AI要进步,居然得先学打游戏?
开了眼了,上周编辑部还在说下半年感觉 AI 领域没啥大活儿了,结果没过几天就发现话放早了。
宁猜怎么着,本来以为 AI 还停留在输入文字,然后出图出视频的这些程度上,结果这两天突然有几个 AI 公司,都开始宣布人家可以生成世界了。
我勒乖乖,这不就是 AI 界做梦都想搞出来的 “ 世界模型 ” 嘛:能像人一样理解这个真实世界的超级 AI !
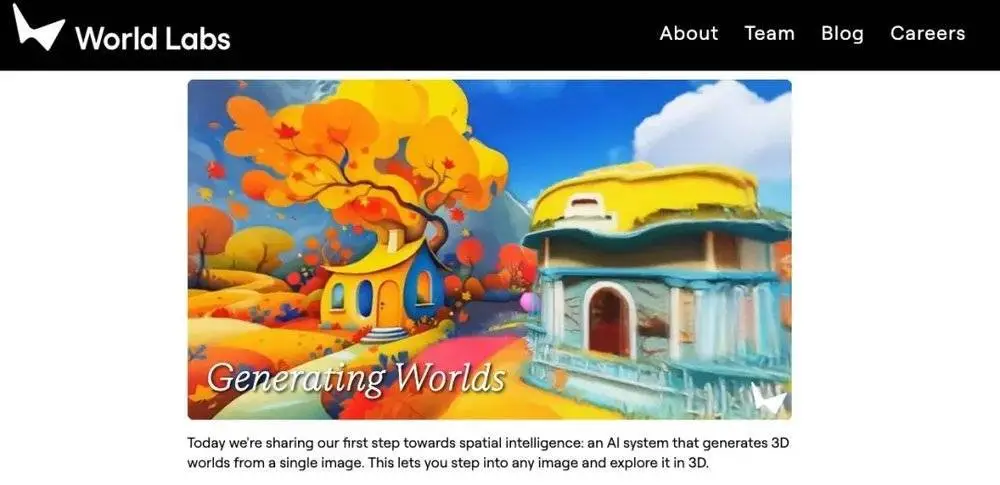
先是前几天的 World Labs ,虽然大家可能没听说过,但人家创始人可是著名 AI 科学家、斯坦福大学教授、美国科学院院士、机器学习奠基人之一、有 AI 教母之称的著名美籍华人科学家李飞飞。
在 World Labs 官网上说到,这是世界上第一个能直接渲染出完整 3D 场景的AI ,超越了传统生成模型的单纯像素预测,而且这场景还能有交互性和自由度。
说人话就是,这玩意跟以前的生图生视频模型不一样了,只需要塞给它一张图,人家就能给出一套空间建模,而且还能在里面动。

虽然现在咱们还没法用,但人家官网还是放出来一些案例给大家看。

大家一眼就会发现,这演示画面里咋有个键盘和鼠标。
其实就是人家为了展示这生成出来的场景是有自由度滴,你可以自己用键鼠操作,在网页上操作去试。
然而世超不建议大家去试,因为真的超卡,活动范围也不大,还容易晕……
不过作为行业内首发,咱也是可以理解万岁一波的。
但好巧不巧,李飞飞这东西发布才过了一天,还有高手。
谷歌 DeepMind 也出了一个 “ 世界模型 ” ,而且还是第二代,号称能理解真实世界的运作规律。世超也跑去他们官网看了一圈,瞅瞅这个 Genie 2 ,到底怎么个真实法。
先看人家的演示,输入一句提示词以后生成的效果。

该说不说,这瞅着确实也挺逼真的,有两下子。
不过要是跟上面 World Labs 的 AI 对比的话,估计大家一眼就会发现,这个好像更加流畅,自由度也更高些。
实际上人家官网也说了,这是一个类似游戏的基础世界模型,在这里面,你也一样可以用 WASD ,空格和鼠标来操控画面里的角色。

甚至还可以生成第一人称视角的版本!

而根据操作产生的画面,则全部是由 AI 即时算出来的,甚至可以持续长达一分钟时间。

而已经生成出来的画面和建模,你要是操控键盘往回走,会发现之前是什么样现在还是什么样。

这就很离谱了,相当于生成出来的这个新世界,每一秒长啥样这 AI 都是能记得住的。
除此之外,这里面的角色和交互也很有看点。
光在运动上,就不止常规的步行,你可以跑可以跳,还可以爬梯子。


甚至可以开车,还可以开枪射击。


而里面 AI 生的 npc 们,也是可以发生交互的。

虽然这交互效果有点不尽人意,但还是能看出来动了的。
而在整个场景中,跟自然相关的运动场景也能搞出来。
就比如水面:

还有烟雾:

还包括了重力和光线反射效果:


哪怕你给出现实中的照片,它也能跟着模拟一下周围的环境,瞅着跟谷歌地图的街景似的。

虽然视觉效果着实挺牛逼的,不过,跟李飞飞那个一样, DeepMind 的新模型也没有给出来让大家上手试,只在官网发布的他们测试的版本。
但根据世超平时测试这些 AI 的经验嘛,甭管是大厂还是新势力,官方给出来的演示那肯定都是精挑细选的好看的案例,真正要用的话,那估计还得降低一个级别的期待值。
不过这次比较好玩的是, DeepMind 也很实诚的说,他们这个还是一个早期的版本,自己测试的时候也会出现一些翻车案例。
就比如下面这个,本来说让画面里的小哥滑雪,结果 AI 给他搞成了跑酷。

