智谱AI发布视频生成工具“清影”:30秒快速生成,免费开放体验
7 月 26 日消息,智谱 AI 今日宣布,对视频生成模型进行全新升级,并正式推出新一代产品 ——CogVideoX。

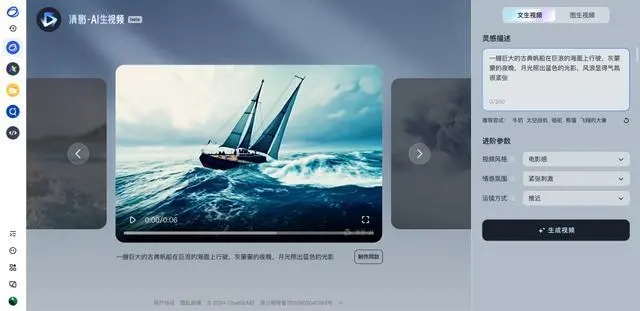
CogVideoX 模型目前已在智谱清言的 PC 端、移动应用端以及小程序端正式上线。所有 C 端用户均可通过智谱清言的 AI 视频生成功能「清影」(Ying),免费体验 AI 文本生成视频和图像生成视频的服务。
据介绍,CogVideoX 的核心技术特点如下:
针对内容连贯性问题,智谱 AI 自主研发了一套高效的三维变分自编码器结构(3D VAE)。该结构能够将原始视频数据压缩至原始大小的 2%,降低了视频扩散生成模型的训练成本和难度。结合 3D RoPE 位置编码模块,该技术提升了在时间维度上对帧间关系的捕捉能力,从而建立了视频中的长期依赖关系。
在可控性方面,智谱 AI 打造了一款端到端的视频理解模型,该模型能够为大量视频数据生成描述。这一创新增强了模型对文本的理解和对指令的遵循能力,确保生成的视频更加符合用户的输入需求,并能够处理超长且复杂的 prompt 指令。
模型采纳了一种将文本、时间、空间三维一体融合的 transformer 架构。该架构摒弃了传统的 cross attention 模块,设计了 Expert Block 以实现文本与视频两种不同模态空间的对齐,并通过 Full Attention 机制优化模态间的交互效果。
「清影」的主要特点如下:
快速生成:仅需 30 秒即可完成 6 秒视频的生成。
高效的指令遵循能力:即使是复杂的 prompt,清影也能准确理解并执行。
内容连贯性:生成的视频能够较好地还原物理世界中的运动过程。
画面调度灵活性:例如,镜头能够流畅地跟随画面中的三只狗狗移动。
此外,智谱大模型开放平台 bigmodel.cn 也部署了「清影」。企业和开发者可通过 API 调用式,体验并使用「清影」的文本生成视频和图像生成视频功能。
相关内容
- 2024-12-18 2024年十大科技进步,除了AI还有这九个
- 2024-12-18 AI端侧爆发,桌面机器人迎量产!产业链上市公司加码“抢鲜”
- 2024-12-17 AI“入侵”生物医药史:从暴力破解到Transformer模型三部曲
- 2024-12-15 华为AI,大消息
- 2024-12-15 张燕生:在中美AI技术能力竞争中,中国优势在于大市场以及三大能力
点击排行
- 105-17OpenAI多位重量级高管离职,质疑再次涌向Sam Altman
- 203-07ChatGPT-Plus,AI 助手全套开源解决方案,自带运营管理后台,开箱即用。
- 306-22RTranslator: 全球第一个开源实时翻译应用程序
- 410-18诺奖得主哈萨比斯最新访谈:仅仅将AI视作一种技术是错误的
- 505-17马斯克称OpenAI最新模型慢得离谱
- 606-23OpenAI CTO:GPT-5可能会在2025年底或2026年初推出
- 706-23企业家自曝用了ChatGPT后裁员近1/10:管理效率大幅提升
- 805-17GPT-4o被全球网友玩坏了 谷歌:终究是错付了
- 906-23高通开放AI模型,助力开发者打造骁龙X Elite平台智能应用
- 1005-17谷歌Gemini AI 计划为学校提供额外的数据保护和隐私