大模型开闭源之争,争的是什么?
今年以来,中美两国AI(人工智能)产业的企业家、投资者、创业者同时掀起了一场争论:大模型到底应该开源,还是应该闭源。
在中国,争论的焦点人物是百度创始人李彦宏。今年4月他公开表示,“大家以前用开源觉得开源便宜,其实在大模型场景下,开源是最贵的。开源模型会越来越落后。”这一观点不乏反对声音。反对者包括阿里云CTO(首席技术官)周靖人、百川智能CEO(首席执行官)王小川、猎豹移动CEO傅盛。今年5月周靖人在一次媒体群访中直言,“开源对全球技术及生态的贡献毋庸置疑。这在全球范围内被多次证明,已经没有再讨论的必要。”
在美国,争论更激烈。特斯拉创始人马斯克一度起诉AI创业公司OpenAI。马斯克2015年曾是OpenAI主要创始人、投资人之一。他认为,现任CEO奥特曼领导的OpenAI违背了“以非营利组织运作,要让AI开源开放”的承诺。硅谷两位著名投资者,a16z创始人安德里森、凯鹏华盈创始人柯斯拉在社交媒体多轮交锋。前者认为闭源模型会导致巨头垄断,破坏学术研究。后者认为大模型是经济武器,不应该开源。

开源,是一种软件开发模式——源代码免费公布,靠社区捐赠存活。开发者可以自由下载、修改、分发,反馈软件Bug(软件缺陷或错误),提出优化建议。这种集体创新会加速软件迭代。开源模型,指可免费使用,公布了模型参数等技术细节的模型;闭源模型,指要付费且未公布技术细节的模型。简单理解,开源约等于免费,但要自己买菜做饭;闭源约等于付费,相当于去餐厅吃饭,能有更好的服务。
大模型到底应该开源,还是应该闭源?这其中掺杂了商业利益、技术观点等因素,以至于很多事实被混淆了——但这场争论背后有几个确定的事实。
其一,不同的商业策略,让企业选择了不同的技术路线。百度、OpenAI等希望大模型业务快速商业化的企业,选择了闭源;阿里云、Meta等靠云计算或广告业务盈利的企业,选择开源做大蛋糕。
其二,开源、闭源两种市场需求会长期共存,无法简单判断孰优孰劣。开源、闭源模型有各自的适用场景,选择哪种模型和市场需求有关。这不会随模型厂商的意志而变化。
其三,开源模型、开源软件有本质区别。开源软件公布了源代码和大部分技术细节。开源模型更像一个免费的技术黑箱——开放了模型参数,但很少开放源代码、训练数据、训练过程等技术细节。
另外,中国AI产业的开闭源之争,更多是商业竞争。开源无国界,这个理念已经被普遍认同。但在中美AI产业博弈加剧的背景下,美国产业界反对开源的声音越来越大。

谁在开源,谁在闭源?
