前Meta首席工程负责人胡鲁辉:“后GPT-4”有4大发展趋势,理解物理世界才能接近AGI
如何从多模态大模型到理解物理世界,更加接近AGI?
2024中国生成式AI大会于4月18-19日在北京举行,在大会首日的主会场大模型专场上,前Meta首席工程负责人胡鲁辉老师以《从多模态大模型到理解物理世界》为题发表演讲。
胡鲁辉谈道,聚焦多模态大模型的后GPT-4时代呈现出4大趋势,一是语言大模型到多模态大模型,二是数据集成到向量数据库,三是Agent智能体到大模型操作系统,四是模型微调到Plugin(插件)平台。
他认为大模型是通向AGI靠谱的方法。在大模型的落地应用中,企业和研究机构需要面对多方面的挑战。首先是数据的标准化问题,不同来源和格式的数据需要被转化成一种统一的格式,以便于模型的训练和应用。
此外,模型的分散性和应用场景的复杂性也大大增加了开发的难度。例如,在不同的物理环境下,模型需要调整其参数以适应特定的硬件和软件条件。同时,算力成本和训练时间的长短也是制约大模型广泛应用的重要因素。
胡鲁辉预测下一个AI 2.0爆发点及落地大方向将是AI for Robotics。这一领域的发展需要模型不仅理解编程或语言处理,更要深入到物理世界的具体应用中去。这涉及对物理环境的理解和设计,需要大模型能够整合各种感知数据,进行快速的决策和学习,以应对不断变化的外部条件。这一过程中,模型的训练和应用将更加依赖于高效的算力和先进的硬件支持。
以下为胡鲁辉的演讲实录:
今天我要分享的是《从多模态大模型到理解物理世界》。大模型的快速发展加上不断的技术演变,变化很大,我希望将自己的一些实战经历分享给大家。
今天主要分享4个方面。首先从大模型的原理出发,讲一下GPT-4之后硅谷及全球有哪些重大变化;其次结合大模型和多模态的特征,分享Transformer以及我在Meta的相关工作经历;今天的重点是为什么要去理解物理世界,仅仅依靠语言大模型并不能走向通用人工智能,理解物理世界才有可能走向它;最后,结合多模态大模型和理解物理世界探讨如何接近AGI。
01
大模型开启AI 2.0时代,Meta是开源领导者
每个技术的快速发展离不开背后大量的科研创新工作,这是人工智能复兴的原因,因为其在快速发展和迭代。人工智能的重要性和意义十分突出,可以说,这次人工智能是第四次计算时代或第四次工业革命。第三次计算时代是移动互联网时代,我们正处于这个时代,根据每次的发展,第四次的规模比第三次要大,且从经济效益上来讲,对人类社会的影响力更大。
人工智能在历史上有两个拐点,AlphaGo和ChatGPT。虽然每一个拐点只代表一个产品或者技术,但其对人类的影响不仅是技术本身,如AlphaGo,不可能所有公司都做下棋产品或平台。对社会来说,第一次是利用拐点背后的技术(如CV或别的技术)开始AI 1.0时代。这一次则是基于大模型泛化涌现的能力开始AI 2.0时代。
ChatGPT发布了一年多,性能表现的排名仍比较领先。并且现在大模型训练的费用或成本越来越高,之前GPT-4训练的时候需要6000万美元左右,GPT-5可能更贵。

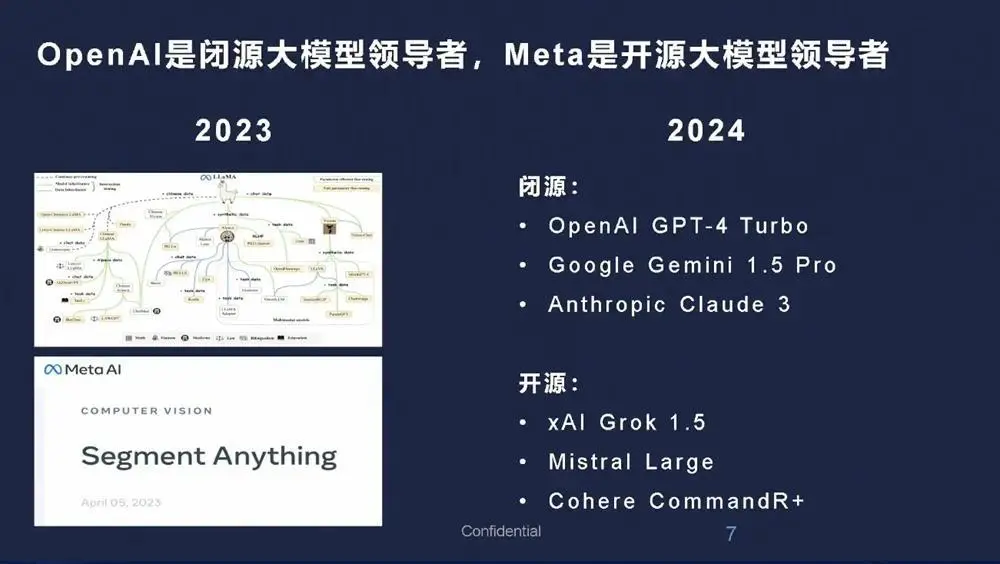
目前OpenAI是闭源大模型的领导者,Meta是开源的领导者。OpenAI在闭源大模型中的领导地位是公认的,Meta的开源大模型Llama和视觉SAM比较领先。其中Llama帮助了很多语言模型开发公司的团队,让他们拥有了很好的基础。
现在模型中,有三个闭源和三个开源比较领先。或许大家疑惑Meta的Llama怎么不见了,Meta在做另外一件更有意义的事情,就是理解物理世界,他们叫世界模型。最近Llama还没有迭代,大家可以拭目以待,这个排名还是会变化的,Llama为很多大语言模型奠定了基础,帮助很多企业飞速发展。
