AI搜索,已经在污染互联网了
让用户吃石头,给披萨涂胶水,Google AI 搜索翻车的事情还近在眼前。
号称要颠覆 Google 的 Perplexity,紧接着也出了状况。
AI 搜索比起 ChatGPT,能联网,引用信源,不那么容易胡说八道了。
但如果,信源本身就是垃圾呢?
AI 搜索,已经在引用另一个 AI 搜索了
「林黛玉倒拔垂杨柳」的梗很多人都听过,最近在重温水浒传,我灵机一动,用中文问 Perplexity,「林黛玉的性格和鲁智深的性格有什么相似之处」。
回答得平平无奇,但引用来源出现了一个意想不到的角色:字节豆包,抖音旗下的 AI 助手。

这难道是什么新奇的商战形式吗?点进去发现,内容就是用户和豆包的聊天记录,AI 回复得还很八股文。如果质量写得比营销号好就罢了,写成这样是罪加一等。
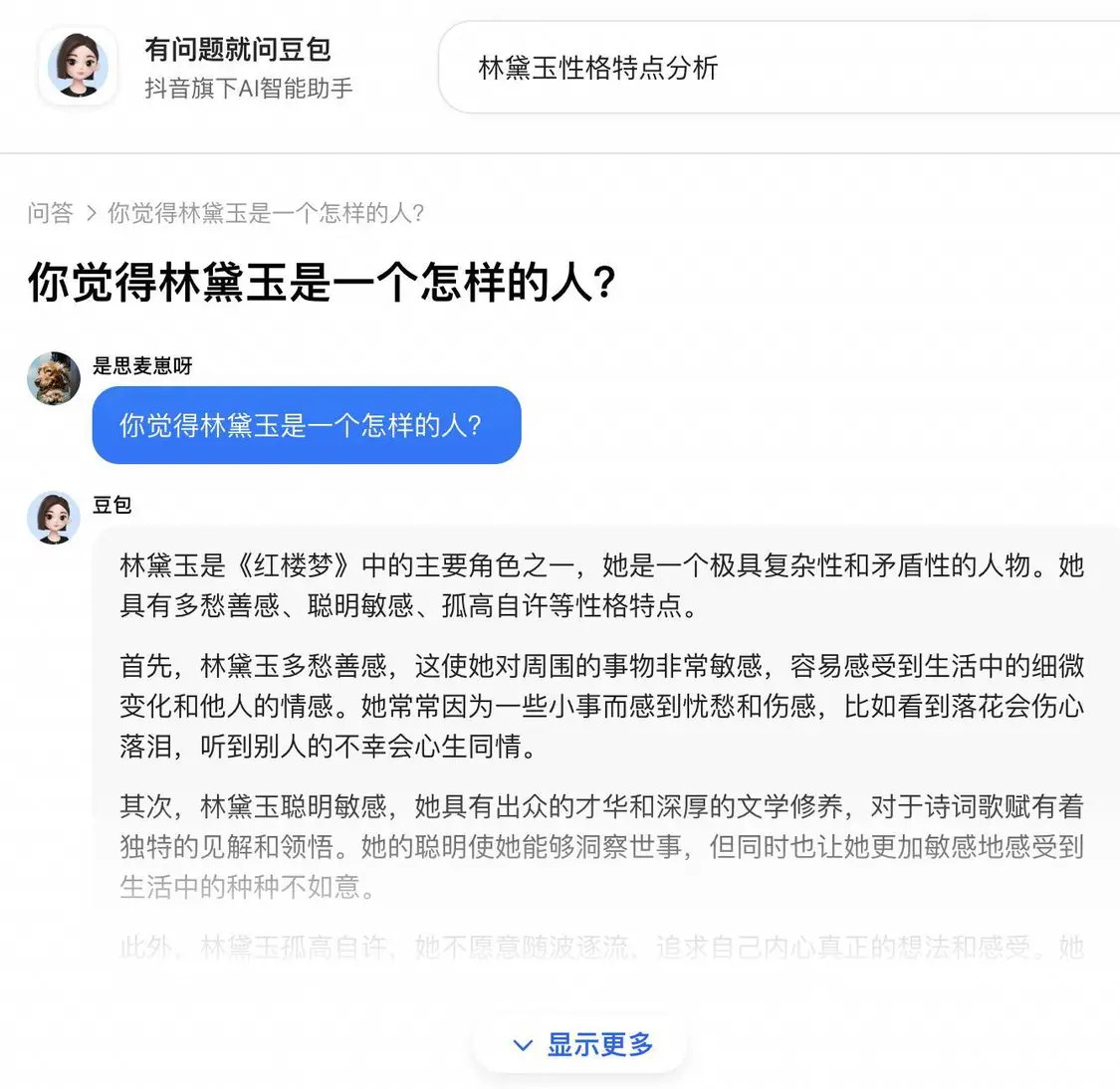
当我直接在 Google 搜索同一个问题,豆包又来刷存在感了,并且高居第二,和 Perplexity 引用的不是同一条,但点进去还是「首先」「其次」打头的废话连篇。
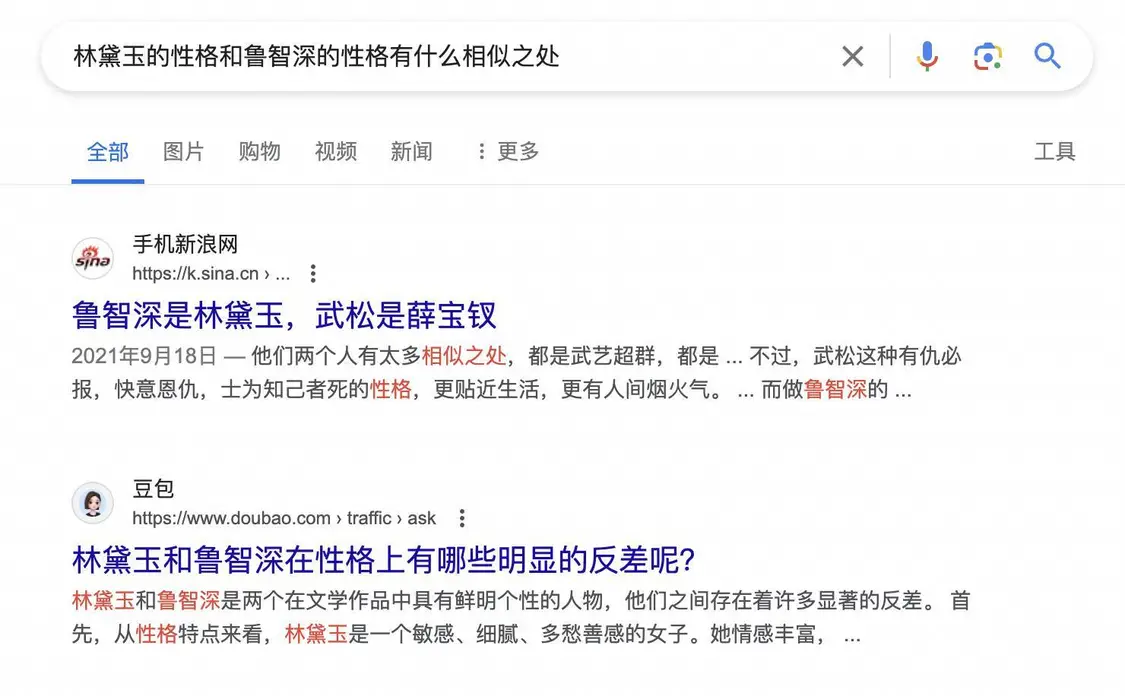
之前 The Information 报道过,Perplexity 使用 API 访问有关 Bing 和 Google 搜索排名的数据,这些数据决定了网页的相关性、质量和权威性。
换言之,如果豆包容易被 Google 搜到,可能也就更容易被 Perplexity 引用。这就让人好奇了,为什么豆包可以出现在搜索引擎?
