ChatGPT和Sora其实限制了我们对大模型的想象?
最近一份美国市场研究机构发布的报告火了。报告详细分析了OpenAI部署Sora所需的硬件资源,计算得出,在峰值时期Sora需要高达72万张英伟达H100 来支持,对应成本是1561亿人民币。
同时,还有一条新闻也在刷屏。一名微软的工程师爆料,为了训练GPT-6而搭建了10万个H100,结果却把电网直接搞崩了。
而且这些新闻让关心大模型的人们开始嘀咕:
费这么大劲把地球资源都耗尽了,就为生成几个文字,生成几个视频,真的值得吗?
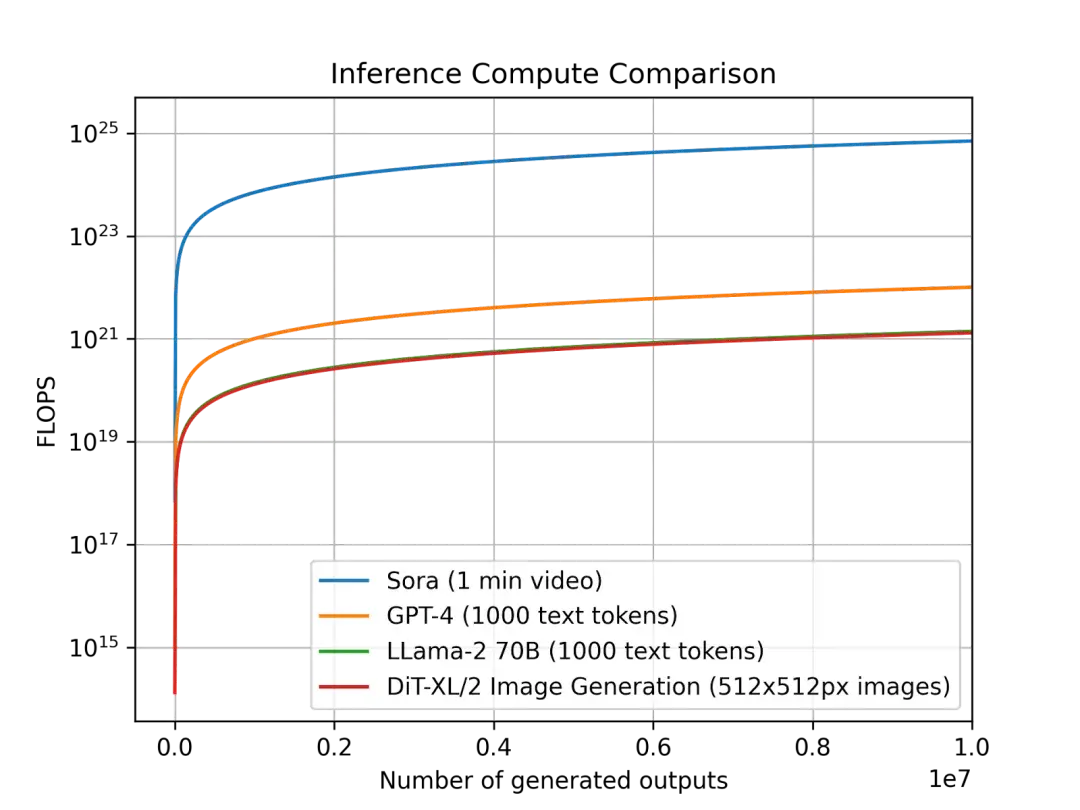
(图源:Factorial funds)
其实,某种程度上,ChatGPT和Sora限制了人们对大模型的想象力——
生成文字可以“通过预测下一个token就理解世界”,生成视频可以变成“理解物理世界的引擎”,于是所有资源都投入到生成文字与图像上去。
但,大模型的想象力就这样了吗?
