OpenAI活动第二弹:“强化微调”打造领域专家AI模型,阿尔特曼称其为今年最大惊喜
更新时间:2024-12-07 19:19:35
编辑:管理员
浏览:28
OpenAI活动第二弹:“强化微调”打造领域专家AI模型,阿尔特曼称其为今年最大惊喜

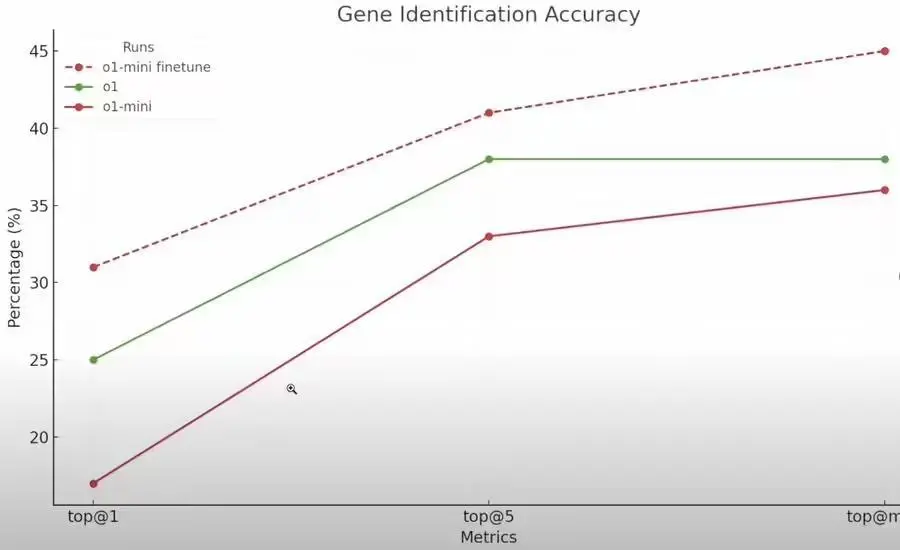
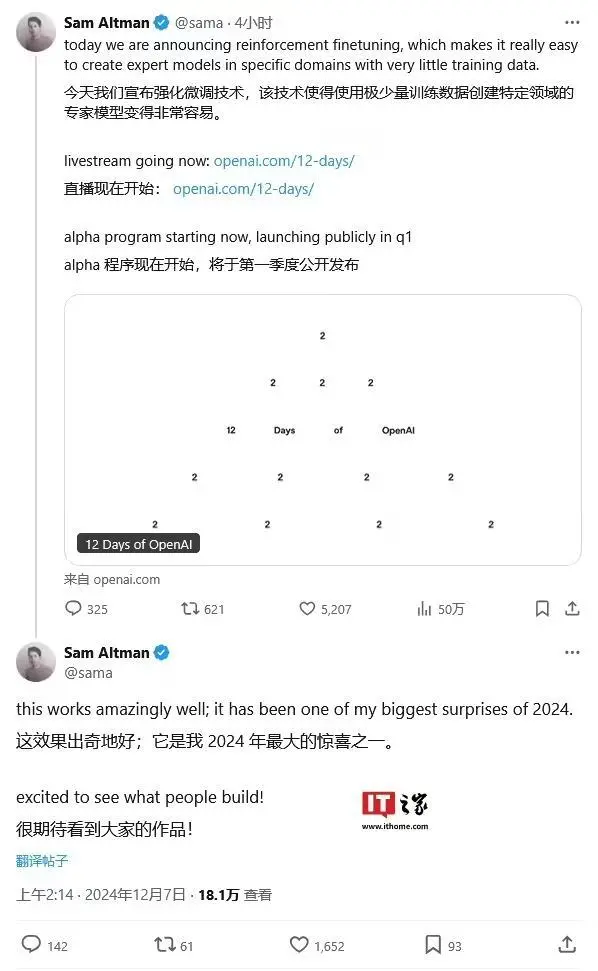
相关内容
- 2024-12-12 OpenAI就ChatGPT宕机致歉:部分服务已恢复,Sora仍为瘫痪状态
- 2024-12-12 OpenAI深夜被狙,谷歌Gemini 2.0掀翻牌桌!最强智能体组团击毙o1
- 2024-12-12 OpenAI ChatGPT全球范围内宕机,苹果iOS 18.2 Siri受牵连
- 2024-12-12 OpenAI发布会第五天:全智能生态不是概念,这或许是AI手机的样子
- 2024-12-12 谷歌深夜祭出Gemini2.0“硬刚”OpenAI,Agent时代最强模型登场了?
点击排行
- 105-17OpenAI多位重量级高管离职,质疑再次涌向Sam Altman
- 203-07ChatGPT-Plus,AI 助手全套开源解决方案,自带运营管理后台,开箱即用。
- 306-22RTranslator: 全球第一个开源实时翻译应用程序
- 410-18诺奖得主哈萨比斯最新访谈:仅仅将AI视作一种技术是错误的
- 505-17马斯克称OpenAI最新模型慢得离谱
- 606-23OpenAI CTO:GPT-5可能会在2025年底或2026年初推出
- 706-23企业家自曝用了ChatGPT后裁员近1/10:管理效率大幅提升
- 805-17GPT-4o被全球网友玩坏了 谷歌:终究是错付了
- 906-23高通开放AI模型,助力开发者打造骁龙X Elite平台智能应用
- 1005-17谷歌Gemini AI 计划为学校提供额外的数据保护和隐私