02.
Meta有三大SOTA视觉大模型,多模态、视觉与语言走向融合
Meta的视觉大模型还有很多贡献。Transformer最初应用于语言模型,逐步衍生到视觉,其中比较火的一个就是ViT,视觉Transformer。
Meta通过ViT或Transformer不断迭代,有三个影响比较大的视觉Transformer:一是DeTr,Detection Transformer,它有端到端的Object Detection;二是DINO,通过Transformer开启了视觉领域的自监督,无论是大语言模型还是其他大模型,都不能依赖打标签,需要它能够自主学习监督;三是SAM,更多是零样本,是泛化的能力。

在视觉领域,除了Sora,SAM影响力较大。怎么训练SAM,需要多少资源,或者训练过程中需要注意哪些事情?我去年写了一篇文章Fine-tune SAM,详细讲了怎么利用SAM做微调,如何控制资源,或者利用资源更有效地做微调。

几年前,一提到人工智能,就会想到视觉、语言两个支派,CNN、RNN基本上井水不犯河水。做NLP的一波人和做CV的那波人有各自的学术派,方法不一样,会议也不太一样。这次深度学习,语言模型从LSTM到Word2Vec,到最近的GPT还有BERT。视觉模型最早从分类到检测,再到分割,接着从语义分割到实例分割。
这里有许多地方特别相近,所谓的语言大模型无非是更深层次的一个相关性和逻辑推理。视觉也是一样,逻辑上二者是融合的,技术上是Transformer。语言层面GPT-4、 Llama比较经典;视觉中Sora和SAM都是比较经典的例子,它后面的Backbone都是基于Transformer。
无论从逻辑上讲语义相关性,还是技术上Transformer Backbone,都在逐步融合。
这是一个好消息。对研发工作者而言,以前井水不犯河水的NLP和CV终于有一天融合了。它在发生一个质的变化。
当前AI的核心技术,也是个比较靠谱的AGI方法,能从一个技术、一个方向扩展到下一阶段。但Meta首席AI科学家杨立昆反而不这么认为,JEPA从最初的Image JEPA到Video JEPA有自己的理论。但不管怎么样,从工程上或者应用上,它的效果确实突出。
打造大模型的核心关键能力是什么?一般人会说是三个核心,数据、算力、算法。而我根据一些工作经验还归纳出来另外两点。
一个是模型架构,现在的大模型和以前的深度学习算法不同的地方,就是模型架构的重要性。通过Backbone或模型架构的重塑做迁移学习或微调,不是仅仅把领域数据或者领域知识输入进去,而是通过改变模型架构产生一个新的模型,达到自己想要的领域模型。
还有一个是智能工程。Llama是开源的,OpenAI搞出来GPT-3.5,也就是ChatGPT,改变世界的奇点就发生了。有GPT-3,有数据、算力,但能不能制造出GPT-3.5?不同的公司不一样,根本原因就是智能工程不同。
这五个里面哪个最核心、最关键?很多人可能会说是算力,很贵,买不到H100、A100,但是无论是谷歌还是微软,都不会缺乏算力,他们目前却没有世界最领先的GPT-4这样的模型。
国内很喜欢说数据,没有数据的确很难搞出好的模型,但是很多大厂也不会缺数据。算法基本上是开源的,像Transformer或者一些比较新的算法也是开源的,它也不是最关键因素。而模型架构,也可以通过一些微调、不同的尝试探索出来。
所以结合国外的模型和国内的现状,最核心打造大模型的能力应该是智能工程。
这也就是说OpenAI的一些人出来创业搞Claude,刚才大家看到排名中第二领先的就是Claude,就是OpenAI中的人出来创业做的事情。说明人才是最值钱的。
03.