不看不知道,行业大模型已经有多强
最近行业里流传的一系列有趣的案例,大大突破了ChatGPT和Sora提供的样本,给大家看到了生成式AI更多的想象空间。
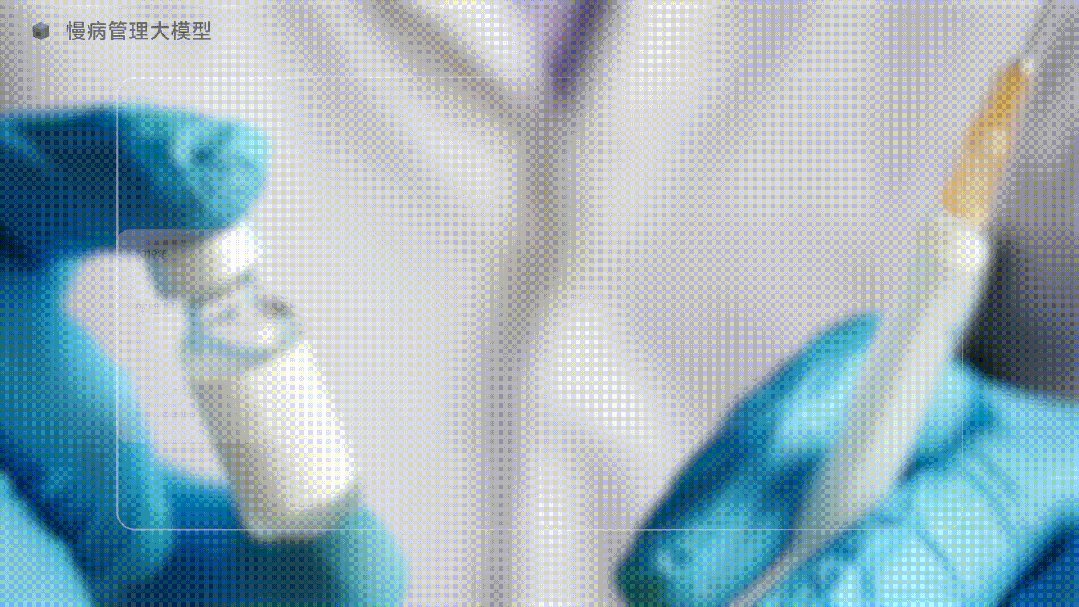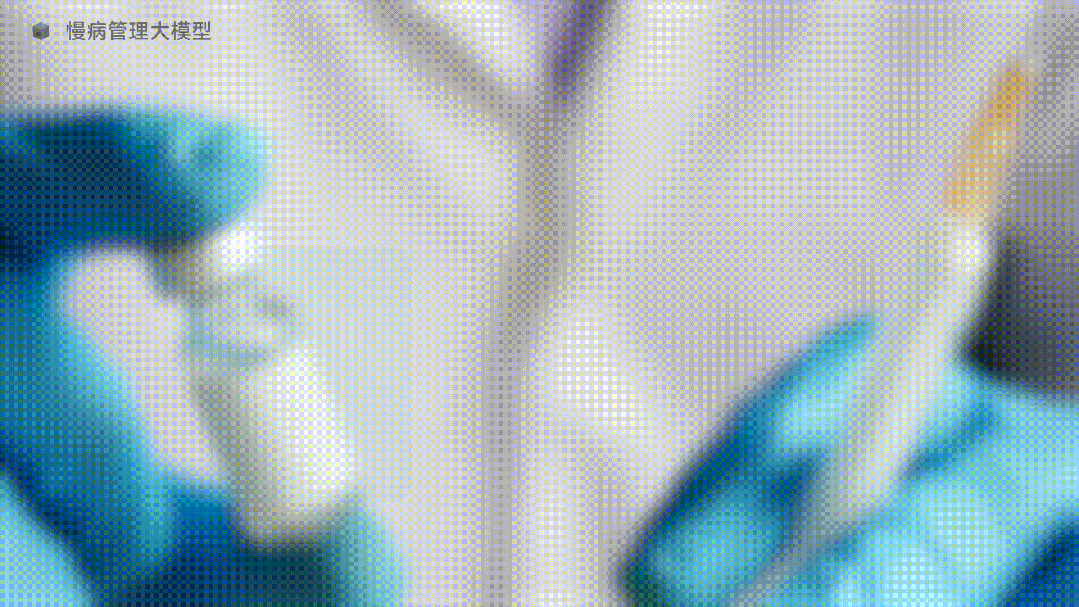