大模型发展尚处早期,仍需探索试错。开源、闭源并非泾渭分明。企业面对开源、闭源的选择题时,走出了三条不同的路。
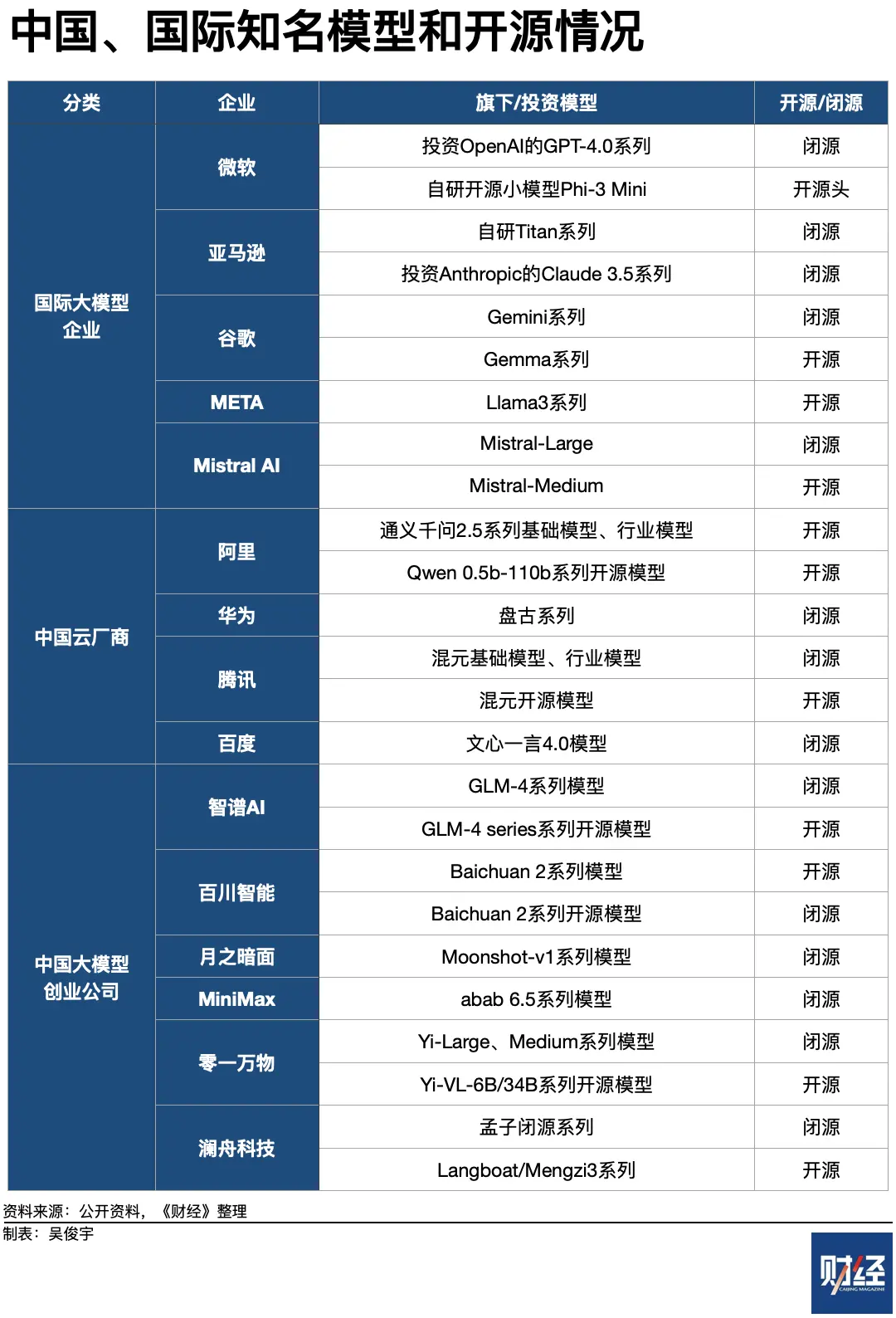
最极端的是,只做开源模型。走这条路的企业比较少,Meta是少数之一。好处是会吸引更多用户,问题是没有盈利模式,只有大公司烧得起。
Meta旗下的Llama 3是全球用户最多的开源模型。Meta的主营业务是社交媒体(如Facebook、Instagram),2023年净利润高达390亿美元。Meta既有探索新业务的冲动,又没有靠模型盈利的压力。因此,它可以只做开源模型,暂时不考虑盈利问题。
一条中间路线是开源、闭源并行,这条路很灵活。企业既能靠开源获取用户,又能靠闭源获取收入;既给了开发者选择空间,企业自己也有容错空间。
选这条路的企业包括微软、谷歌、阿里云、腾讯云,以及Mistral Al、智谱AI、百川智能等AI创业公司。开源、闭源并行的常见做法是,用免费的开源模型吸引用户,引导用户使用尺寸更大、性能更强的闭源模型。比如,微软主力商业化模型是OpenAI旗下的GPT-4系列,但也开源了小模型Phi-3 Mini;阿里云开源了5亿-1100亿参数的十余款模型,还同时提供闭源的基础大模型、行业模型;谷歌开源了Gemma系列小模型,还提供闭源的Gemini系列基础大模型;Mistral Al等创业公司开源了上代性能落后的模型,引导用户付费使用本代性能更强的模型。
开源、闭源并行的问题是,商业化有时会左右手互搏。一些客户用了免费的开源模型,就不会再用付费的闭源模型。模型厂商会因此失去一部分收入。
一位中国AI软件服务商技术人士今年7月对《财经》表示,他们近期用阿里云的通义千问开源模型(Qwen2)二次训练微调,服务了一个地方城市旅游局。这笔订单超过千万元,他们是受益者,但阿里云没有收入。《财经》查询了Github(全球最大代码托管平台)上Qwen2的许可协议。协议显示“无需提交商业使用请求”。也就是说,Qwen2被训练微调后商用无需付费。
开源的长远价值是,做大模型市场蛋糕。一位阿里云人士对《财经》表示,用户修改开源模型拿去商用很正常,做开源就要有这个准备。阿里云虽然暂时没有吃到所有蛋糕,但做大了行业蛋糕。长期来看,最终还是会受益。大模型被政府、大中小企业、开发者等不同客户广泛使用时,才会出现化学反应。大模型产业要建立生态,形成增长飞轮。阿里云旗下AI开源社区魔搭ModelScope可以看到这一趋势。截至今年7月,魔搭社区有超过560万开发者,5500多款优质模型和上千数据集,是中国最大的开源模型社区。
