OpenAI发布全新o1模型:它会像人类一样“深思熟虑”
作者|苏霍伊
没有一点点防备,OpenAI造势已久的“草莓”(Strawberry)模型,就这样发布了。

o1模型的介绍切片,来源:OpenAI
北京时间今天凌晨,OpenAI发布了名为OpenAI o1的新模型,也是之前所传的“Strawberry”,但最初o1的代号为“Q*”。OpenAI的CEO萨姆·奥尔特曼(Sam Altman)则称它为“新范式的开始”。
从OpenAI的官方信息看下来,总结o1的特点就是:更大、更强、更慢、更贵。
经过强化学习(Reinforcement Learning),OpenAI o1在推理能力方面取得了重大进展。研发团队观察到,随着训练时间(强化学习的增加)和思考时间(测试时的计算)的延长,o1模型的表现逐渐提升。这种方法的扩展所面临的挑战与大型语言模型(LLM)的预训练限制截然不同。
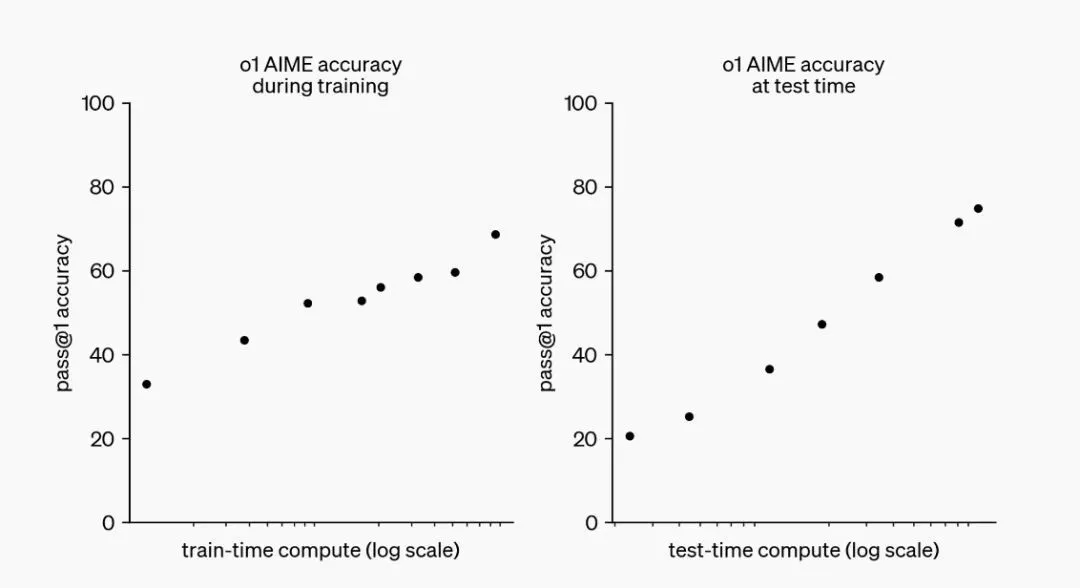
o1性能随着训练时间和测试时间计算而平稳提升,来源:OpenAI
关于市面上所传“o1模型能够自主为用户执行浏览器或系统操作级别的任务”,目前的公开信息并未提及这一功能。
OpenAI官方表示:“虽然这款初期模型还没有像网上搜索信息、上传文件和图片这样的功能,但它在解决复杂推理问题上有了显著进步,这代表了人工智能技术的新水平。所以我们决定给这个系列一个新的起点,将其命名为OpenAI o1。”由此可见,o1的主要应用还是集中在通过文本交互进行问题解答和分析,而不是直接控制浏览器或操作系统。
与早期版本不同,o1模型在作出回答之前会像人类一样“深思熟虑”,用时约10—20秒,产生一个长长的内部思路链,并能够尝试不同的策略并识别自身的错误。
这种强大推理能力使o1在多个行业中具有广泛的应用潜力,尤其是复杂的科学、数学和编程任务。在处理物理、化学和生物问题时,o1的表现甚至和该领域的博士生水平不相上下。在国际数学奥林匹克的资格考试(AIME)中,o1的正确率为83%,成功进入了美国前500名学生的行列,而GPT-4o模型的正确率仅为13%。
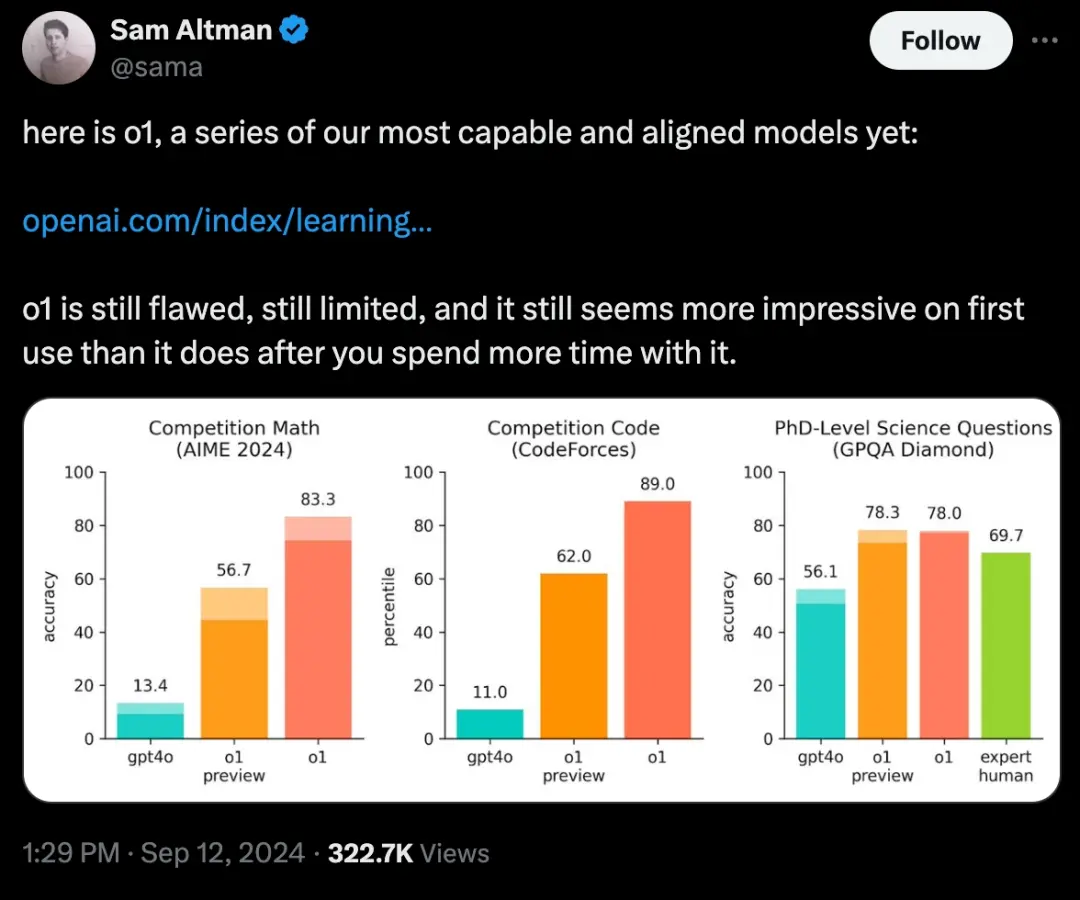
奥尔特曼也在X上分享了o1,来源:X
OpenAI提供了一些具体的使用案例,比如医疗研究人员可利o1来标注细胞测序数据;物理学家可用o1生成量子光学所需的复杂数学公式;软件开发者则可以借助它来构建和执行复杂的多步骤工作流程等。
o1系列分包含三款模型,OpenAI o1、OpenAI o1-preview和OpenAI o1-mini。这两款模型从今天开始对用户开放使用:
OpenAI o1:高级推理模型,暂不对外开放。
OpenAI o1-preview:这个版本更注重深度推理处理,每周可以使用30次。