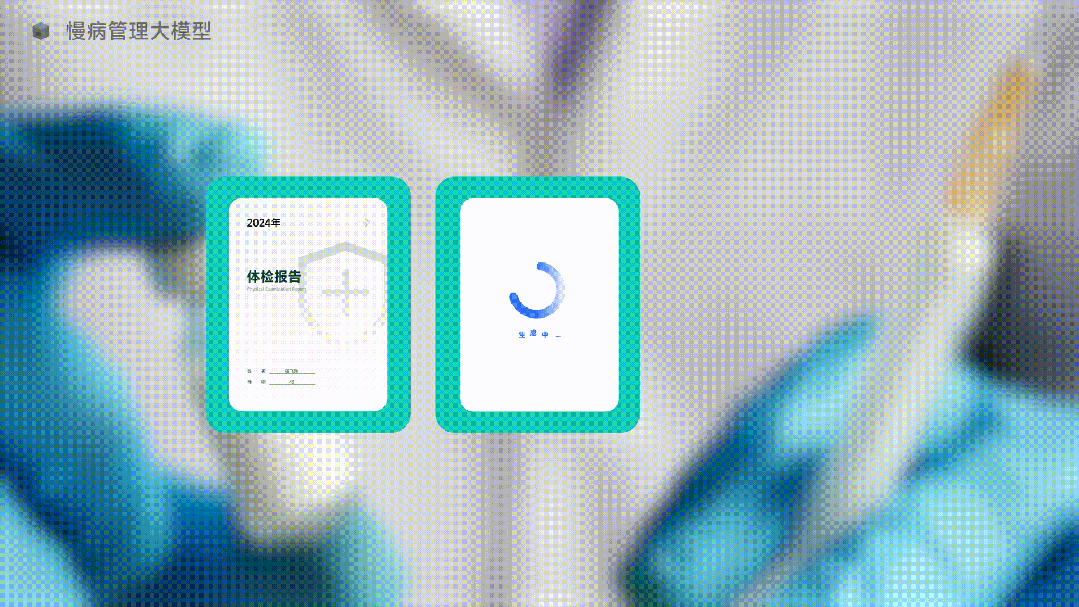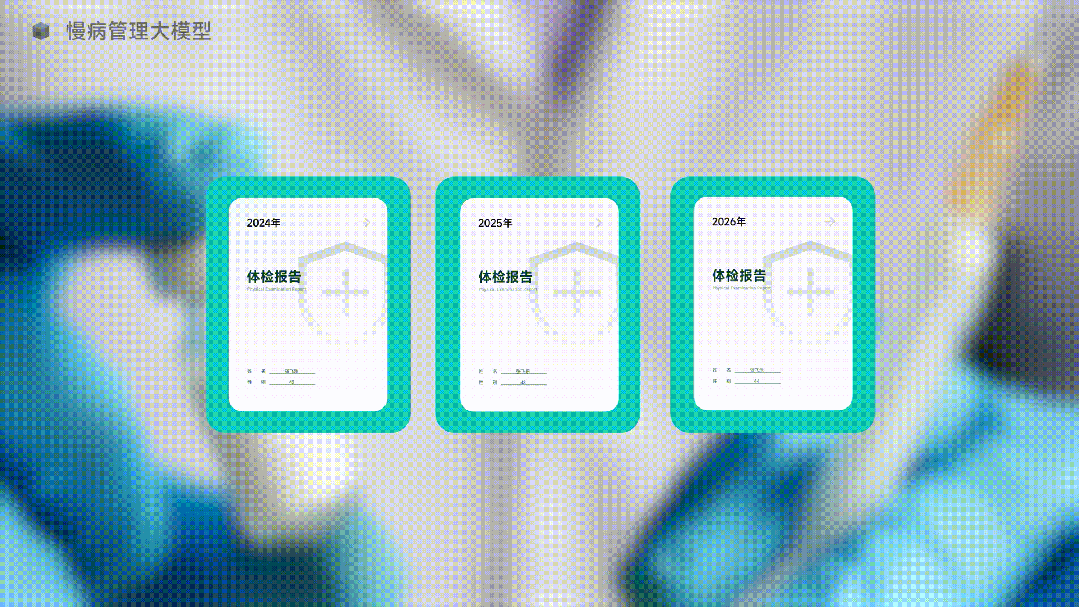
图中是一个AI正在生成体检报告,是的,它在生成“未来”的体检报告。
在健康管理行业,如何更早的对人们的健康状况作出风险预警,是个关键的问题。
那么,既然生成式AI这么强大,让AI直接生成未来的体检报告如何?