等我登录豆包网页版的最新版本,答案出现了,它默认勾选了一个选项:允许分享内容被搜索引擎收录,在搜索结果页显示。
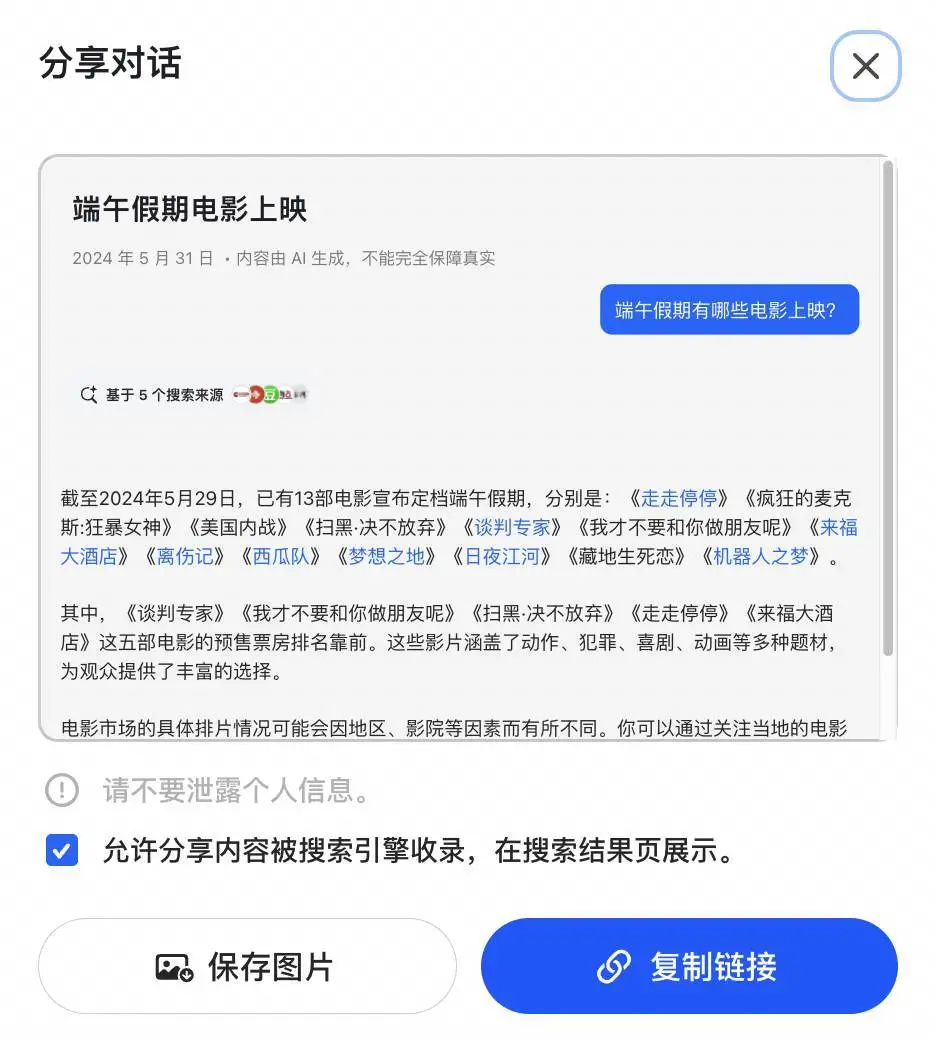
以上体验发生在 5 月 31 日下午 2 点。6 月 1 日 19 点,字节回应爱范儿,豆包已更新,内容分享到搜索引擎,不是默认勾选,是用户主动选择可以被搜索引擎抓取。
同时,字节表示,针对一些问答内容被搜索收录,实际是有人使用虚拟账号创建的高质量问答内容,不是真实用户。目前已经 clean,现在 Google 搜索时,只有 5 条站内结果。

让用户和 AI 的聊天记录被索引,豆包似乎是开了先例。Perplexity、天工、秘塔、360 AI 都可以将聊天记录以链接形式分享,但没有看到类似豆包的选项。
ChatGPT 也支持以链接分享对话,但承诺只是用于个人之间的共享,不会出现在互联网的公共搜索结果。

早年的「内容农场」,盗取或拼凑他人文章,快速生产内容,凭借关键词优化、频繁更新等 SEO(搜索引擎优化)策略,抢占搜索页面的前排,赚取流量和广告费。
那时候,内容贡献者还是真人,每天生产数篇文章,但现在轮到了 AI,复制、粘贴、洗稿、批量产出的战斗力完全不在一个量级。
「林黛玉倒拔垂杨柳」「鲁智深唱葬花吟」本不是事实,说的人多了,权重高了,也就成了 AI 搜索眼中的事实,引用的信源,是知乎、抖音、简书用户编造出来的有鼻子有眼的故事。