还有一个花园的场景,玩家还没操作呢,啥都没动,结果花园里突然飘过了一个幽灵……

虽然还有瑕疵,但是就从他们给的这些演示上,世超觉得这确实是在 AI 理解世界这方面,取得了比较成功的进步。
有聪明的差友可能这时候就要问了,这种跟随一个主体运动的画面,以前的 Sora 类视频模型不也能做到嘛,凭啥这个就更接近世界模型?
其实还是跟训练 AI 的方向有关系。
Sora 虽然刚出来的时候号称世界模型,但是实际这些视频模型穿模的情况还是很多的,幻觉也不太好解决。
本质上他们学习的资料都是视频,靠前面视频的画面去推后面的,并不真的理解视频里的东西是怎么交互,怎么作用的。
就比如说,让 AI 从看视频里学到物体有重量,是相当困难的。

而要让 AI 意识到这些真实世界里的参数,它首先就得知道环境是一回事,环境里的人和物是另一回事,所以大家才从文生图模型,一步步走向了生成地理环境,而后在环境内去呈现人的动作。
这也就是李飞飞 World Labs 的模型的效果,相当于先让 AI 学会建模,再展示看到的场景。
但相比上面 World Labs , DeepMind 显得更厉害一点,这其实跟他们的技术路线不一样有点关系。如果说前一个是打算用图片来还原更真实的场景,后一个则是用 AI 给你生成了一个游戏世界。
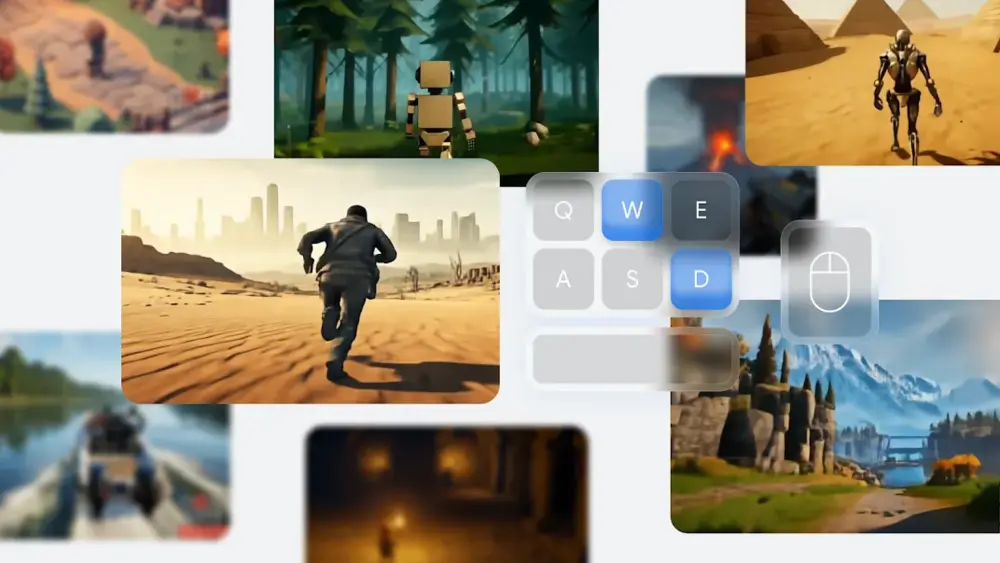
当然他们之所以能搞出来,主要人家在训练的时候就是按游戏素材来学习的。
相比视频素材,游戏的好处就在于 ai 不仅能学到角色和画面的动态变化,也能观察到角色动作的键盘操作,是如何影响画面和动作变化的,这样它就对物体与环境的交互理解的更全面。
实际上,早在今年三月, Genie 团队就已经出来一个版本,不过那时候他们做的还是 2d 画面的横屏 AI 游戏。
结果到了 2.0 版本,人家给 3d 的整出来了,实际效果看起来也非常接近大家平时玩的这些 3d 游戏,甚至比一些游戏的画面质量还要好一点。

不过呢,咱也不是说 DeepMind 就发现了 AGI 的通用解,演示中表现的还行也不等同于 AI 就真的理解现实。
最明显的原因就是,这 AI 是靠游戏学的,而游戏是人类根据现实来做的。靠人类的二手资料学的再好,也绝不等同于对真实世界的理解无误。
至于 AGI 啥时候真来,咱还是得说句,再等等。
相关内容
- 2024-12-11 百度要做AI版富士康?
- 2024-12-11 2024年度AI十大趋势报告发布,从这三个维度揭晓
- 2024-12-08 外媒:张一鸣全力押注AI,亲自监督招聘高端人才
- 2024-12-07 SaaS不会被AI颠覆,而是加速鞭策
- 2024-12-07 字节AI凶猛上位
点击排行
- 105-17OpenAI多位重量级高管离职,质疑再次涌向Sam Altman
- 203-07ChatGPT-Plus,AI 助手全套开源解决方案,自带运营管理后台,开箱即用。
- 306-22RTranslator: 全球第一个开源实时翻译应用程序
- 410-18诺奖得主哈萨比斯最新访谈:仅仅将AI视作一种技术是错误的
- 505-17马斯克称OpenAI最新模型慢得离谱
- 606-23OpenAI CTO:GPT-5可能会在2025年底或2026年初推出
- 706-23企业家自曝用了ChatGPT后裁员近1/10:管理效率大幅提升
- 805-17GPT-4o被全球网友玩坏了 谷歌:终究是错付了
- 906-23高通开放AI模型,助力开发者打造骁龙X Elite平台智能应用
- 1005-17谷歌Gemini AI 计划为学校提供额外的数据保护和隐私