清华首款AI光芯片登上Science,全球首创架构迈向AGI
巨耗算力大模型,离通往AGI目标又近了一步。清华团队首创AI光芯片架构,研制全新「太极」实现了160 TOPS/W通用智能计算,能效竟是H100的1000倍。
训练下一代万亿级参数大模型的高效芯片诞生了!
最近,来自清华团队的研究人员开发了一种革命性的新型AI「光芯片」——「太极」(Taichi)。
不言而喻,「太极」最大的亮点是使用光,而不是电来处理数据。
与传统堆叠PIC芯片方法不同,清华团队首创了分布式广度智能光计算架构,使得「太极」成为全球首款大规模干涉衍射异构集成芯片。

「太极」具备了亿级神经元的芯片计算能力,可以显著提高处理速度和能效。
它可以实现160 TOPS/W通用智能计算。
最新研究已于4月11日发表在Science期刊上。

论文地址:https://www.science.org/doi/10.1126/science.adl1203
更令人震惊的是,「太极」能效是英伟达H100的1000倍数。
研究人员表示,「太极」为大规模的光子计算和高级任务铺平了道路,进一步发掘了光子学在现代AGI中的灵活性和潜力。
ChatGPT耗电大有解了
当前,越来越多迹象表明,LLM不会是通往AGI的最终路径。
那是因为,基于Transformer架构的大模型,通过token预测完成推理,需要消耗大量的算力。