AI还真的就给你生成了。未来的体检结果让你必须重视。

不只是人类体检报告,AI还可以生成复杂的水电机组的未来“体检报告”。
可以看到,AI直接给出了具体的时间,精确到分钟的运行状况,提示可能发生的高温故障。
提示老师傅检查,并调整检测和运行的策略。
这些案例就来自AI公司第四范式在产业界的一些实践。这些行业大模型基于一个叫做先知AIOS的行业大模型平台,涵盖各类AI 模型的开发、纳管和应用,这个平台已经进化到了 5.0版。
AI生成一切,一切AI都是生成
敏锐的读者一定已经发现,这些神奇的案例有个共同特点:
其实它们都在“Predict the next X”。而这个X,不只是ChatGPT等大语言模型在处理的“语言”,而是更多更丰富的各个行业的X模态数据。
某种程度上,ChatGPT证明使用大量数据进行预训练,然后以“Predict the next token”的方式,是可以产生智能的。而Sora则证明了这种“Predict the next X”的方式不应只局限在token代表的文本数据。
ChatGPT和Sora的出现,都证明了“Predict the next X”这个路线的正确。
因此进一步打开想象空间和发挥大模型价值的方向,就是让“Predict the next X”里的X,这一未知数的指代形式不断扩展延伸。
这个X,可能是体检报告、水文数据,可能是监测数值和应急预案。这些行业的大模型,需要行业里很多形态的数据,很强的行业知识,最终去生成特定行业的X。
比如下面这个垂直行业从业者开发的声效大模型。