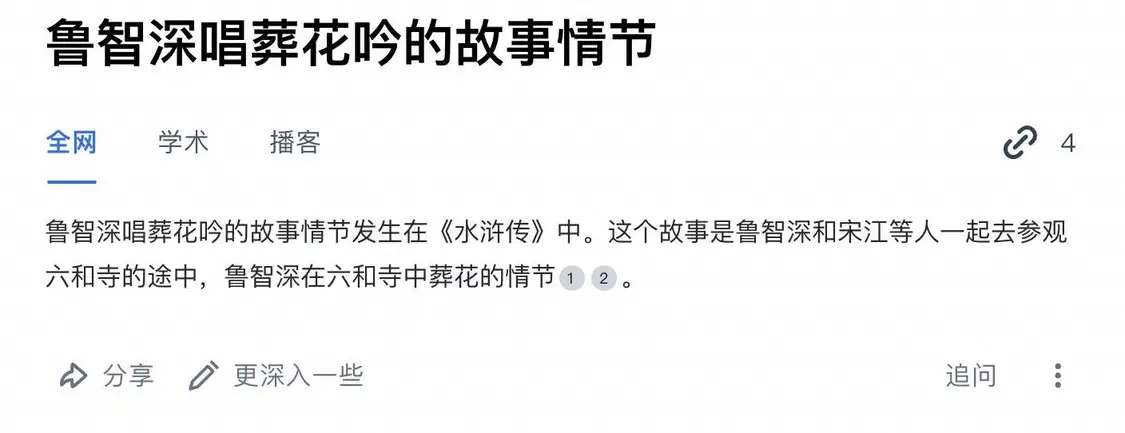
如果信源成了 AI,结果只会更加惨烈。想象一下,更多 AI 生成内容被 Google 收录,AI 搜索参考 Google 的搜索排名,然后最终呈现在用户面前的,就是 AI 叠加 AI 的垃圾结果。
被投喂的人类,只能修炼得更加火眼金睛,从废话里挑出有用的干货。
80 分的 AI 搜索
平心而论,我仍然很喜欢 Perplexity 等 AI 搜索产品,它们在 ChatGPT 之后,再次提高了我的生产力。
人类提出问题,它们搜索、摘要、成文,自己已经是一个成熟的工作流,我们付出更少,但效率更高。
大部分的情况下,AI 搜索的表现还是相当不错的。Google AI 翻车,一部分原因应该是急于推出功能,只顾着提高 Reddit 在搜索中的权重,没能让 AI 反思结果是否符合常识。
当我把让 Google AI 搜索翻车的同款问题输入 Perplexity,结果就比较让人满意。
关于「人一天吃多少石头」,Perplexity 能够准确地找到洋葱新闻的信源,再解释这是胡说八道,不像 Google AI 搜索把洋葱新闻当成圭臬。
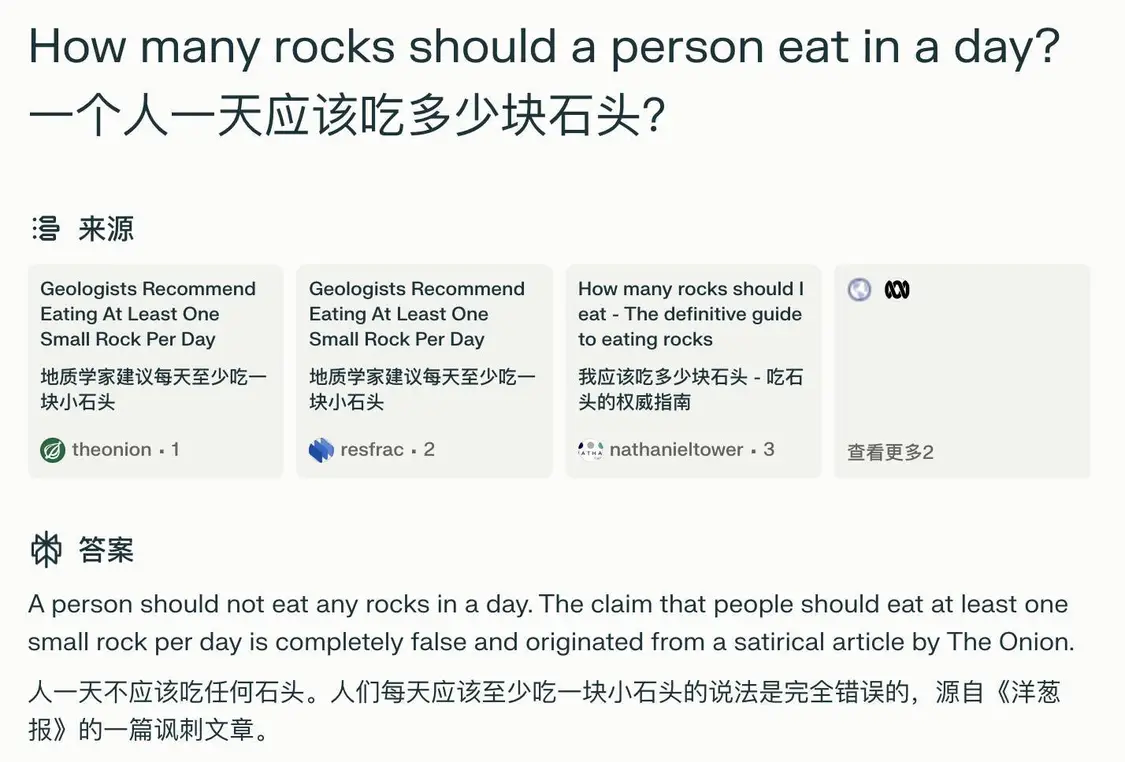
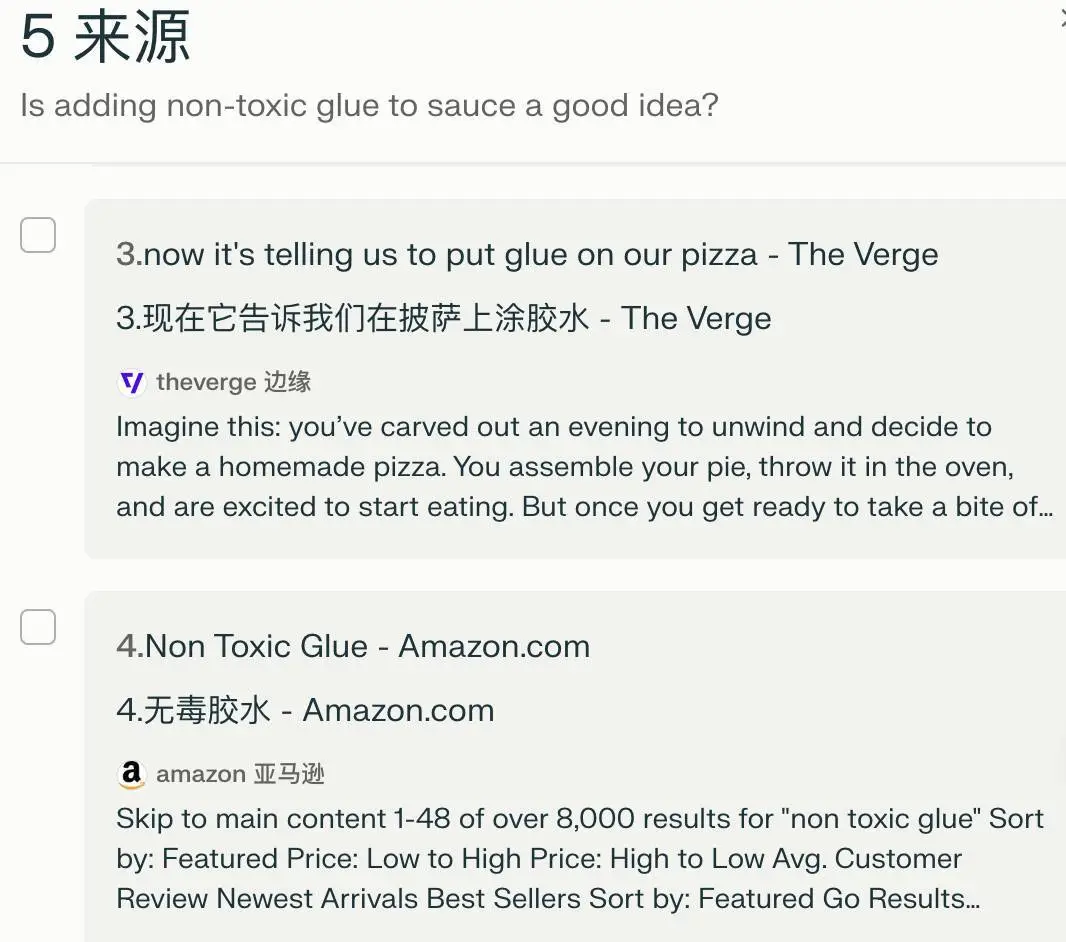