此前ChatGPT日耗电50万度,曾被网友们吵上热搜。

若是能够发明一种,节省大量能耗的芯片,LLM的性能或在未来实现更大的飞升。
而「太极」可能会使通用人工智能(AGI)成为现实。研究人员表示,
我们预计,「太极」将加速开发更强大的光学解决方案,为基础模型和AGI新时代提供关键支持。
在将计算能力提升到AGI所需的水平方面,「太极」的模块化设计可能是一个关键优势。
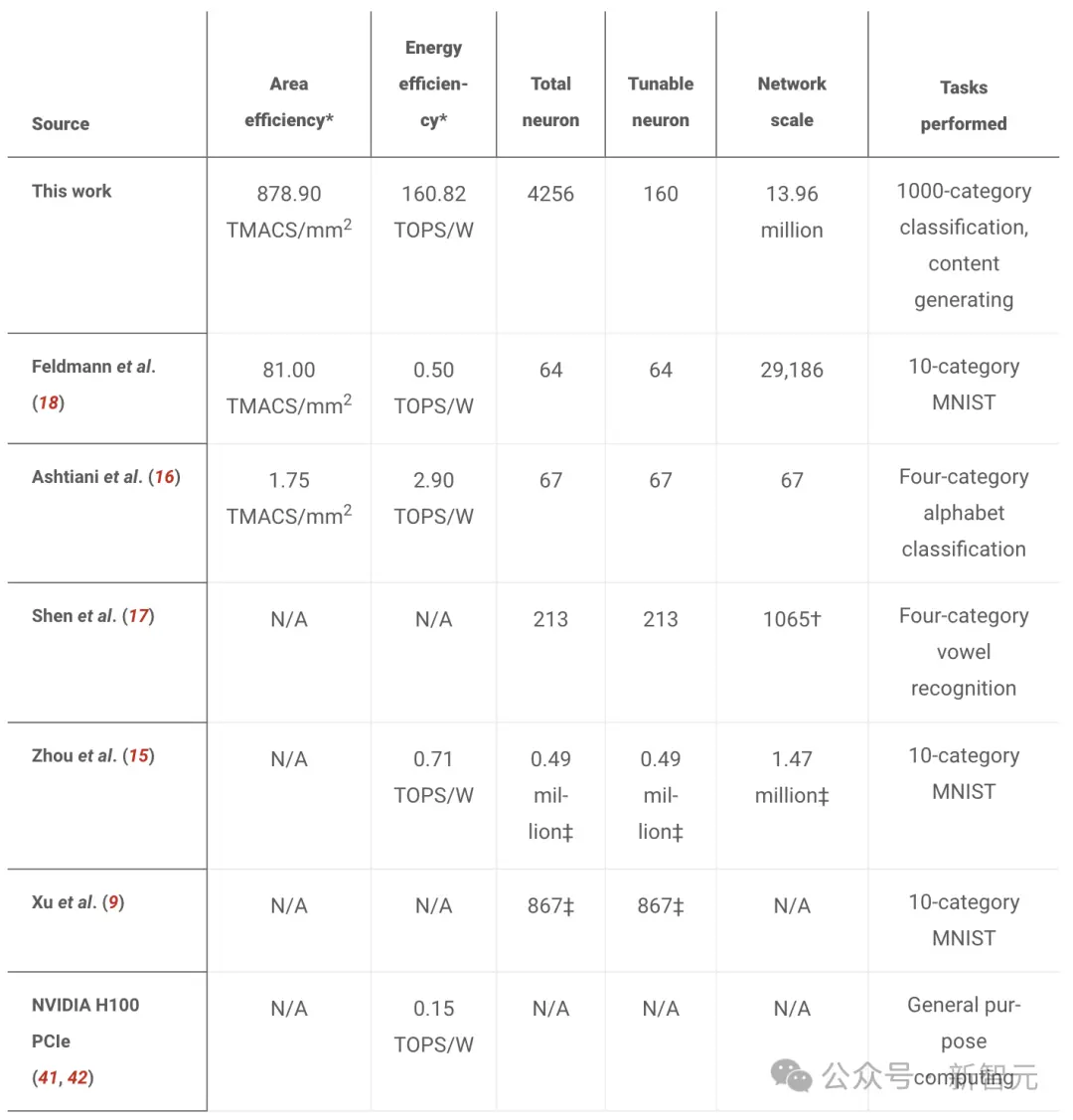
清华团队设计了一个拥有1396万个人工神经元的分布式「太极」网络,超越了其他光芯片设计(147万个神经元)。
因此,「太极」实现了160.82 TOPS/W的能效。
与2022年一个团队实现的2.9 TOPS/W的能效相比,简直相形见绌。

能效的大幅提升,对于AI计算的可持续发展,至关重要。
对此,Science表示:
通用人工智能(AGI)的飞速发展带来了对下一代计算技术在性能和能效上的更高要求,而光子计算被认为有望达到这些目标。
但目前的光子集成电路,尤其是光学神经网络(ONN),在规模和计算能力上都非常有限,难以满足现代AGI任务的需求。
来自清华的团队探索了一种新型的分布式衍射-干涉混合光子计算架构,成功ONN的规模扩展到了百万神经元级。他们在芯片上成功实现了一个拥有1396万神经元的ONN,能够处理复杂的千类别级分类和AI生成内容的任务。
