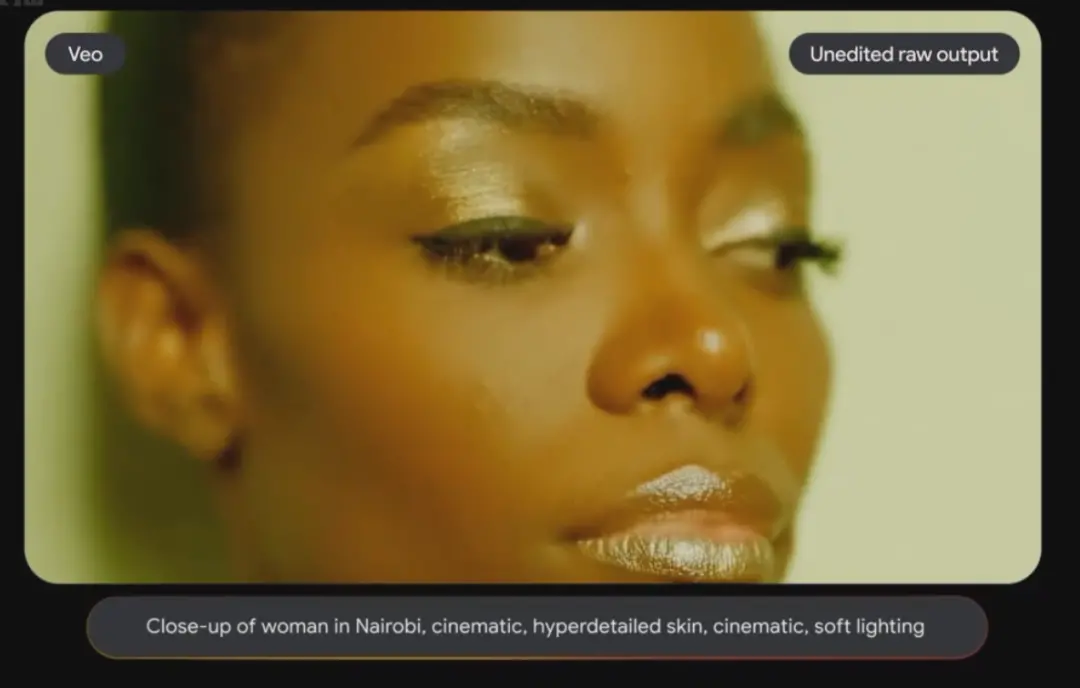
视频生成
谷歌发布了最新的视频生成模型Veo,只需一个文本、图片或视频提示,即可创建超过60秒的高质量1080p片段,支持多种电影风格,包括写实主义、超现实主义、动画等。或许未来每个人都会成为导演。
以上这些AIGC模型,目前都可以在labs.google上申请试用。

谷歌全家桶AI升级,
安卓手机抢先搭载AI助手
不出所料,升级后的Gemini 1.5 Pro将集成在更多的谷歌全家桶产品中,包括邮件、会议、文档等软件,以及手机等硬件设备。

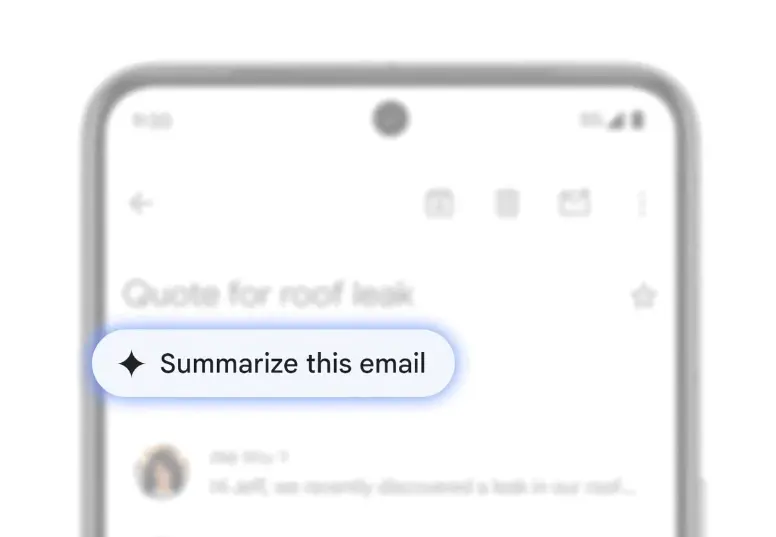
比如Gmail中的Gemini能一键总结邮件内容,自己不用去多个邮件、附件中查阅,Gemini会根据语境分析,还会给出回复建议。
向Excel中的Gemini提问,不用再费力编写公式,AI会自动进行数据分析,以图表形式给出计算结果。
对于以AI为核心的手机,谷歌提到了三个关键应用:AI驱动搜索(上文提到的图片画圈搜索),系统自带的AI助手(目前安卓系统可用),AI保护隐私和安全(提示诈骗风险)。
谷歌表示,今年晚些将拓展Gemini Nano的多模态功能,新增视觉、声音、口语输入,这意味着AI手机可以帮助更多视力障碍群体等用户更好地交流和生活。
皮查伊近日在接受《The Circuit With Emily Chang》专访时提到,在技术领域,如果你不持续创新以保持领先,那么任何公司都将不可避免地走向衰败。
自2016年起,人工智能便一直是谷歌公司的核心焦点,谷歌的研究人员发明了Transformer,也就是GPT中的T。那时,OpenAI开发的ChatGPT尚处于起步阶段。
而到了如今的生成式AI时代,谷歌却屡次被OpenAI抢了风头,同时还面临着微软等竞争对手的严峻挑战。
从今年I/O大会主旨演讲发布了这么多新模型和产品升级来看,谷歌仍在坚持AI First的战略方向,无论是搜索还是AIGC应用等,AI的前沿高地必有谷歌的位置。
相关内容
- 2024-12-18 贴身追随OpenAI的中国公司,从智谱换成了月之暗面
- 2024-12-17 谷歌发布AI图像生成新工具Whisk,支持上传多张图片以图生图
- 2024-12-17 OpenAI对细分方向发力,教育App们危矣?
- 2024-12-17 4K视频生成!Google版Sora深夜秀肌肉,再度狙击OpenAI
- 2024-12-16 月薪1万4的ChatGPT要来了!OpenAI自曝其达博士级别
点击排行
- 105-17OpenAI多位重量级高管离职,质疑再次涌向Sam Altman
- 203-07ChatGPT-Plus,AI 助手全套开源解决方案,自带运营管理后台,开箱即用。
- 306-22RTranslator: 全球第一个开源实时翻译应用程序
- 410-18诺奖得主哈萨比斯最新访谈:仅仅将AI视作一种技术是错误的
- 505-17马斯克称OpenAI最新模型慢得离谱
- 606-23OpenAI CTO:GPT-5可能会在2025年底或2026年初推出
- 706-23企业家自曝用了ChatGPT后裁员近1/10:管理效率大幅提升
- 805-17GPT-4o被全球网友玩坏了 谷歌:终究是错付了
- 906-23高通开放AI模型,助力开发者打造骁龙X Elite平台智能应用
- 1005-17谷歌Gemini AI 计划为学校提供额外的数据保护和隐私