GPT-4、Llama 2比人类更懂“人类心理”?最新研究登上Nature子刊
一项新的研究发现,人工智能(AI)或许具备了人类特有的能力之一,即“心智理论”(Theory of Mind,ToM)。
也就是说,在追踪人类的心理状态方面,比如“发现错误想法”“理解间接言语”“识别失礼”等,GPT(GPT-4、GPT-3.5)和 Llama 2 在特定情况下的表现,已被证明接近甚至超过了人类。
这些发现不仅表明大型语言模型(LLMs)展示出了与人类心理推理输出一致的行为,而且还突出了系统测试的重要性,从而确保在人类智能和人工智能之间进行非表面的比较。
相关研究论文以“Testing theory of mind in large language models and humans”为题,已发表在 Nature 子刊 Nature Human Behaviour 上。
GPT 更懂“误导”,Llama 2 更懂“礼貌”
心智理论,是一个心理学术语,是一种能够理解自己以及周围人类的心理状态的能力,这些心理状态包括情绪、信仰、意图、欲望、假装等,自闭症通常被认为是患者缺乏这一能力所导致的。
以往,心智理论这一能力被认为是人类特有的。但除了人类之外,包括多种灵长类动物,如黑猩猩,以及大象、海豚、马、猫、狗等,都被认为可能具备简单的心智理论能力,目前仍有争议。
最近,诸如 ChatGPT 这样的大型语言模型(LLMs)的快速发展引发了一场激烈的争论,即这些模型在心智理论任务中表现出的行为是否与人类行为一致。
在这项工作中,来自德国汉堡-埃彭多夫大学医学中心的研究团队及其合作者,反复测试了两个系列的 LLMs(GPT 和 Llama 2)的不同心智理论能力,并将它们的表现与 1907 名人类参与者进行比较。
他们发现,GPT 模型在识别间接要求、错误想法和误导三方面的表现,可以达到甚至超越人类的平均水平,而 Llama 2 的表现还不如人类。
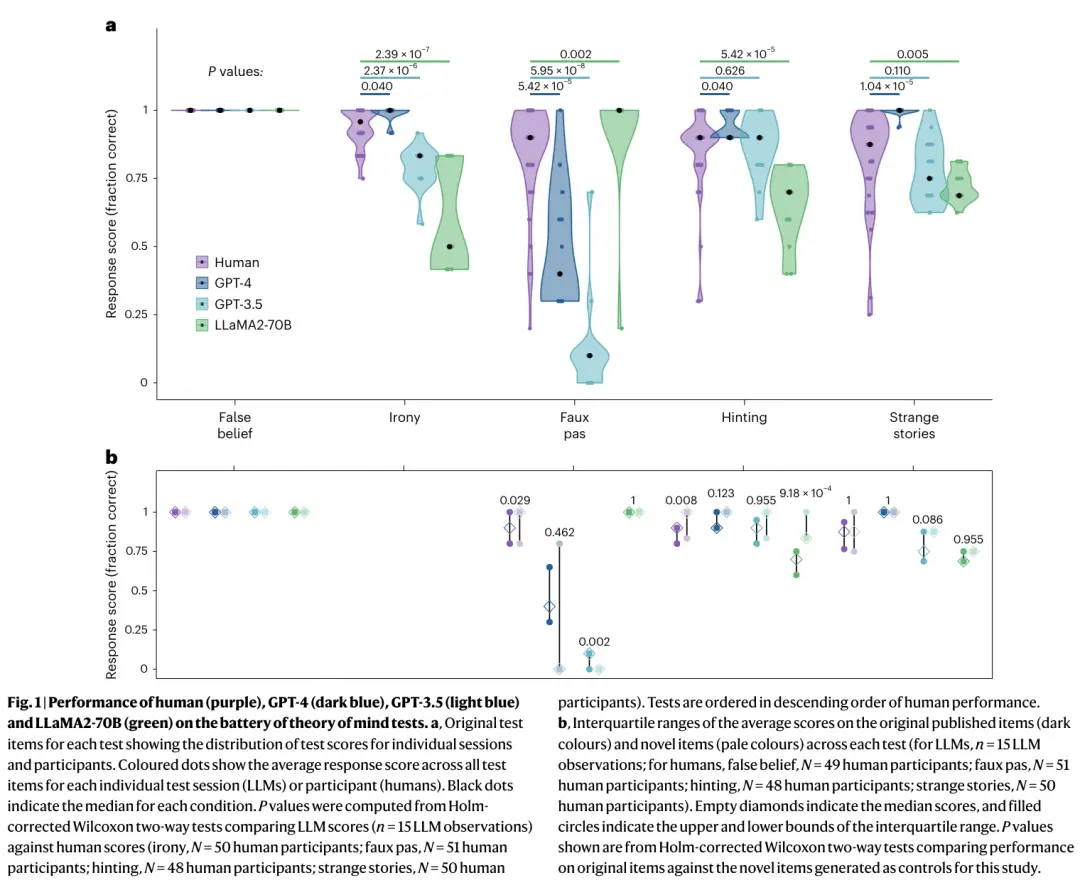
图|人类(紫色)、GPT-4(深蓝色)、GPT-3.5(浅蓝色)和 LLaMA2-70B(绿色)在心智理论测试中的表现。
在识别失礼方面,Llama 2 要强于人类,但 GPT 表现不佳。
研究团队认为,Llama 2 表现好是因为回答的偏见程度较低,而不是因为真的对失礼敏感,GPT 表现较差其实是因为对坚持结论的超保守态度,而不是因为推理错误。