一种更乐观的观点认为,开源、闭源甚至可以成上下游关系。开源在技术上游,负责社区参与、技术迭代、吸引客户,确保技术领先同行。闭源在下游,负责商业变现。
澜舟科技是一家中国的大模型创业公司。澜舟科技合伙人、联席CEO李京梅对《财经》表示,开源是技术策略也是商业策略。它可以影响开发者社区,也可以影响潜在客户的技术团队的心智。开源和闭源不矛盾。闭源模型客户反馈周期相对较长,但开源模型的社区开发者会很快给到反馈。这可以帮公司快速迭代产品。
一位中国头部科技企业的AI战略规划人士认为,对阿里云这类头部云厂商来说,开源、闭源并行比只做闭源好。阿里云收入主要来自公共云四大件(计算、存储、网络、数据库)。免费的开源模型会促进客户业务数据消耗,进而带动上述基础云产品的销售。
只做闭源模型,这条路简单直接、逻辑清晰。走这条路线的大公司认为,大模型要商业化,就必须闭源,否则无法商业闭环。
AI创业公司OpenAI(旗下GPT-4系列模型)、亚马逊(投资了AI创业公司Anthropic,旗下包括Claude 3.5系列模型)、华为(盘古大模型)、百度(文心大模型)等企业都选了这条路。企业使用大模型通常按API(应用程序编程接口)调用次数付费,这就像为水电煤按使用量缴费。闭源模型的商业模式理论上是最健康的。微软Azure、亚马逊AWS、谷歌云近一年营收增速都提升了5个百分点左右,利润水平也略有提升。这被认为是大模型拉动的结果。
但在中国,闭源模型短期内很难真正盈利。今年5月中国模型市场开始价格战。降价目的是激发客户需求,做大市场规模。字节跳动旗下云服务火山引擎、阿里云、腾讯云、百度智能云先后把大模型调用价格下降了90%以上。大模型调用毛利率从超过60%下滑至低于0%。
一位中国云厂商大模型业务负责人认为,大模型调用进入了“负毛利时代”。使用次数越多,亏损就越大。区别是,阿里、字节跳动、百度这些大厂亏得起,中小企业、创业公司亏不起。
他和一位大模型创业公司高管表达了类似的观点——不同公司基因不同,模型商业策略也不同。云是阿里云的核心业务,模型开源的最终目的是卖更多云。火山引擎背靠字节跳动,母公司广告业务可以输血。火山引擎在云计算市场份额远低于阿里云,“光脚不怕穿鞋的”,希望通过价格战抢占更多市场份额。AI是百度的核心业务,百度希望靠大模型盈利,所以强调闭源模型的价值。

争论是什么?共识是什么?