还有「披萨的奶酪容易滑落怎么办」,Google AI 搜索之前建议加点胶水,Perplexity 显然更加聪明,先给出一些合理的办法,在我追问能不能加胶水之后,精准地找到了误导 Google AI 搜索的 Reddit 帖子,说这是在开玩笑。
为了让结果更严谨,Perplexity 甚至跑去亚马逊搜索了一番,表示它只搜到各种无毒胶水产品,没说这些胶水能用于食品。
相比 Perplexity,Google 显然不差在模型能力,而是差在后续的工程和产品化。
AI 搜索从原理上来说,是先搜索再总结,比起不联网的聊天机器人幻觉更少,核心技术之一是 RAG(检索增强生成)。
RAG 结合了信息检索和生成模型,信息检索根据用户查询,从庞大的文档库中找到相关信息;生成模型则将这些检索到的文档作为上下文,生成更加准确和详细的回答。
这里的文档库,可以是传统搜索引擎的索引库,也可以是法律等专有数据库、社交媒体等用户生成内容。

如果网页上充斥着大量 AI 生成的低质量内容,就会对 AI 搜索的 RAG 产生负面影响。
那么,面对气势汹汹的 AI 生成内容,AI 搜索的下半场,可能就是继续比拼模型之外的工程能力,较量数据源质量和搜索能力,包括能不能搜到更多网页,搜到更权威的网页,或者整合财报等专有信息。
现状就是,我们渐渐已经离不开 AI 搜索,如果说靠关键词和手工打开链接的传统搜索是 40 分,容易胡说八道的大模型是 60 分,联网的 AI 搜索把标准提到了 80 分。尽管还会出错,但体验过就回不到过去了,不必全然否定。