OpenAI o1-mini:这个版本更高效、划算,适用于编码任务,每周可以使用50次。
开发者和研究人员现在可以通过ChatGPT和应用程序编程接口访问这些模型。
至于价格,早先The information曾爆料,OpenAI高管正在讨论其即将推出的全新大模型“草莓”(Strawberry)和“猎户座”(Orion)的拟定在2000美元一个月,引发一众吐槽和声讨。但今日有人发现,ChatGPT Pro会员已经上线了,售价200美元/月。从2000美元到200美元的落差,很难让人不产生一种“占便宜”的感觉,价格心理战被OpenAI玩转得明明白白。
今年5月,奥尔特曼在于麻省理工学院校长莎莉·科恩布鲁斯(Sally Kornbluth)炉边谈话中曾提到,GPT-5或将数据与推理引擎分离。
“GPT-5或GPT-6可以成为最佳的推理引擎,目前而言,能达到最佳引擎的唯一路径就是训练大量的数据。”奥尔特曼认为,但实际上,模型在处理数据时浪费了许多数据资源。比如GPT-4。它也能像数据库一样工作,只是推理速度慢、成本高昂且效果“不尽如人意”。这些问题本质上是因为模型的设计和训练方式导致的资源浪费。
“不可避免的,这是我们制作推理引擎模型的唯一方法的副作用。”他所能预见未来的新方法,就是将模型的推理能力与对大数据的需求性剥离。
但在今天的发布中,GPT-5没有出现,数据与推理引擎分离这一设想也不见踪影。
至于价格,早先The information曾爆料,OpenAI高管拟将推出的全新大模型“草莓”(Strawberry)和“猎户座”(Orion)的价格定在2000美元/月,这引发一众吐槽和声讨。但今日有人发现,ChatGPT Pro会员已经上线了,售价为200美元/月。
从2000美元到200美元的落差,很难不让用户产生一种“占便宜”的感觉,价格心理战实属被OpenAI玩转得明明白白。
2.打磨“思维链”

大模型一直因其“不会数数”而被诟病。究其根本,是因为大模型缺乏结构化推理的能力。
推理是人类智能的核心能力之一。而大模型主要通过非结构化的文本数据进行训练,这种数据通常包括新闻文章、书籍、网页文本等。文本是自然语言形式,不遵循严格的逻辑或结构化规则,所以模型学到的也主要是如何根据上下文生成语言,而不是如何逻辑推理或遵循固定的规则处理信息。
但许多复杂推理任务都是结构化的。
比如逻辑推断、数学问题解决或编程等。如果我们想要走出一个迷宫,就需要遵循一系列逻辑和空间规则才能找到出口。这类问题要求模型能够理解并应用一系列固定的步骤或规则,但这正是大部分大模型所缺乏的。
所以,像ChatGPT、BARD等模型虽能根据训练数据生成看似合理的回答,其实更像是“随即鹦鹉”(stochastic parroting),它们往往无法真正理解背后的复杂逻辑或执行高级推理任务。