中国的大模型开闭源之争,有几个焦点——其一,开源模型和开源软件是否有区别?其二,开源模型和闭源模型,谁更强?其三,开源模型和闭源模型,谁更贵?
第一个争论,开源模型和开源软件是否有区别?答案是,区别很大。绝大部分开源模型并没有完全开源。它们更像是可以免费使用的黑箱,而不像开源软件一样是个透明的盒子。
开源软件会公布源代码,开发者能通过源代码掌握软件的大部分技术细节。开源软件免费的核心逻辑是,全社会的开发者可以帮助软件厂商找产品Bug、提优化建议。社会化开发,不仅可以降低软件的研发成本,还能加快软件的迭代速度。手机操作系统安卓、数据库软件MySQL都是靠这种方式取得了成功。
开源模型的复杂性远超开源软件,可开源的项目包括源代码、参数权重、模型结构、训练数据、训练过程等。荷兰拉德堡德大学两位学者,利森菲尔德、丁格曼斯今年3月发表论文,对比了开源模型的开源程度。论文显示,性能最强的开源模型通常只会开源参数权重。一种解释是,模型厂商为确保模型性能领先,不能把“配方”全盘托出。以全球性能最强的开源模型Llama3为例,它只部分开源了参数权重和模型结构,源代码、训练数据、训练过程均未开源。
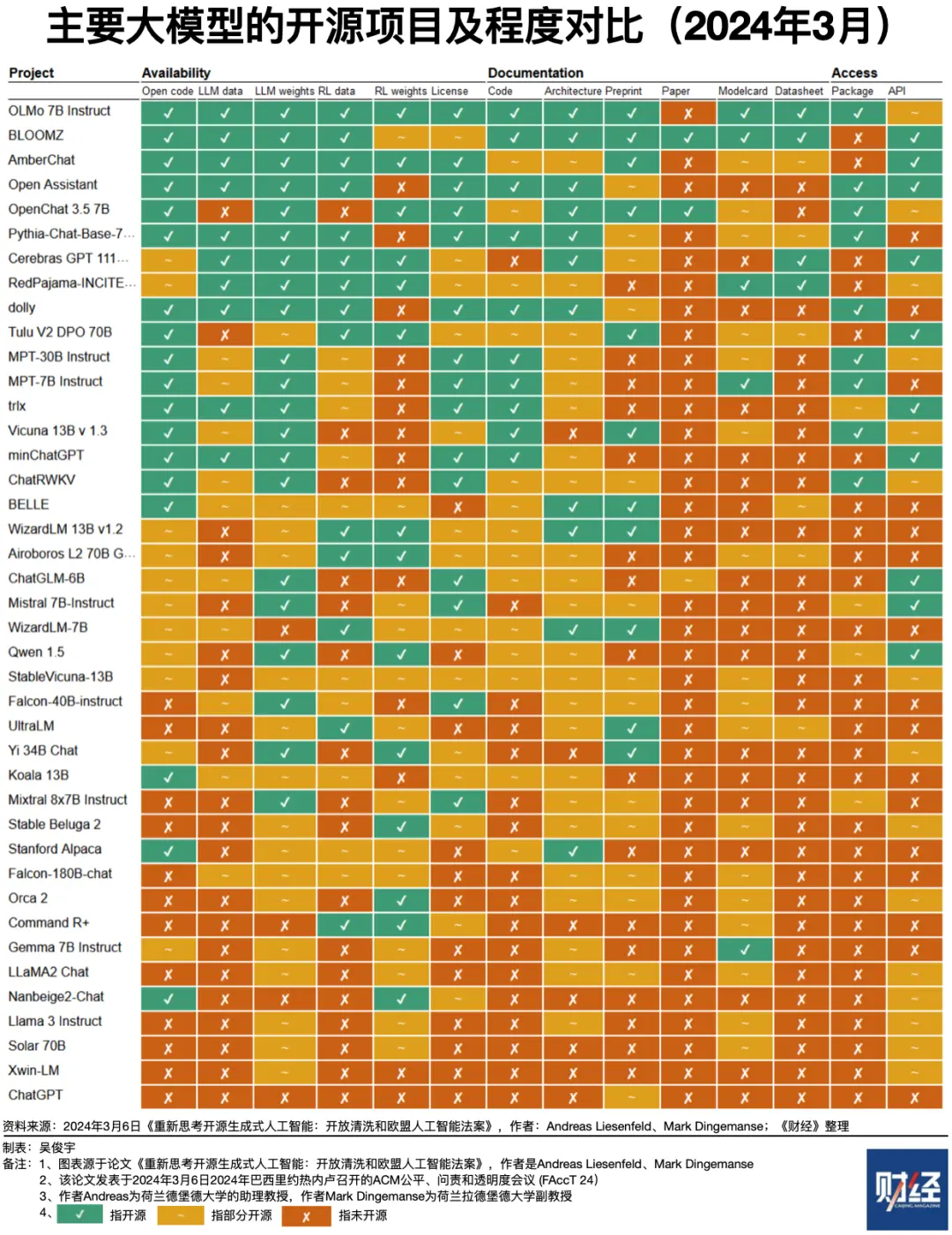