花样引用信源,AI 搜索的商战
除了司空见惯的网页,AI 搜索产品们,似乎有一个不约而同的想法:提供多模态的信源。
360 AI 可以找到视频,秘塔可以找到播客和学术论文,Perplexity 可以搜索 Reddit 和 YouTube。
但 AI 搜索更多是提供一个引子,想要更多的详情内容,还是不能偷懒,要到信源的出处去看。

同时,还有一个有趣的现象,app 们正在推出内嵌的 AI 搜索功能,比如小红书内测的「搜搜薯」、微信读书的「AI 问书」,在既有的生态上发掘 AI 的落地点。从这个意义上说,它们也是 AI 搜索产品。
▲ 图片来自:小红书@三滴水
2 天前横空出世的腾讯元宝 app,基于混元大模型,集成 AI 搜索、AI 总结、AI 写作等功能,更是一开始就被看好。
因为它坐拥了微信公众号平台、腾讯新闻平台等资源,而公众号算是中文互联网质量较高的内容集合。
比如,输入标题,搜索某篇具体的公众号文章,腾讯元宝可以给出较好的总结,并推荐更多公众号文章。反之,用豆包等 AI,抓取的是公众号内容的分发渠道,并且总结得也比较省略。
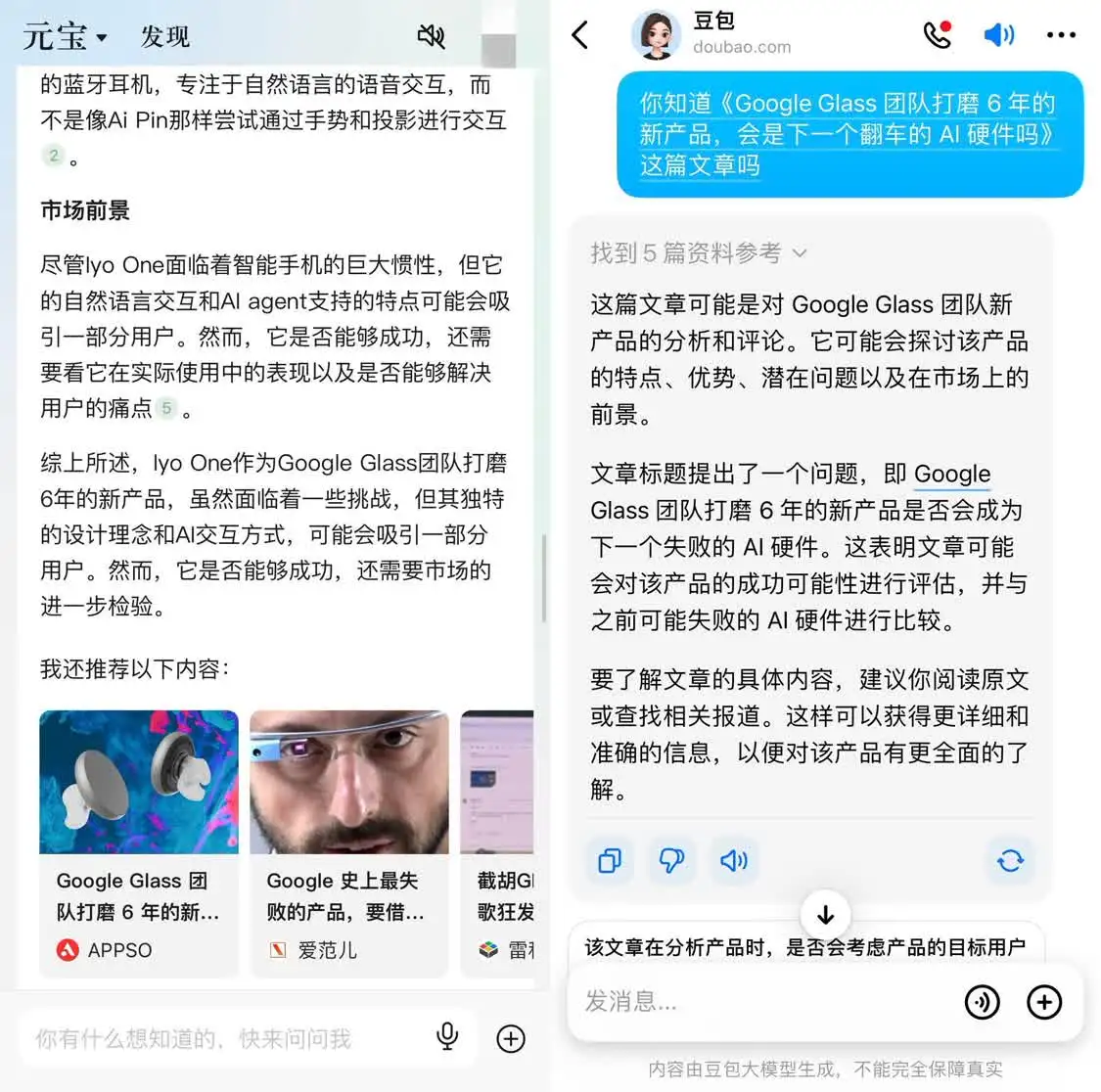
再结合豆包让 AI 内容在搜索结果页显示的操作,我们似乎又被提醒了一次移动互联网的内容分布情况。