预测“后GPT-4”四大发展趋势,理解物理世界有七大特征
现在GPT-4是多模态大模型,在硅谷及全球人工智能发展到底有哪些趋势?我认为有四个方面,这张图是根据我的预测让GPT-4生成的图例展示。
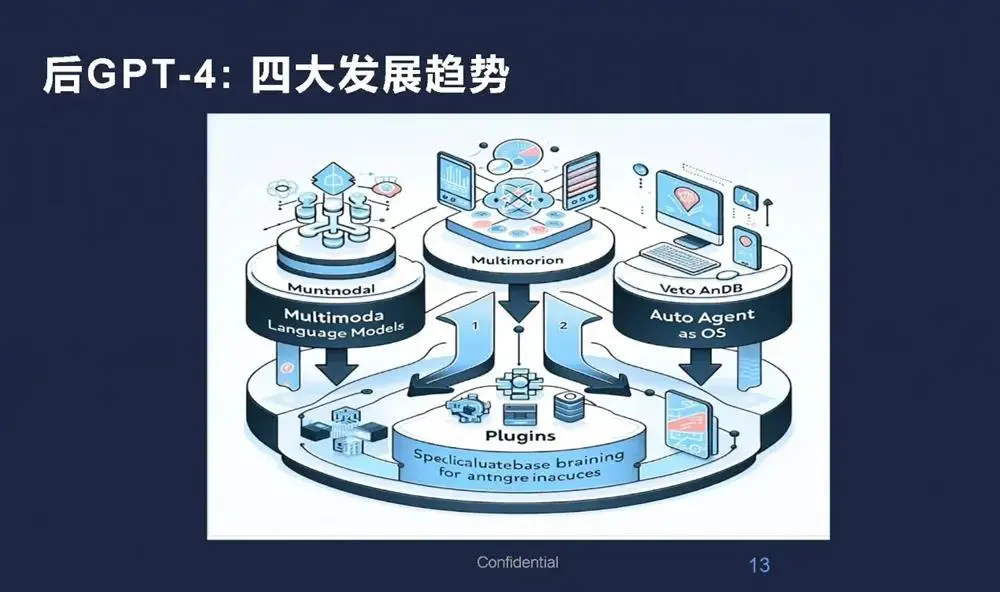
第一,从语言大模型到多模态大模型。
第二,迈向向量数据库。目前的大语言模型或多模态大模型不论多大,都有一定的局限性,导致向量数据库火起来了。大家可以把一部分或大部分的数据放在向量数据库里,把相关的数据放在大模型中。
第三,从自动Agent到将大模型作为操作系统。Agent比较火,但是它的背后依然是语言大模型或多模态大模型。Agent相当于软件自动实现。后续多模态大模型作为操作系统可能是比较核心的。
第四,开源模型从微调到引入插件平台。ChatGPT相当于一个平台,不仅可以微调,而且可以通过插件作为一个平台,因此插件可能是未来的一个方向。

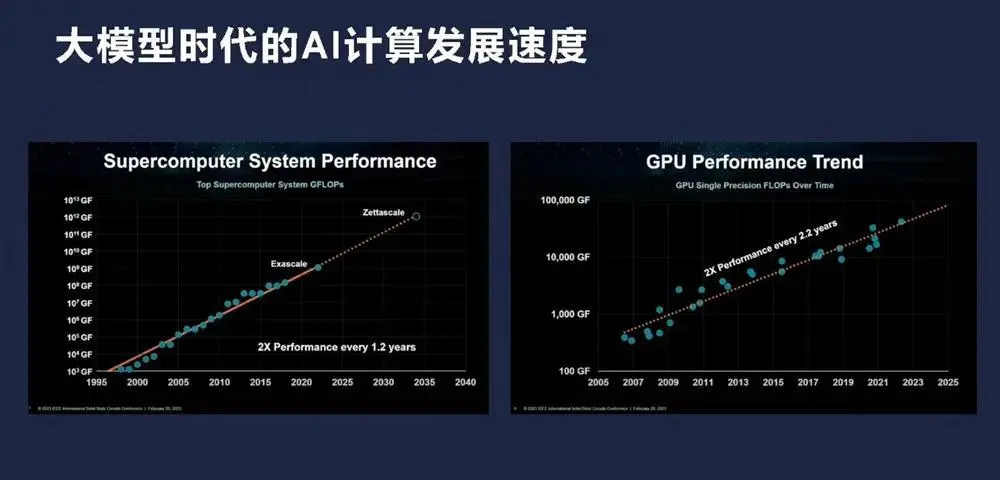
为什么模型能够这么快发展,为什么我们能够支撑Scaling Law?很大原因是计算能力的发展。CPU时代有摩尔定律,GPU时代同样发展速度更快。去年英伟达发布能够支撑1亿FLOPS的算力,今年他们发布了新的DGX GB200,去年是GH200,现在是GB200,小了一点,更快一点,但还是一个量级的。好几个DGX串起来是很大的规模,近十年之前IBM计算机也是相当大的,而现在手机就能支撑以前的算力,GPU其实也一样。
有这个大模型或算力后,应用在发生什么变化?可以看到,AI 2.0比较以前的传统软件或互联网,用户和场景可能都一样。但是以前是用户从App到服务软件再到CPU,现在是用户从多模态到基础模型,然后到GPU,中间可以依赖数据库或者训练数据,传统的用数据库,现在用向量数据库。
接下来关于理解物理世界,AI赋能了智能手机、智能车、智能家居等等,围绕的计算核心是智能云。现在或未来中心会是AI factory(人工智能工厂),它的输入是Token,文字、视觉或视频,它的输出就是AI。过去应用有手机、有车,将来就是各种机器人。未来汽车某种意义上也是一种机器人。从架构来看,AI for Robotics是一个未来方向,未来即将爆发的方向,从云计算、AI工程、基础模型,生成式AI再到上面的AI for Robotics。
理解物理世界也比较有挑战性,现在的语言模型只能局限于训练的范围中,对外界的理解还是有相当的局限性。