开源理念对产业生态的价值毋庸置疑。百度智能云AI与大模型平台总经理忻舟今年7月对《财经》表示,开源模型会让模型应用、行业模型变得更丰富。但他反对将开源模型和开源软件混为一谈。因为两者存在本质区别——开源模型无法像开源软件一样,靠社会开发者参与提升产品性能、降低研发成本。基座模型只能靠模型厂商自己训练而提升,开源模型精调、推理优化都不及商业模型,对开发者技术要求很高,实际使用成本并不低。
第二个争论,开源模型和闭源模型,谁更强?事实是,闭源模型性能通常比开源模型更强,但开源模型和闭源模型的性能差距在缩小。

斯坦福大学基础模型研究中心(CRFM)长期进行全球大模型测试排名。截至7月24日公布的大规模多任务语言理解 (MMLU)测试排名显示,性能前十的只有Llama3.1是开源模型,Claude3.5(亚马逊投资)、GPT-4o(微软投资)、Gemini1.5 Pro(谷歌自研)等都是闭源模型。
李京梅认为,同一家公司的闭源模型一定比开源模型性能强。但在行业横向对比,闭源模型不一定比开源模型强。因为大模型6个-12个月迭代一次,一些开源模型的进化速度可能更快。
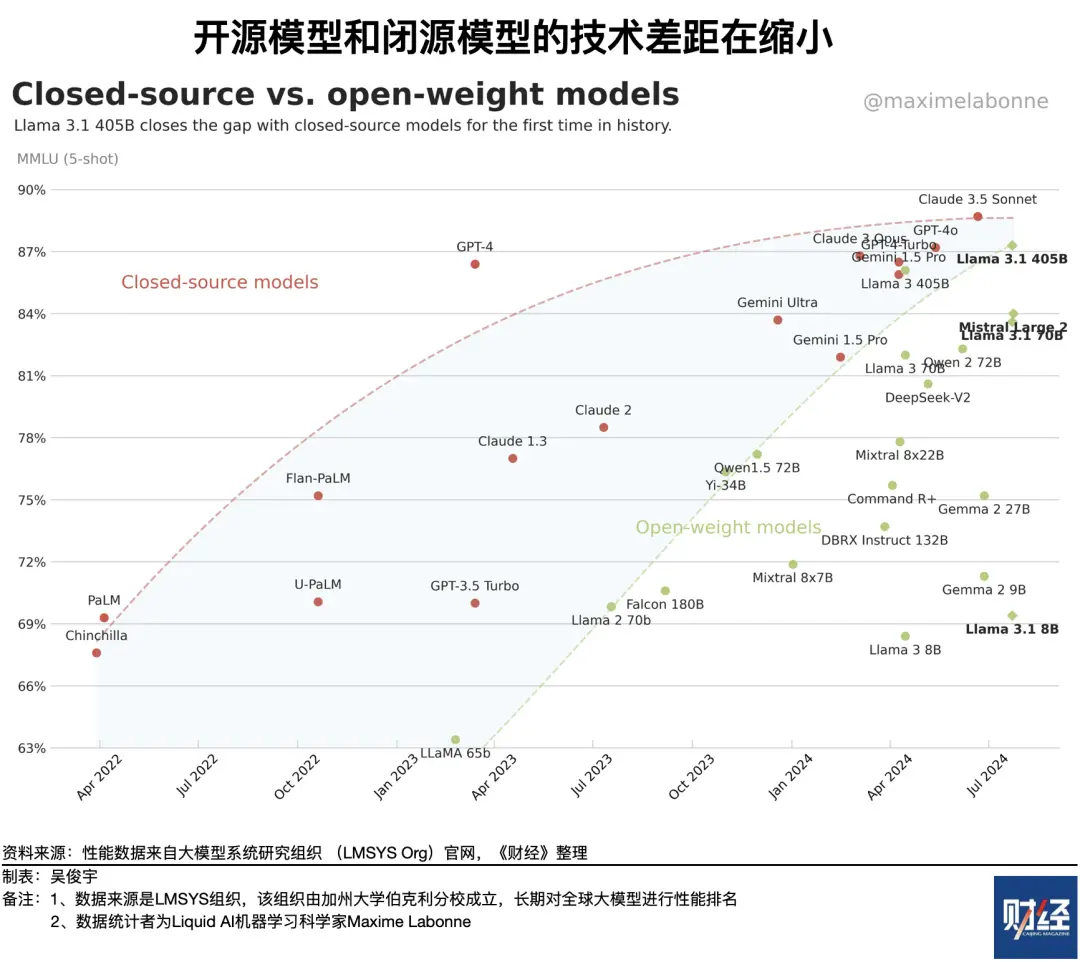
评测组织的排名显示了这一趋势。LMSYS组织(大模型系统研究组织)由加州大学伯克利分校发起,该组织也会长期对全球模型性能进行评测排名。Meta旗下Llama3.1、阿里云旗下Qwen2在该评测中的排名正在迅速提升。Llama3.1甚至超越了大部分闭源模型。
