智谱开源文生图模型CogView3-Plus,相关功能上线智谱清言App
更新时间:2024-10-14 22:23:55
编辑:管理员
浏览:86
智谱开源文生图模型CogView3-Plus,相关功能上线智谱清言App
10 月 14 日消息,智谱技术团队今天宣布开源文生图模型 CogView3 及 CogView3-Plus-3B ,该系列模型的能力已经上线“智谱清言”App。

据介绍,CogView3 是一个基于级联扩散的 text2img 模型,其包含如下三个阶段:
第一阶段:利用标准扩散过程生成 512x512 低分辨率的图像。
第二阶段:利用中继扩散过程,执行 2 倍的超分辨率生成,从 512x512 输入生成 1024x1024 的图像。
第三阶段:将生成结果再次基于中继扩散迭代,生成 2048×2048 高分辨率的图像。
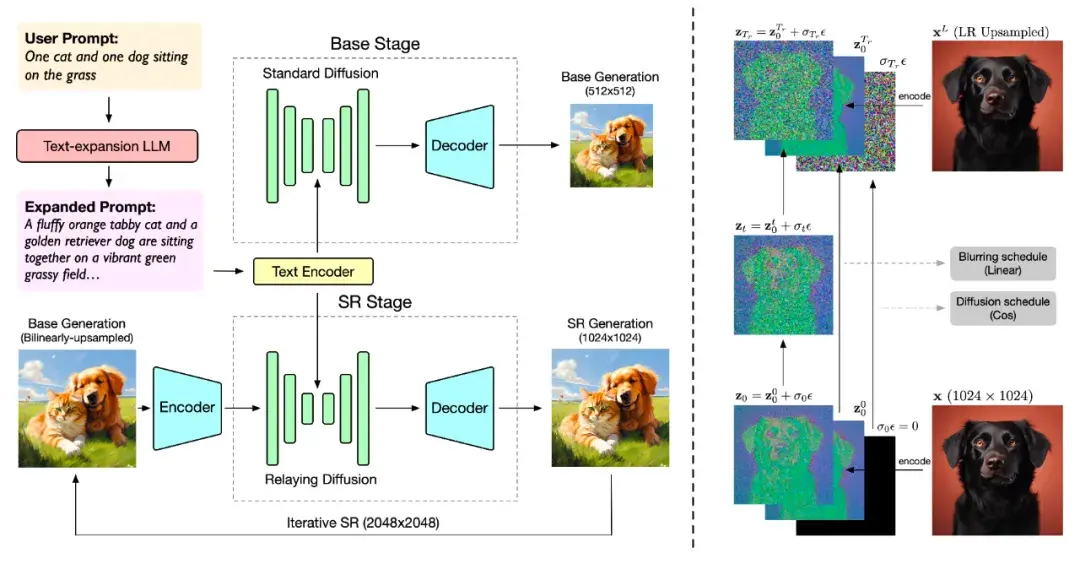
官方表示,在实际效果上,CogView3 在人工评估中比目前最先进的开源文本到图像扩散模型 SDXL 高出 77.0%,同时只需要 SDXL 大约 1/10 的推理时间。
CogView3-Plus 模型则在 CogView3(ECCV'24)的基础上引入了最新的 DiT 框架,以实现整体性能的进一步提升。据介绍,其采用 Zero-SNR 扩散噪声调度,并引入了文本-图像联合注意力机制。与常用的 MMDiT 结构相比,它在保持模型基本能力的同时,有效降低训练和推理成本。CogView-3Plus 使用潜在维度为 16 的 VAE。


IT之家附地址如下:
开源仓库地址:
https://github.com/THUDM/CogView3
Plus 开源模型仓库:
https://huggingface.co/THUDM/CogView3-Plus-3B
https://modelscope.cn/models/ZhipuAI/CogView3-Plus-3B
相关内容
- 2024-12-16 清华系出手!全球第一款端侧全模态理解模型开源
- 2024-12-11 LG发布EXAONE 3.5开源AI模型:长文本处理利器、独特技术有效降低“幻觉”
- 2024-12-07 Meta今年压轴开源AI模型Llama3.3登场:700亿参数,性能比肩4050亿
- 2024-11-28 推理水平对标OpenAI o1!阿里云开源首个AI推理模型QwQ:数学、编程尤为出色
- 2024-11-12 谷歌说到做到 诺贝尔奖AI成果AlphaFold3重磅开源!人人皆可免费下
点击排行
- 105-17OpenAI多位重量级高管离职,质疑再次涌向Sam Altman
- 203-07ChatGPT-Plus,AI 助手全套开源解决方案,自带运营管理后台,开箱即用。
- 306-22RTranslator: 全球第一个开源实时翻译应用程序
- 410-18诺奖得主哈萨比斯最新访谈:仅仅将AI视作一种技术是错误的
- 505-17马斯克称OpenAI最新模型慢得离谱
- 606-23OpenAI CTO:GPT-5可能会在2025年底或2026年初推出
- 706-23企业家自曝用了ChatGPT后裁员近1/10:管理效率大幅提升
- 805-17GPT-4o被全球网友玩坏了 谷歌:终究是错付了
- 906-23高通开放AI模型,助力开发者打造骁龙X Elite平台智能应用
- 1005-17谷歌Gemini AI 计划为学校提供额外的数据保护和隐私