当你要为一个音乐厅设计最佳的声音体验时,只需要让这个行业大模型去生成不同方案下的声音方案,让它提供具体的数据,并用直观的图像展示出来。
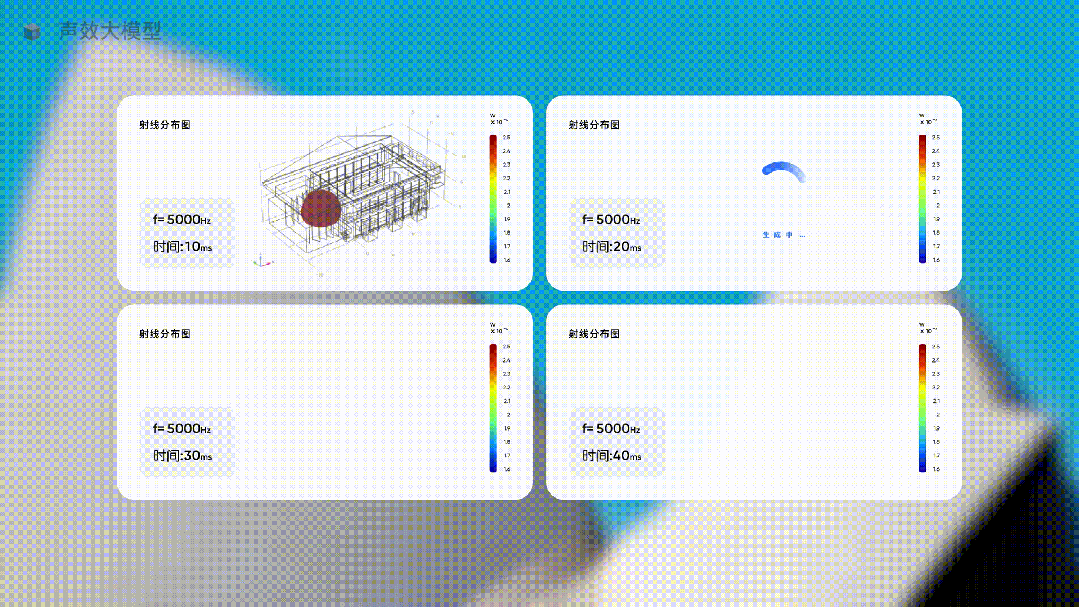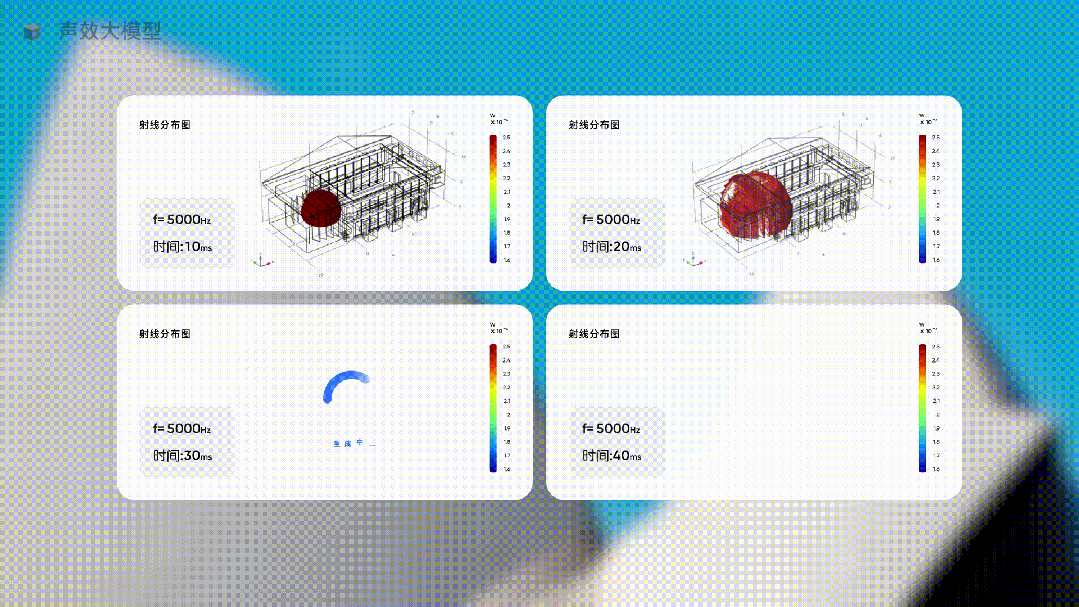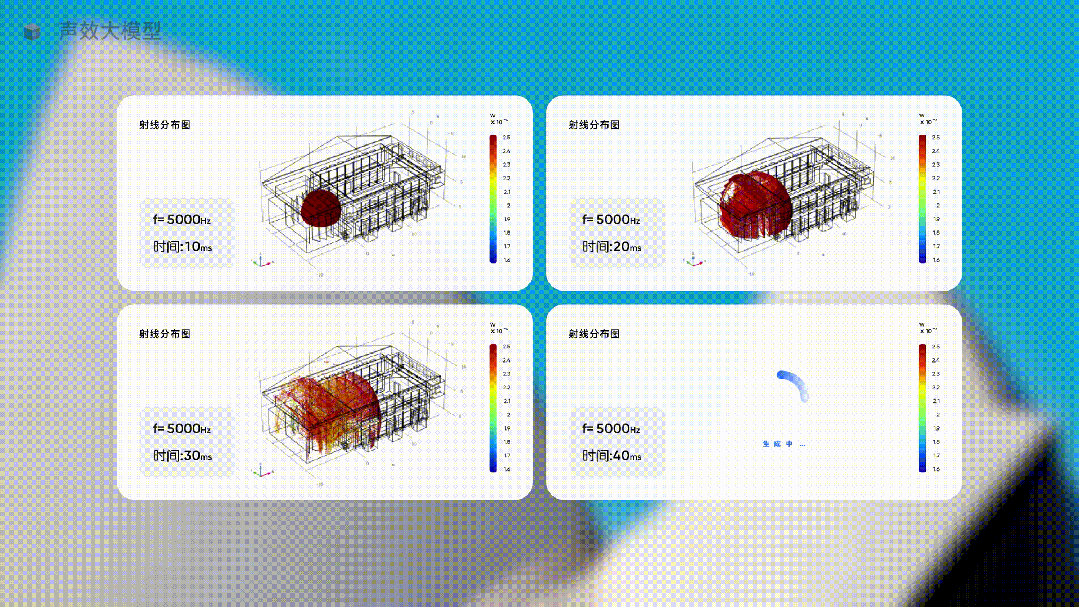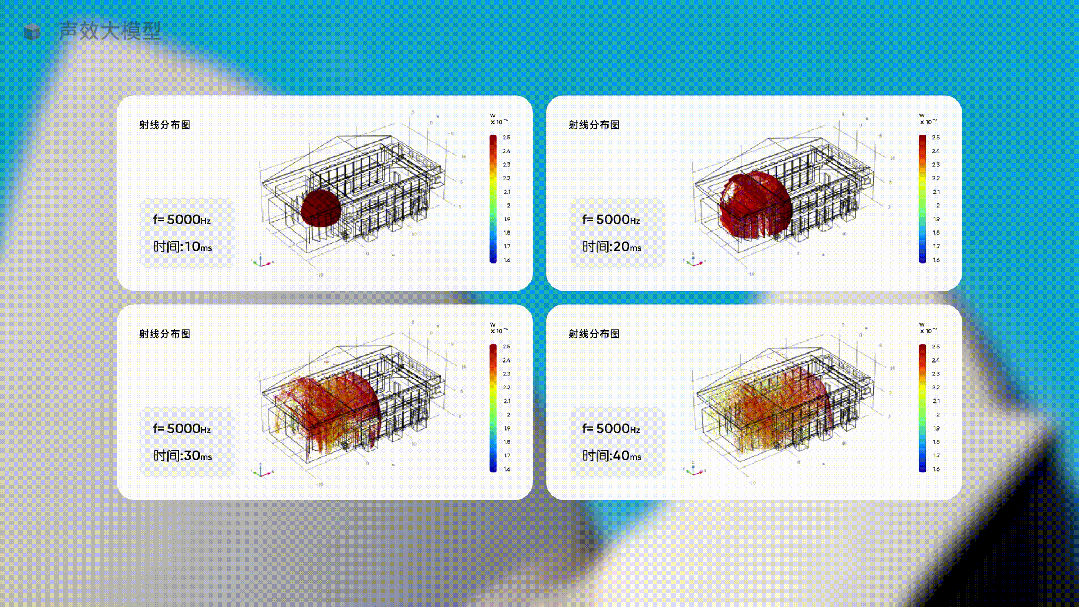
这种生成声音体验,完全无法用预测下一个单词的方式,但在使用大量声音行业的专有形态和特殊的数据训练一个行业大模型后,就这样被生成了。
而要开发这样的模型,一个重要前提显然是把主动权交给各行各业的从业者,让专业的知识和数据发挥作用。
他们需要的可能不是一个传统的大语言模型,不是基于大语言模型微调行业数据,而是真正基于自己行业里不同形态的数据训练出的基座大模型。
第四范式的AIOS 5.0可以接受各种各样的“X”,再基于这些X构建对应的垂直行业大模型,以他们的话说——“种瓜得瓜,种豆得豆。”语文模型解不了数学题。
其实,这样的思路已经被越来越多的重要公司所接受。就连OpenAI也不认为最终会有一个万能的大模型来解决一切问题。OpenAI COO最近在一场论坛上表示,“你当然不需要一个一体化模型来解决所有问题。人们应该根据具体使用场景动态调用不同的模型,从而更好地分配智能资源。”