要知道,大模型在处理非结构化的自然语言文本时表现出色,原于这正是训练数据的侧重点。但当涉及到需要结构化逻辑推理的任务时,它们往往难以表现得像人类一样精确。
为解决这一难题,OpenAI想到了用思维链(Chain of Thought, CoT)来“破局”。
思维链是一种帮助AI模型进行推理的技术。它通过让模型在回答复杂问题时,逐步解释每一步的推理过程,而不是直接给出答案。因此模型在回答问题时就像是人类在解题时那样,先思考每一步的逻辑,再逐步推导出最终的结果。
但在AI训练的过程中,人工标注思维链耗时又昂贵,在scaling law主导下所需的数据量对人工而言基本是一项不可能完成的任务。
这时,强化学习就成了更实用的替代方案。
强化学习可以让模型通过实践和试错自己学习,它不需要人工标注具体每一步怎么走,而是通过不断的实验和反馈来优化解决问题的方法。
具体来说,就是模型在尝试解决问题的过程中,根据所采取行动的结果(好的或坏的)来调整自己的行为。这样,模型能够自主探索多种可能的解决方案,并通过不断试错找到最有效的方法。比如在游戏或模拟环境中,AI可以通过自我对弈不断优化策略,最终学会如何精确执行复杂任务,而无需人工逐一指导每一步。
比如2016年横扫围棋界的AlphaGo,它就是结合了深度学习和强化学习的方法,通过大量的自我对弈来不断优化其决策模型,最终能够战胜世界顶级的围棋选手李世石。
o1模型就是用和AlphaGo“同门”的方法逐步处理问题。
在这个过程中,o1通过强化学习不断完善自己的思考过程,学会识别和纠正错误,将复杂步骤分解为更简单的部分,并在遇到障碍时尝试新的方法。这种训练方式显著提升了o1的推理能力,让o1能够更有效地解决问题。
OpenAI的联合创始人之一格雷格·布罗克曼(Greg Brockman)对此感到“十分自豪”,“这是我们首次使用强化学习训练的模型。”他说道。

布罗克曼的推文切片,来源:X
布罗克曼介绍,OpenAI的模型原先进行的是系统一型思维(快速、直观的决策)而思维链技术则启动了系统二型思维(慎重、分析性的思考)。
系统一型思维适合快速应对,而系统二型思维则通过“思维链”技术,让模型能够逐步推理解决问题。实践表明,通过持续的试错,从头到尾完整训练模型(如在围棋或Dota等游戏中应用),可以极大提升模型的表现。
此外,o1技术虽然仍在开发初期,但已在安全性方面表现良好。如通过增强模型对策略进行深入推理来提高其对抗攻击的鲁棒性和降低幻觉现象的风险。这种深层次的推理能力已经开始在安全性评估中显示出积极的效果。
“我们基于o1模型开发了一个新的模型,让它参加了2024年国际信息学奥林匹克(IOI)比赛,并在49%的排名中得到了213分。”OpenAI方表示。