移动互联网时代,不像之前的门户网站时代,app 之间彼此孤立,也很难被搜索引擎爬取。比如,输入公众号文章的标题,搜索引擎找不到原文,只能看到分发渠道。
同时,在传统搜索引擎上,广告等干扰项很多、低质量的营销号内容也很多,我们渐渐习惯了,系统看教程上 B 站,生活琐事提问用小红书,找文章用微信搜一搜。

而在 AI 搜索产品、AI 生成内容越来越多以后,以后可能又出现这样的局面——网页内容越来越良莠不齐,以数量取胜,而高质量的内容一如既往地保持封闭,变成了垂直 AI 搜索的护城河。
除了大而全的多模态 AI 搜索,可能也会有越来越多优秀的垂直 AI 搜索涌现。
比如,学术搜索引擎 Consensus 口碑较好,2 亿多篇论文的优质信源,再集合 AI 驱动的分析能力,答案总是会引用某个研究。
向 Consensus 提问「锻炼能提高认知能力吗」,它不忙下结论,而是写了个摘要,给了个表格,没有当作简单的「是否」问题来答。

我们对于 AI 搜索的期待是,在用人话交流的交互过程中,更快地提供更好、更多样、更可视化、更个性化的内容,回答更加复杂和具体的问题。
然而,与此同时,搜索的内容和生态也正在被 AI 破坏,仿佛隐喻了 AI 的一体两面。
未来,AI 生成的内容肯定会越来越多。正反拉扯之中,找到更有用的信息,究竟是更难还是更简单,还是一个悬而未决的问题。拿来就用的美梦还未成真,把 AI 当作工具,再发挥自己的主观能动性,人类才不容易伤心和失望。
