微软公布SLM小语言AI模型最新成员Phi-3-vision
5 月 26 日消息,微软近日公布了旗下小语言 AI 模型家族(SLM)最新成员“Phi-3-vision”,这款模型主打“视觉能力”,能够理解图文内容,同时据称可以在移动平台上流畅高效运行。
据介绍,Phi-3-vision 是微软 Phi-3 家族首款多模态模型,该模型的文字理解能力基于 Phi-3-mini,同时也具备 Phi-3-mini 的轻量特点,能够在移动平台 / 嵌入终端中运行;该模型参数量为 42 亿,大于 Phi-3-mini(3.8B),但小于 Phi-3-small(7B),上下文长度为 128k token,训练期间为 2024 年 2 月至 4 月。

IT之家注意到,Phi-3-vision 模型的最大特色正如其名,主要支持“图文识别能力”,号称能够理解现实世界的图片含义,还能快速识别提取图片中的文字。
微软表示,Phi-3-vision 特别适合办公场合,开发人员特别优化了该模型在识别图表和方块图 (Block diagram) 方面的理解能力,据称可以利用用户输入的信息进行推论,同时还能做出一系列结论,为企业提供战略建议,号称“效果比肩大模型”。
在模型训练方面,微软声称 Phi-3-vision 是由“多种类型图片及文字数据训练而成”,包括一系列“经过严选的公开内容”,例如“教科书等级”教育材料、代码、图文标注数据、现实世界知识、图表图片、聊天格式等内容,从而确保模型输入内容的多样性。为了确保隐私,微软声称他们所使用的训练数据“可追溯”不包含任何个人信息。
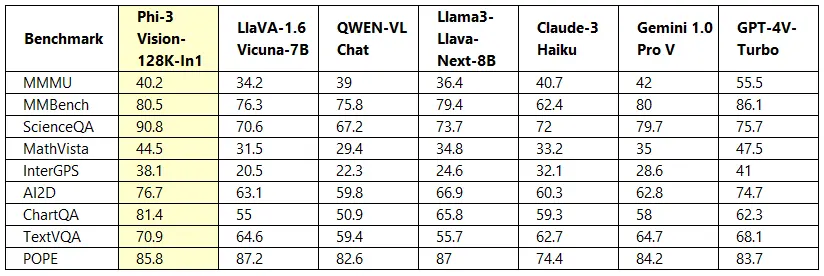
性能方面,微软提供了 Phi-3-vision 相较于字节跳动 Llama3-Llava-Next(8B)、微软研究院和威斯康星大学、哥伦比亚大学合作的 LlaVA-1.6(7B)、阿里巴巴通义千问 QWEN-VL-Chat 模型等竞品模型的比较图表,其中显示 Phi-3-vision 模型在多个项目上表现优异。
相关内容
- 2024-12-14 共建多元化AI数据生态:微软携手哈佛、OpenAI等组织,消除AI偏见
- 2024-12-06 微软邀测Copilot Vision,开启AI网页浏览新时代
- 2024-11-21 世界最大AI Agent生态系统!微软推出全新“自主AI智能体”,10万企业工作流被改变
- 2024-11-19 微软推出Copilot Actions,使用人工智能自动执行重复性任务
- 2024-11-19 微软支持的硅谷初创企业d-Matrix首款AI芯片开始出货
点击排行
- 105-17OpenAI多位重量级高管离职,质疑再次涌向Sam Altman
- 203-07ChatGPT-Plus,AI 助手全套开源解决方案,自带运营管理后台,开箱即用。
- 306-22RTranslator: 全球第一个开源实时翻译应用程序
- 410-18诺奖得主哈萨比斯最新访谈:仅仅将AI视作一种技术是错误的
- 505-17马斯克称OpenAI最新模型慢得离谱
- 606-23OpenAI CTO:GPT-5可能会在2025年底或2026年初推出
- 706-23企业家自曝用了ChatGPT后裁员近1/10:管理效率大幅提升
- 805-17GPT-4o被全球网友玩坏了 谷歌:终究是错付了
- 906-23高通开放AI模型,助力开发者打造骁龙X Elite平台智能应用
- 1005-17谷歌Gemini AI 计划为学校提供额外的数据保护和隐私