可以说,这项研究是光子计算实际应用的一个重要进展,为各种AI应用提供了支持。
创新性分布式计算架构
根据论文介绍,清华团队为采用分布式计算的「太极」,构建了一个深度较浅但宽度较广的网络结构。
这种可重配置的衍射干涉混合光芯片,是实现多种先进机器智能任务的关键组件,涵盖了1000类别分类和内容生成等应用。
与传统的深度计算层层堆叠的方法不同,「太极」将计算资源分配到多个独立的集群中,为子任务单独组织集群,最后为复杂的高级任务合成这些子任务。
具体地说,光学衍射层的完全连通特性,可以提供比传统DNN中的卷积层更大的变形能力。
这表明光网络具有用比电子系统更少的层来实现相同变换的潜力。
「太极」 的分布式架构深度浅而宽,旨在以可持续和高效的方式扩展计算能力。
在CIFAR-10数据集中,具有四个分布式层的「太极」 实现了与16层电子VGG-16网络相当的精度。
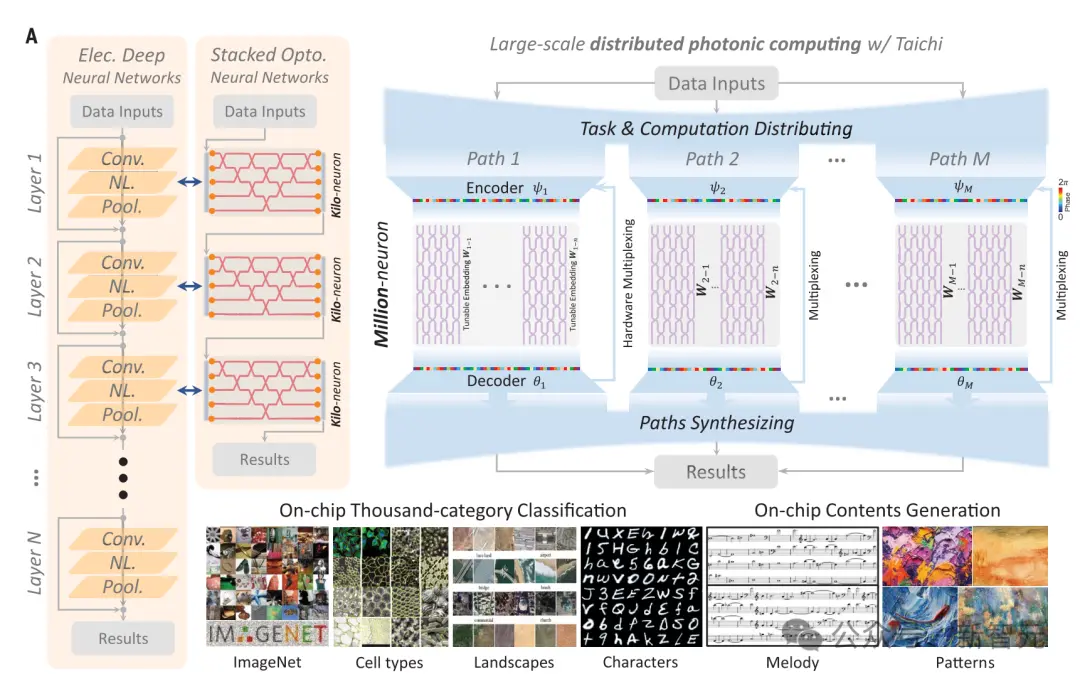
图 1. 「太极」:一个配备分布式计算架构的大规模光子芯片,专为百万神经元级芯片网络模型设计
图1(B)中展示了「太极」芯片,包括用于大规模输入和输出数据的双衍射单元,以及用于可重构特征嵌入和硬件多路复用的MZI阵列的可调矩阵乘法。
这些组件是「太极」(TEUs)的基本芯片上的执行单元,利用了光学衍射和干涉的强大变形能力。