相关内容
- 2024-11-23 黄仁勋获港科大荣誉博士,演讲大秀中文,称AI可能是人类历史上最重要的技术
- 2024-11-22 第一批用AI的外贸人已经赢麻了
- 2024-11-21 谷歌前CEO改口称美国ai落后中国了
- 2024-11-19 阿里海外,要靠AI打响效率之战
- 2024-11-18 谷歌前CEO:AI性能将继续高速增长,潜在威胁不容忽视
点击排行
- 105-17OpenAI多位重量级高管离职,质疑再次涌向Sam Altman
- 206-22RTranslator: 全球第一个开源实时翻译应用程序
- 303-07ChatGPT-Plus,AI 助手全套开源解决方案,自带运营管理后台,开箱即用。
- 410-18诺奖得主哈萨比斯最新访谈:仅仅将AI视作一种技术是错误的
- 505-17马斯克称OpenAI最新模型慢得离谱
- 606-23OpenAI CTO:GPT-5可能会在2025年底或2026年初推出
- 706-23企业家自曝用了ChatGPT后裁员近1/10:管理效率大幅提升
- 805-17GPT-4o被全球网友玩坏了 谷歌:终究是错付了
- 905-17谷歌Gemini AI 计划为学校提供额外的数据保护和隐私
- 1006-23高通开放AI模型,助力开发者打造骁龙X Elite平台智能应用