所以,不要被ChatGPT和Sora 所局限了,“Predict the next X”的X应该有更多的可能性。而这些可能性只会从各个行业里发芽生长起来,当它们连成一片,AGI可能会更快到来。
相关内容
- 2024-12-20 GPT开山一作被曝离职OpenAI,被Ilya感谢,ChatGPT无名英雄选择单飞
- 2024-12-19 ChatGPT里走不出具身智能,为什么?
- 2024-12-18 Pika 2.0横扫Sora惊艳全网,一键颠覆广告业!
- 2024-12-17 4K视频生成!Google版Sora深夜秀肌肉,再度狙击OpenAI
- 2024-12-16 月薪1万4的ChatGPT要来了!OpenAI自曝其达博士级别
点击排行
- 105-17OpenAI多位重量级高管离职,质疑再次涌向Sam Altman
- 203-07ChatGPT-Plus,AI 助手全套开源解决方案,自带运营管理后台,开箱即用。
- 306-22RTranslator: 全球第一个开源实时翻译应用程序
- 410-18诺奖得主哈萨比斯最新访谈:仅仅将AI视作一种技术是错误的
- 505-17马斯克称OpenAI最新模型慢得离谱
- 606-23OpenAI CTO:GPT-5可能会在2025年底或2026年初推出
- 706-23企业家自曝用了ChatGPT后裁员近1/10:管理效率大幅提升
- 805-17GPT-4o被全球网友玩坏了 谷歌:终究是错付了
- 906-23高通开放AI模型,助力开发者打造骁龙X Elite平台智能应用
- 1005-17谷歌Gemini AI 计划为学校提供额外的数据保护和隐私