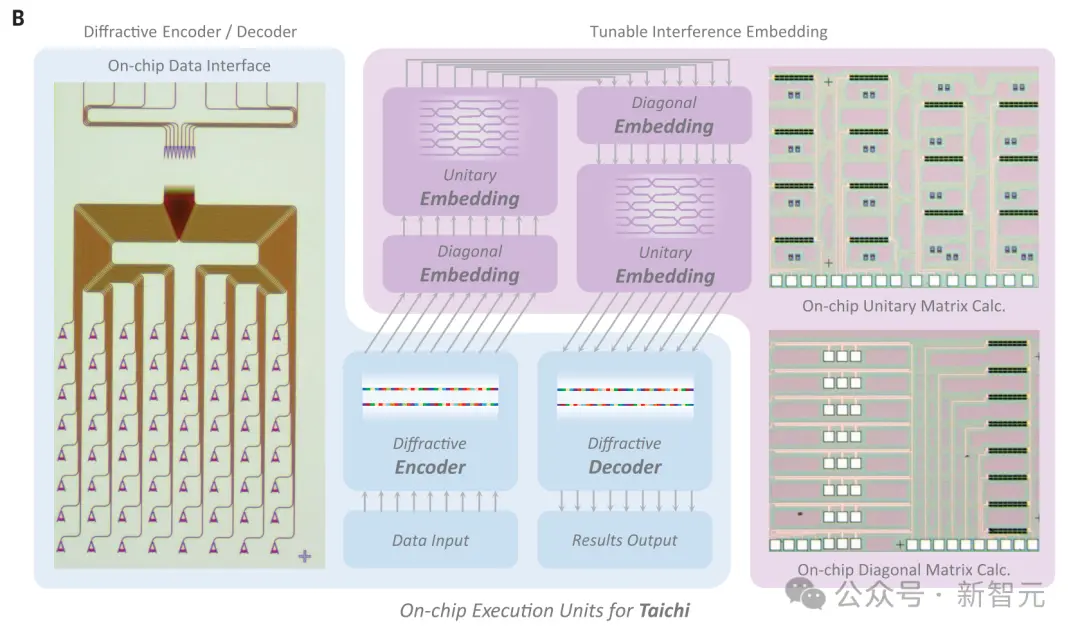
图 1. 「太极」:一个配备分布式计算架构的大规模光芯片,专为百万神经元级芯片网络模型设计
接下来,再细看「太极」的设计结构。
下图A中展示了「太极」整体布局,分为三个部分:
1. 输入衍射编码器(DE)(蓝色标注)采用8×8光栅耦合器阵列进行二维信息接收。总共对64个通道的输入进行了编码,并将有效信息通过衍射调制权重压缩为8个通道。
2. 干涉特征嵌入(IE)(紫色标注)采用Mach-Zehnder调制器(MZM)阵列进行任意矩阵乘法。
3. 相对于衍射解码器,输出绕射解码器(DD)(蓝色标注)是反向的。
图2(B)便是由20个DES、4个IE,以及4个DES被部署为新的TEU,来处理32×32的patch。
每个DE处理一个8×8的分布式patch,原始1024个通道的输入数据被编码为32个通道。
接下来的4个IE计算特征嵌入,最后4个DD将嵌入解码为256个通道输出。
通过调整分布式DE、IE和DD模块的数量,形成不同的特征嵌入通道数量和输出通道数量,可重构和可扩展的DE-IE-DD框架可以适应不同的patch大小和任务难度。
图2(C)展示了具有TEU群集的分布式架构。图2D中,研究者绘制了不同不确定性水平下的层数D和稳健性Lip(F)之间的关系。
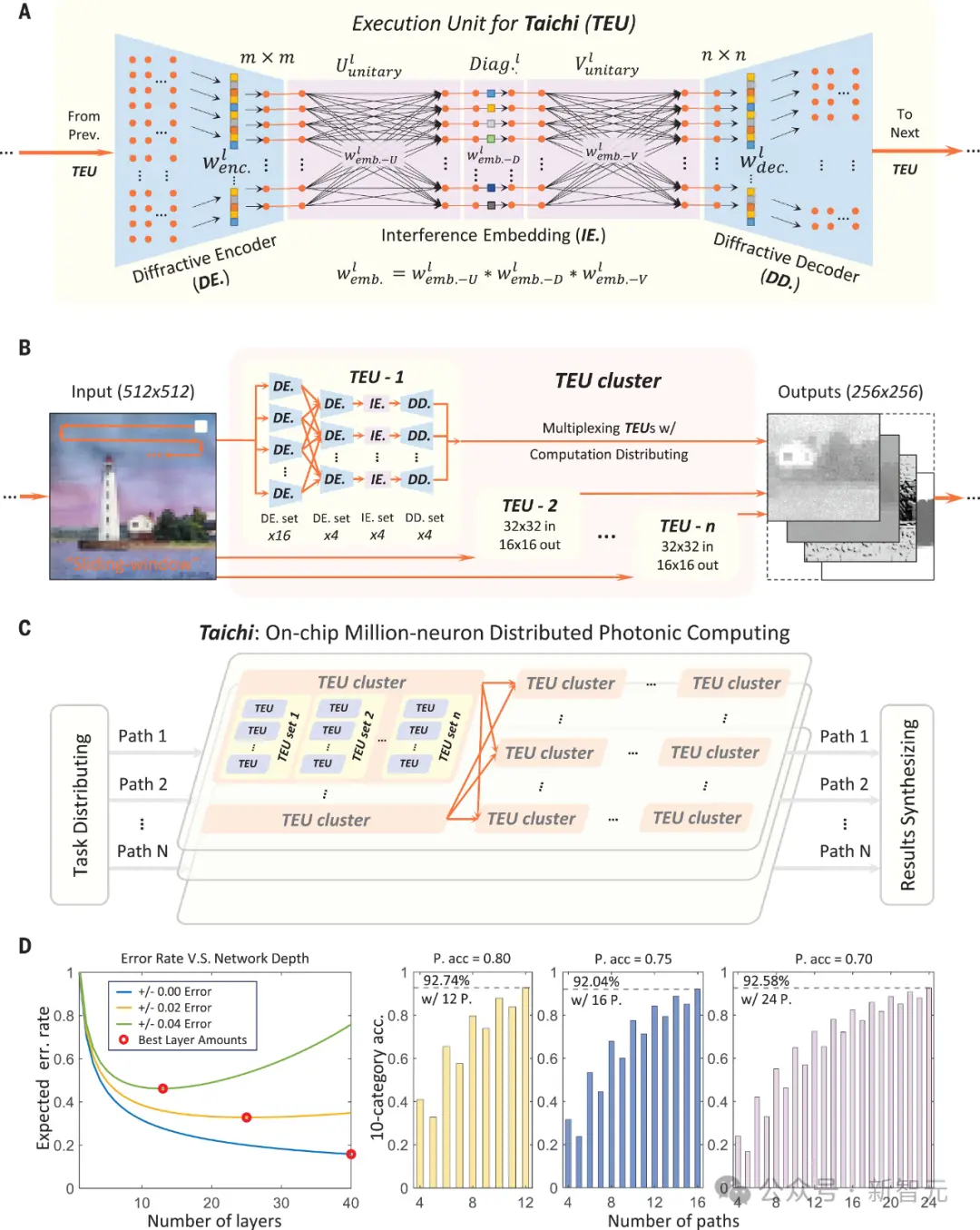