理解物理世界到底有哪些特征,怎么能够从现有的多模态大模型转向理解物理世界,有了理解物理世界以后再向AGI接近?我认为有七个方面,最外面的紫色是比较优秀的人,因为人的水平都不一样,作为比较优秀的人能够理解物理世界的水平。

但GPT-4或最新的GPT-4 Turbo是什么样?是里面的圈。现在GPT-4 Turbo和人还是有很大的距离,只有从每个维度提升发展,才能真正理解物理世界,更加接近地通用人工智能。
理解物理世界不仅仅是对空间的理解或者空间智能,因为从概念上 “空间”相当于3D,不包括语言等核心AI。
说到这里,大家可能觉得比较抽象,这也是Meta最近在做的一些事情。Meta在开源大模型或者开源多模态大模型方面目前显得“落后”了,但Llama 3马上来了,是因为它把很多精力花在了世界模型中,同时在治理的7个方面提高模型的能力。
我最近成立一家公司叫智澄AI,致力于通用人工智能。“澄”的意思是逐步走向真正的智能。
以上是胡鲁辉老师演讲内容的完整整理。
相关内容
- 2024-12-09 Meta推出内部AI工具,进军企业市场
- 2024-12-07 Meta今年压轴开源AI模型Llama3.3登场:700亿参数,性能比肩4050亿
- 2024-12-07 新版Llama 3 70B反超405B!Meta开卷后训练,谷歌马斯克都来抢镜
- 2024-12-05 100亿美元!扎克伯格要建Meta全球最大AI数据中心
- 2024-12-02 Nature刊文:“open”AI的实际作用非常有限
点击排行
- 105-17OpenAI多位重量级高管离职,质疑再次涌向Sam Altman
- 203-07ChatGPT-Plus,AI 助手全套开源解决方案,自带运营管理后台,开箱即用。
- 306-22RTranslator: 全球第一个开源实时翻译应用程序
- 410-18诺奖得主哈萨比斯最新访谈:仅仅将AI视作一种技术是错误的
- 505-17马斯克称OpenAI最新模型慢得离谱
- 606-23OpenAI CTO:GPT-5可能会在2025年底或2026年初推出
- 706-23企业家自曝用了ChatGPT后裁员近1/10:管理效率大幅提升
- 805-17GPT-4o被全球网友玩坏了 谷歌:终究是错付了
- 906-23高通开放AI模型,助力开发者打造骁龙X Elite平台智能应用
- 1005-17谷歌Gemini AI 计划为学校提供额外的数据保护和隐私