它在与人类参赛者相同的条件下参赛,解决六个算法问题,每个问题有50次提交机会。通过筛选多个候选方案并根据公开测试用例、模型生成的测试用例和评分函数来选择提交方案,证明了其选择策略的有效性,平均得分高于随机提交的分数。
在提交次数放宽到每题10,000次时,模型表现得更好,得分超过了金牌标准。最后,这个模型在模拟的Codeforces编程比赛中展示了“令人惊叹”的编码能力。GPT-4o的Elo等级为808,位于人类竞争者的第11百分位。而我们的新模型Elo等级为1807,表现优于93%的竞争者。
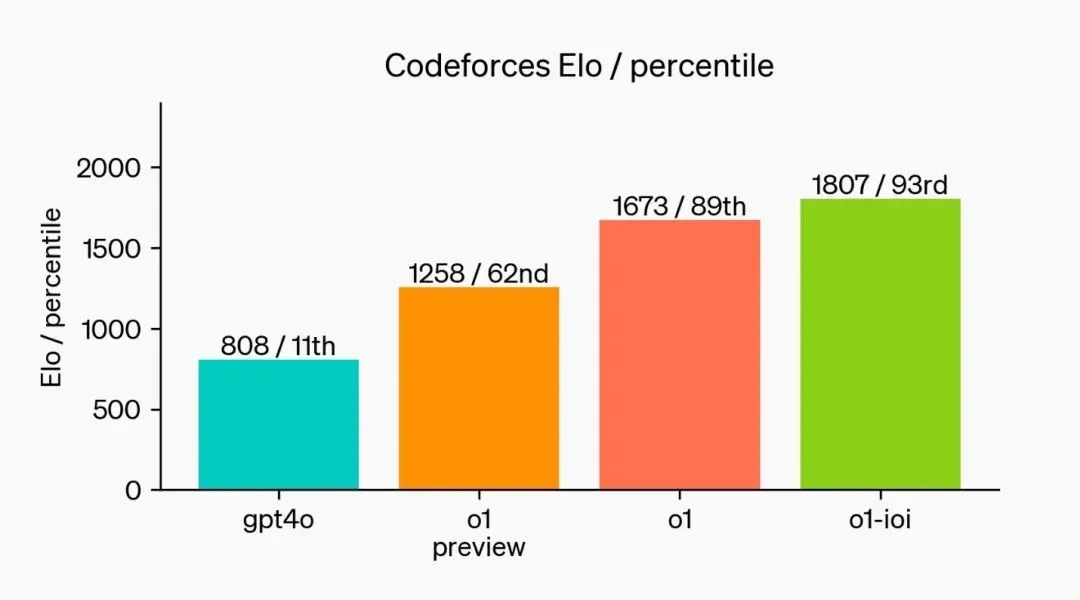
在编程竞赛中进一步的微调提升了o1模型的表现,来源:OpenAI
2.“多事之秋”的OpenAI
![]()
在o1发布前,OpenAI一直深陷公司核心高层变动的阴云中。
今年2月,OpenAI的创始成员、研究科学家安德烈·卡帕斯(Andrej Karpathy)在X上宣布,他已离开这家公司。卡帕斯表示,他友好地离开了OpenAI,“不是因为任何特定的事件、问题或戏剧性事件”。
前首席科学家、联合创始人伊利亚·苏茨克维(Ilya Sutskever)则在5月宣告离职,超级对齐团队也随之解散,业内认为这是OpenAI在追求技术突破和确保AI安全之间平衡的失败尝试。

右起分别是伊利亚·苏茨克维、格雷格·布洛克曼 (Greg Brockman)、山姆·奥尔特曼和米拉·穆拉蒂。来源:纽约时报
在伊利亚发布通告的数小时后,RLHF发明者之一、超级对齐团队的共同主管简·雷克(Jan Leike)也追随他的脚步一起离开,再次给OpenAI的未来增加了更多的不确定性。
8月,OpenAI联合创始人、研究科学家约翰·舒尔曼(John Schulman)透露了自己的离职,并加入Anthropic专注于AI对齐的深入研究。他解释说,离职是为了聚焦于AI对齐和技术工作,并非因为OpenAI不支持对齐研究。舒尔曼感谢了在OpenAI的同事,并对它未来的发展“充满信心”。
而Anthropic正是由2020年离职的OpenAI的研究副总裁达里奥·阿莫蒂(Dario Amodei) ,和时任安全与政策副总裁丹妮拉·阿莫蒂(Daniela Amodei)兄妹创办的。
布罗克曼也在同月宣布休假一年,这是他自9年前共同创立OpenAI以来的“第一次长假”。
9月10日,领导OpenAI GPT-4o和GPT-5模型音频交互研究的亚历西斯·克努亚(Alexis Conneau)宣布离职并创业,克努亚的研究致力于实现电影《Her》中展示的那种自然语音交互体验,但相关产品的发布却一再延迟。
OpenAI自成立以来,就因其非营利和商业化的双重身份而备受关注。随着商业化化进程的加速,内部关于其非营利使命的紧张关系日益明显,这也是团队成员流失的一个原因。同时埃隆·马斯克(Elon Musk)最近的一起诉讼可能也与人员流失有关。