一位中国云厂商大模型业务负责人分析,开源模型和闭源模型性能差距缩小有两个原因——近一年基础大模型普遍进入性能提升的瓶颈期。开源模型吸引了大量开发者。虽然他们无法通过代码反馈直接提升模型性能,但提升了模型研究的整体水平,这间接帮开源模型提升了模型性能。
第三个争论,开源模型和闭源模型,谁更贵?结论是,性能才是决定因素。模型使用成本和模型性能直接相关。性能越强,长期使用成本越低,因为完成任务的调用次数更少。
开源模型免费,通常给人价格便宜、成本更低的印象。忻舟解释,大模型应用是一套包含“技术+服务”的综合解决方案,企业要算“总账”。 闭源模型厂商除了提供完整的模型和工具链,还会提供培训和技术服务,帮企业快速上手。开源模型看似免费,但要达到与闭源相同的效果,需要后续投入很多的人力、资金、时间,综合成本反而更高。
长期来看,开源、闭源模型应用成本的决定性因素是推理成本。同等参数量级的闭源模型表现通常好于开源模型,综合成本也更低。忻舟算了一笔账,如果一家企业部署开源模型免费,部署闭源模型需要50万元。前期投入阶段,开源模型更便宜。后期使用阶段,如果闭源模型比开源模型综合性能强20%,闭源模型在一些用量大的企业一天就能省数万元。最终,长期使用成本一定是远低于开源模型。

谁在用开源模型?谁在用闭源模型?
