阿里云通义千问Qwen2-VL第二代视觉语言模型开源
9 月 2 日消息,阿里云通义千问今日宣布开源第二代视觉语言模型 Qwen2-VL,并推出 2B、7B 两个尺寸及其量化版本模型。同时,旗舰模型 Qwen2-VL-72B 的 API 已上线阿里云百炼平台,用户可直接调用。

据阿里云官方介绍,相比上代模型,Qwen2-VL 的基础性能全面提升:
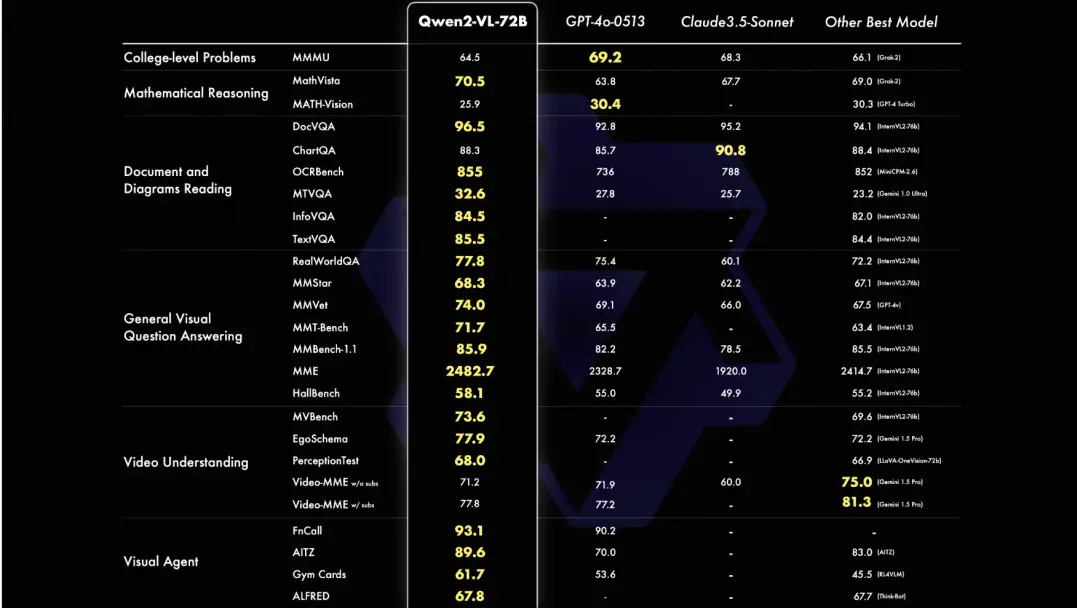
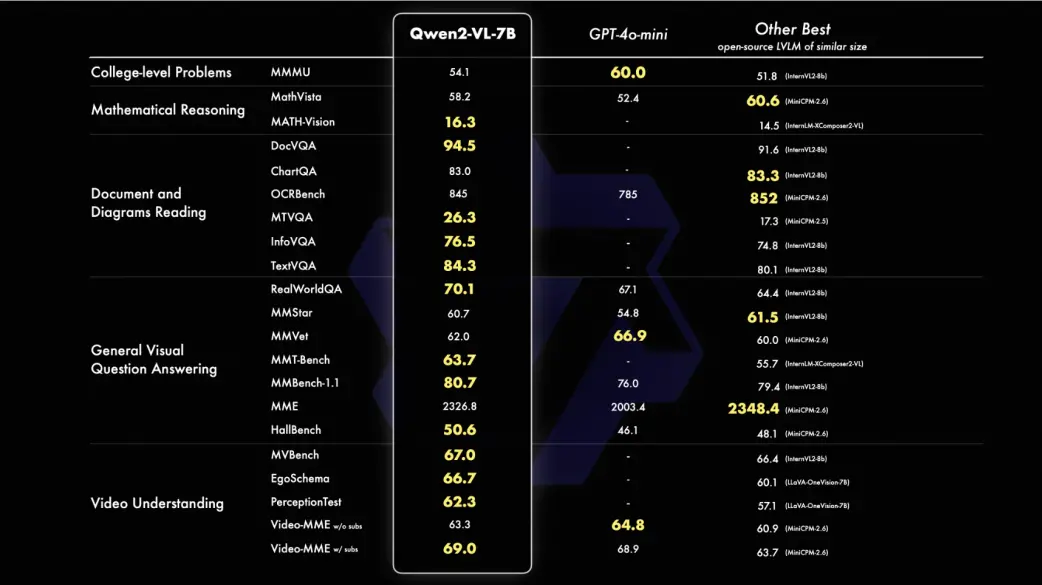
读懂不同分辨率和不同长宽比的图片,在 DocVQA、RealWorldQA、MTVQA 等基准测试创下全球领先的表现;
理解 20 分钟以上长视频,支持基于视频的问答、对话和内容创作等应用;
具备强大的视觉智能体能力,可自主操作手机和机器人,借助复杂推理和决策的能力,Qwen2-VL 可以集成到手机、机器人等设备,根据视觉环境和文字指令进行自动操作;
理解图像视频中的多语言文本,包括中文、英文,大多数欧洲语言,日语、韩语、阿拉伯语、越南语等。
![]()
Qwen2-VL 延续了 ViT 加 Qwen2 的串联结构,三个尺寸的模型都采用了 600M 规模大小的 ViT,支持图像和视频统一输入。
但为了让模型能够更清楚地感知视觉信息和理解视频,团队在架构上进行了一些升级:
一是实现了对原生动态分辨率的全面支持。不同于上代模型,Qwen2-VL 能够处理任意分辨率的图像输入,不同大小图片将被转换为动态数量的 tokens,最小只占 4 个 tokens。这一设计模拟了人类视觉感知的自然方式,确保了模型输入与图像原始信息之间的高度一致性,赋予模型处理任意尺寸图像的强大能力,使得其可以更灵活高效地进行图像处理。
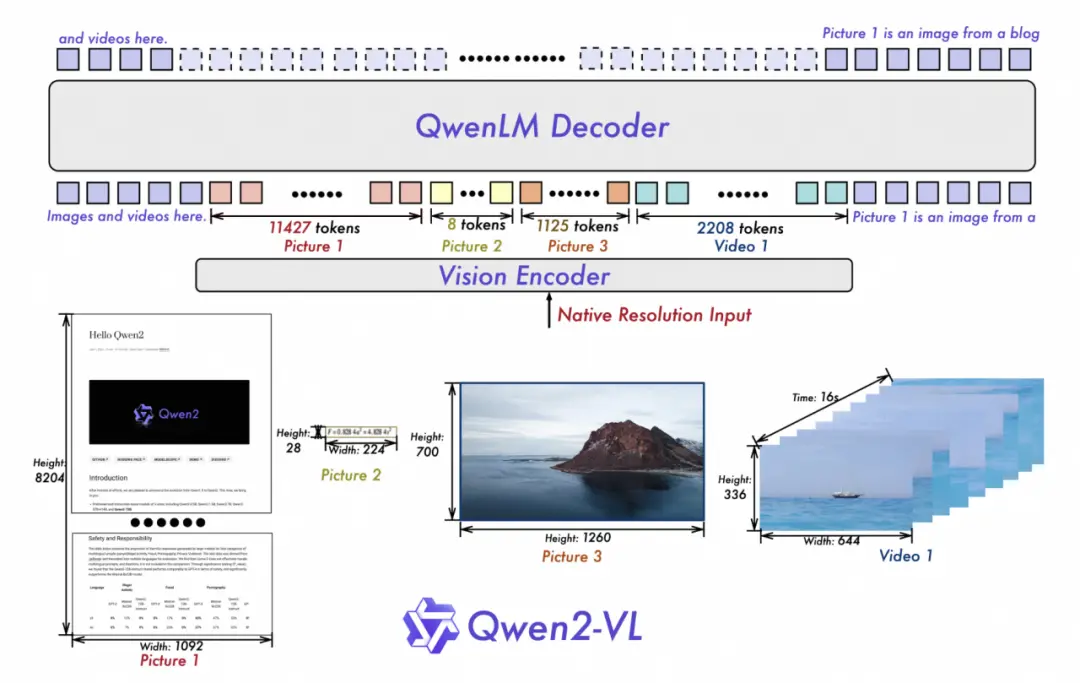
二是使用了多模态旋转位置嵌入(M-ROPE)方法。传统的旋转位置嵌入只能捕捉一维序列的位置信息,M-ROPE 使得大规模语言模型能够同时捕捉和整合一维文本序列、二维视觉图像以及三维视频的位置信息,赋予了语言模型强大的多模态处理和推理能力,能让模型更好地理解和建模复杂的多模态数据。