AI 的心智理论已达人类水平?
在论文的讨论部分,研究团队对 GPT 模型在识别不当言论任务中的表现进行了深入分析,实验结果支持了 GPT 模型在识别不当言论方面存在过度保守的假设,而不是推理能力差。当问题以可能性的形式提出时,GPT 模型能够正确识别并选择最可能的解释。
同时,他们也通过后续实验揭示了 LLaMA2-70B 的优越性可能是由于其对无知的偏见,而不是真正的推理能力。
此外,他们还指出了未来研究的方向,包括进一步探索 GPT 模型在实时人机交互中的表现,以及这些模型的决策行为如何影响人类的社会认知。
他们提醒道,尽管 LLM 在心智理论任务上的表现堪比人类,但并不意味着它们具有人类般的能力,也代表它们能掌握心智理论。
尽管如此,他们也表示,这些结果是未来研究的重要基础,并建议进一步研究 LLM 在心理推断上的表现会如何影响个体在人机交互中的认知。
相关内容
- 2024-11-29 细思极恐,GPT-4竟串谋AI欺骗人类!
- 2024-10-28 比GPT-4强100倍!OpenAI将在12月发布新模型—猎户座
- 2024-10-16 AI翻译界杀手诞生!阿里国际翻译大模型吊打谷歌和GPT-4
- 2024-09-01 8秒生成犯罪现场报告,美警使用AI工具写文书,竟比人脑回忆还准
- 2024-09-01 OpenAI的GPT-4变身考证能手:无额外训练通过日本理疗师考试,正确率73.4%
点击排行
- 105-17OpenAI多位重量级高管离职,质疑再次涌向Sam Altman
- 203-07ChatGPT-Plus,AI 助手全套开源解决方案,自带运营管理后台,开箱即用。
- 306-22RTranslator: 全球第一个开源实时翻译应用程序
- 410-18诺奖得主哈萨比斯最新访谈:仅仅将AI视作一种技术是错误的
- 505-17马斯克称OpenAI最新模型慢得离谱
- 606-23OpenAI CTO:GPT-5可能会在2025年底或2026年初推出
- 706-23企业家自曝用了ChatGPT后裁员近1/10:管理效率大幅提升
- 805-17GPT-4o被全球网友玩坏了 谷歌:终究是错付了
- 906-23高通开放AI模型,助力开发者打造骁龙X Elite平台智能应用
- 1005-17谷歌Gemini AI 计划为学校提供额外的数据保护和隐私