开源模型好还是闭源模型好?这个问题并不是由供给方的模型厂商说了算,而是由需求方的企业客户说了算。
在公开场合,企业口水战不断。但多位云厂商技术人士对《财经》表示,这些争论不能否定彼此的市场价值。这两种需求会长期共存。换个思路看,口水战反而更容易共同做大市场声量。
事实上,大部分企业客户并不关心模型是否要开源。忻舟总结,他在和很多大型企业客户交流后发现,IT部门负责人要不要用一款模型有很多因素,按优先级排名通常是:效果、性能、价格、安全。开源、闭源并不是决定性因素。
在多数企业的“工具箱”里,开源模型、闭源模型是互补的。大型企业落地大模型通常分成不同阶段。
前期,IT部门会梳理市场上开源模型、闭源模型的性能和特征。不同模型优势不同,有的语言语音能力强,有的数据统计能力强。前期免费的开源模型POC(概念验证)测试,验证业务效果。
中期,在营销、客服、知识库等难度低、见效快的业务场景先做一期项目。不仅要采购闭源模型后,还要训练微调一套自己的开源模型。让内外部模型“赛马”,比较不同模型的效果、成本,随时切换用量。
后期,根据落地效果,循序渐进在难度高、见效慢的业务场景规划二期、三期工程。这时往往甚至要耗费千万元建立一套自主可控的基础大模型或行业大模型。
开源模型免费,但无法开箱即用,需要时间折腾,也没人负责兜底。闭源模型能直接拿到成熟的产品,售前、售中、售后有全程服务。简单理解,开源模型像自己买菜下厨,闭源模型像花钱去餐厅吃饭。
忻舟的观点是,开源模型适合用于学术研究,适合一些IT预算极其有限的中小企业,也适合部分大型企业用于自主可控的内部自研项目,但不适合对外的大型商业项目。在一些动辄百万元、千万元级别的严肃商业项目中,闭源模型还是最佳选择。
开源模型并不是免费的午餐。大型企业使用开源模型有很多隐性成本。比如采购算力、软件适配等。一位中国出海智能营销服务商的技术负责人今年7月对《财经》表示,他所在的企业重度依赖云服务,每年研发支出超过8000万元。近两年公司同时在用十余款闭源模型,但里面没有开源模型。在他看来,开源模型要有时间、人力去折腾。大多数开源模型无法开箱即用,也没人兜底,只能算“玩具”。他倾向于管好十余款闭源模型,根据价格、性能随时切换。这样性价比最高。
一位大型股份制商业银行IT负责人认为,开源模型无法开箱即用不是大问题。他在2023年12月曾对《财经》表示,他的团队同时用了阿里(通义开源模型)、Meta(Llama开源模型)、百度(文心系列)、智谱(GLM系列)用于自研合规报告审计应用。开源模型适合这种小型项目,既能免费POC测试,也能按需修改。他的IT团队有数十人,还有外包IT服务公司,人手足以应付这些问题。但他同时认为,百万、千万元的大型项目中,闭源模型更合适。因为闭源模型稳定可靠,还能找到负责兜底的模型公司。
用开源模型完整训练一套行业模型需要千万元,还要采购AI芯片自建机房。上述AI软件服务商技术人士总结,开源模型适合一些对数据安全、自主可控要求高,且对成本没那么敏感的央国企。它们会用开源模型训练自己的行业模型。因为“开源模型+私有云”符合很多央国企数据安全和自主可控的诉求。

未来怎么走?