此次 Qwen2-VL 开源的多款模型中的旗舰模型 Qwen2-VL-72B 的 API 已上线阿里云百炼平台,用户可通过阿里云百炼平台直接调用 API。
同时,通义千问团队以 Apache 2.0 协议开源了 Qwen2-VL-2B 和 Qwen2-VL-7B,开源代码已集成到 Hugging Face Transformers、vLLM 和其他第三方框架中。开发者可以通过 Hugging Face 和魔搭 ModelScope 下载使用模型,也可通过通义官网、通义 App 的主对话页面使用模型。
相关内容
- 2024-11-12 谷歌说到做到 诺贝尔奖AI成果AlphaFold3重磅开源!人人皆可免费下
- 2024-11-05 腾讯发布开源MoE大语言模型Hunyuan-large:总参数398B为业内最大
- 2024-10-31 OpenAI宣布开源SimpleQA新基准,专治大模型“胡言乱语”
- 2024-10-23 Meta 上周开源了一个端到端的语音模型 Spirit LM
- 2024-10-21 复旦、百度联手打造AI开源模型Hallo2
点击排行
- 105-17OpenAI多位重量级高管离职,质疑再次涌向Sam Altman
- 206-22RTranslator: 全球第一个开源实时翻译应用程序
- 303-07ChatGPT-Plus,AI 助手全套开源解决方案,自带运营管理后台,开箱即用。
- 405-17马斯克称OpenAI最新模型慢得离谱
- 506-23OpenAI CTO:GPT-5可能会在2025年底或2026年初推出
- 610-18诺奖得主哈萨比斯最新访谈:仅仅将AI视作一种技术是错误的
- 706-23企业家自曝用了ChatGPT后裁员近1/10:管理效率大幅提升
- 805-17GPT-4o被全球网友玩坏了 谷歌:终究是错付了
- 906-23高通开放AI模型,助力开发者打造骁龙X Elite平台智能应用
- 1005-17谷歌Gemini AI 计划为学校提供额外的数据保护和隐私