OpenAI研究员丹尼尔·科科塔洛(Daniel Kokotajlo)在离职后接受媒体专访时表示,去年发生的“宫斗”事件中,奥尔特曼被短暂解雇后迅速复职,专注于AGI安全的三名董事会成员被撤换。“这使得奥尔特曼和布罗克曼进一步巩固了权力,而主要关注AGI安全的人被边缘化。(奥尔特曼)他们背离了公司在2022年制定的计划”。
此外,OpenAI面临高达50亿美元的预计亏损,运营成本高达85亿美元,其中大部分为服务器租用和训练成本。为应对高昂的运营压力,OpenAI正在谋求新一轮融资,估值可能超过1000亿美元,微软、苹果和英伟达等潜在投资者表达了兴趣。公司高管正在全球范围内寻求投资以支持其快速发展的资金需求。
为了缓解财务压力,OpenAI正在寻求新一轮的融资,据《纽约时报》11日报道,OpenAI上周还希望以1000亿美元估值融资大约10亿美元。但因构建大型AI系统所需算力将导致更大开支,该公司近日决定调高融资额度到65亿美元。
但有外媒援引知情人士以及未公开的内部财务数据分析称,OpenAI今年可能面临高达50亿美元的巨额亏损,总运营成本预计达到85亿美元。其中向微软租用服务器的费用高达40亿美元,数据训练成本则是30亿美元。由于更先进的模型如Strawberry和Orion的运行成本更高,公司的经济压力进一步加大。
相关内容
- 2024-12-21 OpenAI重磅发布o3!再次突破AI极限,北大校友参与研发
- 2024-12-21 12天人工智能马拉松式直播结束,一口气看完OpenAI所有要点
- 2024-12-21 OpenAI第12天:新品o3发布会的8大看点,第5个让全球都坐不住了
- 2024-12-20 GPT开山一作被曝离职OpenAI,被Ilya感谢,ChatGPT无名英雄选择单飞
- 2024-12-20 阿尔特曼暗示OpenAI明日发布o3,新一代AI推理王者模型
点击排行
- 105-17OpenAI多位重量级高管离职,质疑再次涌向Sam Altman
- 203-07ChatGPT-Plus,AI 助手全套开源解决方案,自带运营管理后台,开箱即用。
- 306-22RTranslator: 全球第一个开源实时翻译应用程序
- 410-18诺奖得主哈萨比斯最新访谈:仅仅将AI视作一种技术是错误的
- 505-17马斯克称OpenAI最新模型慢得离谱
- 606-23OpenAI CTO:GPT-5可能会在2025年底或2026年初推出
- 706-23企业家自曝用了ChatGPT后裁员近1/10:管理效率大幅提升
- 805-17GPT-4o被全球网友玩坏了 谷歌:终究是错付了
- 906-23高通开放AI模型,助力开发者打造骁龙X Elite平台智能应用
- 1005-17谷歌Gemini AI 计划为学校提供额外的数据保护和隐私