中国市场的大模型开闭源之争是纯粹的商业问题。但在国际市场,大模型开闭源之争更多涉及反垄断、国家利益等因素。
今年5月价格战之后,中国的大模型调用已经进入“负毛利时代”。开源模型、闭源模型同时面临一个问题——大模型无法直接盈利。
“大模型市场的淘汰赛已经开始了。”一位中国云厂商大模型业务负责人分析,大模型调用负毛利意味着,短期内调用次数越多,云厂商亏损越大。中国云厂商赌的是,大模型调用价格降低90%之后,未来1年-2年大模型调用次数会指数级增长。长期来看,云厂商算力成本会随着客户需求增长而摊薄,最终仍能实现正向利润。即使这个赌局不成立,也会有一批模型厂商死于价格战,活下去的厂商会收拾残局。
多位行业人士对《财经》表达了同一个观点,这轮淘汰赛会持续1年-2年,只有3家-5家基础模型企业能继续活下去。
中国信息化百会人执委、阿里云智能科技研究中心主任安筱鹏今年7月对《财经》表示,中国没有百模大战,甚至没有十模大战。大模型需要持续投资,要有万卡甚至十万卡的能力,还需要商业回报。很多企业不具备这样的能力。未来中国市场只会有三五家基础模型厂商。
谁是价格战的受益者?谁会笑到最后?上述中国头部科技企业的AI战略规划人士认为,这轮价格战中,阿里云和字节跳动的火山引擎血最厚。阿里云能靠云盈利,火山引擎有字节跳动的广告业务输血。打价格战,百度不如阿里、字节跳动。但百度的文心大模型技术强,会有一批愿意为技术付费的客户。这对百度扛住价格战有帮助。他进一步解释,中国市场这几家大模型创业公司未来1年-2年会面临严峻考验。大模型创业公司要么选择成为项目制模型开发公司,要么转向垂直行业模型。
中国大模型市场的全局竞争,远比开源模型、闭源模型的局部竞争更重要。全局竞争的方向,会直接决定局部竞争的结果。
一位阿里云人士直言,开源、闭源模型都有各自的好处,阿里云希望让AI更普惠。无论开源、闭源,核心目的都是给开发者更多选择。阿里云选择了开源、闭源两条腿走路,既有全尺寸、全模态的开源模型,也有闭源模型。另一位中国云厂商大模型业务负责人认为,开源没有商业模式。中国模型市场,只有头部企业或者极少数能持续融资的创业公司能坚持开源。中国市场最终可能只会剩下1家-2家开源模型。
模型厂商几乎每6个-12个月就会训练出新一代的模型。在中国模型市场,随着盈利压力变大,模型开源可能会变得越来越有“策略”——企业会倾向开源上一代技术落后、参数更小的模型,引导用户付费使用技术更新、参数更大的闭源模型。
开源模型和闭源模型的竞争短时间内不会结束。一些企业甚至可以同时跑通开源和闭源两条路。在IT产业,这并非没有先例,数据库诞生超过60年,第一款开源数据库诞生至今超过50年。数据库市场至今同时活跃着不同的闭源、开源数据库,新的数据库品牌仍然层出不穷。数据库巨头Oracle甚至同时拥有闭源的RDBMS数据库和开源的MySQL数据库。
多位云厂商技术人士认为,开源模型和闭源模型会长期共存。大模型市场,会在不同技术路线的竞争中逐渐壮大。
相关内容
- 2024-12-22 关注!FastVideo,用于加速大型视频扩散模型的开源框架
- 2024-12-16 清华系出手!全球第一款端侧全模态理解模型开源
- 2024-12-13 字节跳动与北京大学成立豆包大模型联合实验室
- 2024-12-11 LG发布EXAONE 3.5开源AI模型:长文本处理利器、独特技术有效降低“幻觉”
- 2024-12-07 Meta今年压轴开源AI模型Llama3.3登场:700亿参数,性能比肩4050亿
点击排行
- 105-17OpenAI多位重量级高管离职,质疑再次涌向Sam Altman
- 203-07ChatGPT-Plus,AI 助手全套开源解决方案,自带运营管理后台,开箱即用。
- 306-22RTranslator: 全球第一个开源实时翻译应用程序
- 410-18诺奖得主哈萨比斯最新访谈:仅仅将AI视作一种技术是错误的
- 505-17马斯克称OpenAI最新模型慢得离谱
- 606-23OpenAI CTO:GPT-5可能会在2025年底或2026年初推出
- 706-23企业家自曝用了ChatGPT后裁员近1/10:管理效率大幅提升
- 805-17GPT-4o被全球网友玩坏了 谷歌:终究是错付了
- 906-23高通开放AI模型,助力开发者打造骁龙X Elite平台智能应用
- 1005-17谷歌Gemini AI 计划为学校提供额外的数据保护和隐私