我用Sora建了几个三维模型,证明它懂“世界”
我犯了个错,我倾向于认为Sora并不特别理解“物理世界”,纯二维图像与视频的训练和生成,也会让它缺失三维信息。
不过,从周末开始,大量的信息就一直在冲击着我的想法,我从假设模型“不懂”世界,转变成假设模型“懂”世界,于是,我用Sora官方的视频,尝试建了几个三维模型。
首先,我选取了四段有代表性的视频,特征都是:场景相对固定,运镜速度较慢,主角不是特写镜头或者主角变化很小。
其次,我按照3-5倍(如果原视频每秒24帧,那么差不多一秒钟采6-8帧)的采样率将视频转换为一帧帧的图片。
最后,我利用自己已经成熟的三维建模流程重建视频对应的“世界”场景。
先分别展示四个模型的原视频和三维模型,然后再说结论。
场景一:海边城镇
原视频一共20S,鸟瞰视角。

采样后,150张图片。
三维模型(工具界面中拖拉拽,放大缩小,变换视角等操作的截屏,后同)

结果:我们把这个海边城镇还原了。虽然有很多细节上的问题,但是对于我这种不可能徒手画出城镇三维模型的人而言,模型解决了我唯一无法实现的一步。
场景二:淘金热时的村庄
原视频场景明显大于前一个,而且镜头变化速度很快,视频25秒。

采样后,188张图片。
三维模型,建模前以为效果不会太好,但结果居然还是有亮点。

整个村庄的地理地貌结构是清晰的,中间缺失的部分在目前的游戏引擎里都很容易补全。很多房屋结构是完整的,表面因为镜头移动过快而造成的不平整,现在的模型都可以修正。也许,就是几天时间,一个“淘金热”的游戏就好了。
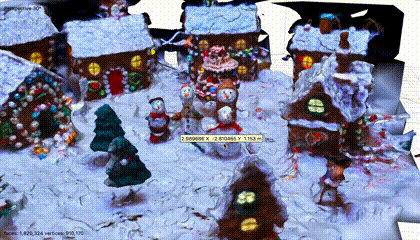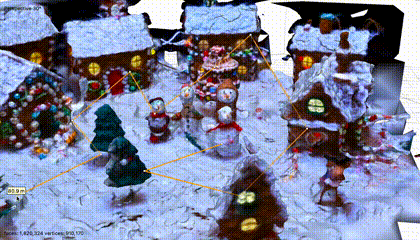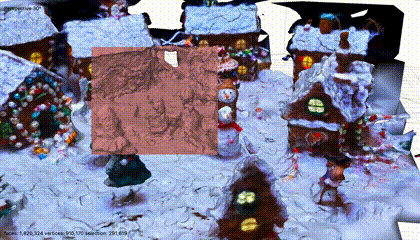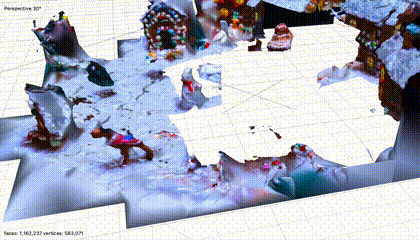
场景三:圣诞气氛的近景
原视频17s,场景固定,没有运动物体,镜头围绕物体旋转,焦段没有变化。

采样后,128张图片。
三维场景,不出意外,质量显然是最高的。

静态场景和物体,旋转运镜,正常三维建模经常采取的方法,所以,结果不意外。
场景四:赛博朋克
原视频20秒,虽然都是机器人为主角,但是机器人的头是转动的,场景也有变化。

