中国首个音频生成类大模型通过备案
9月20日,近日,上海网信办发布的最新一批上海市生成式大模型备案通过名单中,喜马拉雅音频大模型与米哈游、阅文集团的筑梦岛等文本大模型共同通过了备案,成为全国首个通过网信办生成式人工智能服务的音频生成类大模型。
喜马拉雅音频大模型是全球首个第四代多情感演绎、超自然表达的音频生成大模型。该模型将会引领整个音频行业AIGC从第三代音频生成模型向第四代音频生成大模型的演化发展。
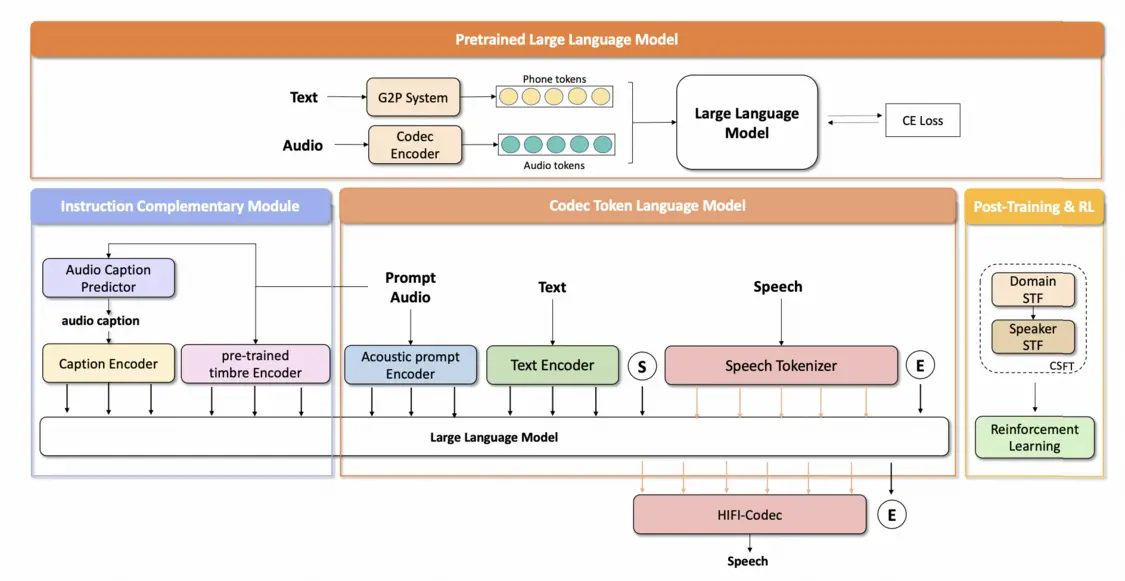
喜马拉雅音频模型是珠峰AI团队基于自研文本音频联合建模的LLM框架,在同一空间向量表征下实现音频与文本的联合建模训练。这种联合建模的方法充分赋予了音频生成任务以强大的语义信息,并充分利用它们之间的内在联系和互补信息,大幅度提高模型的性能和泛化能力,这也是第四代音频大模型超越上一代的核心技术突破。

在训练过程中,喜马拉雅珠峰AI首先将音频数据和文本数据分别进行预处理,将它们转化为适合模型输入的 token 形式,并将音频 token 和文本 token 映射到同一空间向量表征中,使得模型能够更好地理解和处理音频和文本之间的关系。整体训练流程包括预训练(Pretraining)、有监督微调(SFT)、领域有监督微调(Domain SFT)、说话人有监督微调(Speaker SFT)、强化学习(RL)几个主要流程。通过这几个流程的训练,使模型具备以下特点:(1)15s音色克隆能力和声音转换能力。(2)超拟人、多情感、对齐人类偏好的语音生成。(3)高可控风格和副语言能力。

喜马拉雅珠峰AI研发团队对训练好的模型进行评估,在长音频内容如有声小说的场景下,角色演绎风格的可控性、音素表现的稳定性、语流韵律停顿等的自然度上显著高于国内外第三代音频生成模型。
喜马拉雅音频大模型践行“产模结合”的范式,通过模型结合产业形成业务、数据、算法的正反馈循环。其在AIGC有声书、Chat对话式交互等业务场景上广泛使用,诸如最近爆火的有声书《我的阿勒泰》就是由喜马拉雅音频大模型生成的。喜马拉雅珠峰AI表示,音频大模型能力已经在珠峰AI官网上可以直接体验使用了,用户可以直接创作自己的音频内容。
相关内容
- 2024-12-13 字节跳动与北京大学成立豆包大模型联合实验室
- 2024-12-06 8位数年薪!“最懂阿里大模型的人”带整个团队跳槽加入字节跳动
- 2024-12-06 大模型创业“生死局”:融资困难、造血乏力、卖身离场
- 2024-11-30 AI现场发了2万红包,打开了大模型Act时代
- 2024-11-11 大模型发展遇困境,OpenAI等巨头寻求破局之道
点击排行
- 105-17OpenAI多位重量级高管离职,质疑再次涌向Sam Altman
- 203-07ChatGPT-Plus,AI 助手全套开源解决方案,自带运营管理后台,开箱即用。
- 306-22RTranslator: 全球第一个开源实时翻译应用程序
- 410-18诺奖得主哈萨比斯最新访谈:仅仅将AI视作一种技术是错误的
- 505-17马斯克称OpenAI最新模型慢得离谱
- 606-23OpenAI CTO:GPT-5可能会在2025年底或2026年初推出
- 706-23企业家自曝用了ChatGPT后裁员近1/10:管理效率大幅提升
- 805-17GPT-4o被全球网友玩坏了 谷歌:终究是错付了
- 906-23高通开放AI模型,助力开发者打造骁龙X Elite平台智能应用
- 1005-17谷歌Gemini AI 计划为学校提供额外的数据保护和隐私