采样后,149张图片。
三维模型,原视频是有三个视角的,所以模型自动也变成三个场景。



每个场景都有不少缺失,这是自然的,变化速度太快了,但是,如果我们就用Sora做个demo,然后生成许多幕戏的场景,同样的游戏引擎优化,加入追光效果。也许影视业的核心竞争力还是那几项:剧本、演员、特效。但是,可能场务、服装、道具,等等,我不敢想。
结论
1、选择的四段Sora官方视频,都顺利重建了三维模型。在目前的流程下,人工操作已经很少。虽然因为画质、场景变化速度偏快,物体移动、视角不完整等各方面原因,各模型都有明显的缺失。但是这些视频毕竟不是为了三维建模用的,如果以后可以专门通过prompt控制场景,运镜呢?相信效果一定会再有质的提升。
2、生成的是“真三维”,如下动图所示,可以测距(比例尺是可以预设的),测角度,可以导入CAD软件,也可以导入Unity、Unreal Engine等游戏引擎,可以编辑。以前,需要专业设计师在工具里花费很长时间手工建模的过程,也许,真的可以完全自动化了,至少,建模的过程证明,这走得通了,而且随着模型的快速进步,质量会越来越好。
3、我相信,Sora目前一定不是通过建立三维模型再去生成视频的,至少在模型架构上不是的。但是,建模的结果已经很清楚的证明了Sora技术报告里描述的“三维一致性”。我使用的是最严格的“像素级”摄影测量学模型(感兴趣的,可以移步我的一篇长文从摄影测量学到高斯渲染(1):顶级三维成像系统DIY踩坑记(二)),空间不一致的物体是无法被构建的。虽然,我以前倾向于拒绝承认,但是,很不幸,这样的结果让我找不到任何拒绝“Sora懂世界”假设的证据,甚至,这不是无法证伪,这是证实。
4、假以时日,Sora这样的生成器+适当的prompt+三维重建模型,可以构建整个世界,只要算力足够。
5、这些三维模型是可以直接导入到游戏引擎的,如今游戏引擎也已经广泛应用于影视特效制作、数字孪生等领域。如果把Sora仅仅看作文生视频,那么它或许无法在短期取代相关岗位,但如果Sora可以这样生成三维,那么这些岗位被取代就在眼前了。
6、还差什么?数据。Sora是人造的生成器或者说仿真器,我们会希望它生成的接近人肉眼所见,所以,一方面,苹果Vision Pro的价值之一是告诉大家这个分界线大概是8K分辨率,8K分辨率不是训练更高分辨率的图片那么简单,而是可能要有多的多的描述细节的高质量图片,要能描述整体和局部之间的关系,这也会反过来再挑战算法;另一方面,目前看起来,也只有更多数据,更大规模的模型,才可以让很多生成的物体与运动更接近物理规律。在这个意义上说,现存的那些海量数据或许价值是下降的,系统性的采集甚至合成数据重要性是大幅提升的,大家都有机会,但是背后巨大的投入是惊人的。到了这一步,可能每提升一倍能力,就是要十倍甚至百倍的投入。
7、曾经,我认为自己是相对中立的,我相信模型的神奇,但又保持着碳基的自尊心。如今,我只剩下复杂的心情。正好跟朋友聊起我的发现,对方说了一句“也许模型看到的根本不止三维呢?”。
也许呢?
相关内容
- 2024-12-18 Pika 2.0横扫Sora惊艳全网,一键颠覆广告业!
- 2024-12-17 4K视频生成!Google版Sora深夜秀肌肉,再度狙击OpenAI
- 2024-12-13 Sora迟到的这十个月,不少老外已经“移情别恋”了
- 2024-12-12 OpenAI就ChatGPT宕机致歉:部分服务已恢复,Sora仍为瘫痪状态
- 2024-12-12 Sora终于来了,但多模态AI呼唤实用主义
点击排行
- 105-17OpenAI多位重量级高管离职,质疑再次涌向Sam Altman
- 203-07ChatGPT-Plus,AI 助手全套开源解决方案,自带运营管理后台,开箱即用。
- 306-22RTranslator: 全球第一个开源实时翻译应用程序
- 410-18诺奖得主哈萨比斯最新访谈:仅仅将AI视作一种技术是错误的
- 505-17马斯克称OpenAI最新模型慢得离谱
- 606-23OpenAI CTO:GPT-5可能会在2025年底或2026年初推出
- 706-23企业家自曝用了ChatGPT后裁员近1/10:管理效率大幅提升
- 805-17GPT-4o被全球网友玩坏了 谷歌:终究是错付了
- 906-23高通开放AI模型,助力开发者打造骁龙X Elite平台智能应用
- 1005-17谷歌Gemini AI 计划为学校提供额外的数据保护和隐私