图 2. 构建「太极」的示意图
(A)「太极」的执行单元(TEUs)。
(B)多个TEUs根据计算分配协议协同工作,组成TEU集群。这些TEU集群采用滑动窗口机制处理较大的输入数据。
(C)复杂任务被分解成多个简单任务,每个简单任务由一系列TEU集群(标记为「路径」)负责处理。
(D)理论性能分析表明,随着每层网络的错误率增加,理想的层数(深度)在物理系统中会减少。然而,采用多路径的计算分配可以有效扩展网络规模,提升计算能力。
图像分类,90%+准确率
为了测试性能,研究人员首先取CIFAR-10数据集,并将每条路径设置为6层。这是实际噪声水平下的最佳规模,每层16-8-8-4-4-1 TEU。
七条路径的二值化准确率平均达到94%。
结合四条基本路径的子结果,最终的准确率达到了76.68%,已经超过了现有的芯片架构。
对于所有七条路径,最终结果提高到93.65%,与目前流行的电子神经网络的性能相当。
图3(E)是七条路径的整个测试集的混淆矩阵,图3(B)列出了「太极」、传统芯片网络体系结构、自由空间光计算体系结构和电子对应体系结构之间的精度性能基准。
图3(D)则展示了额外的路径如何帮助纠正错误的分类案例。
以青蛙图像为例,将七条路径的路径输出绘制为直方图(基本路径为紫线,额外路径为蓝线)。
在计算路径输出与每个类别的理想标签之间的相似度时,如果只采用基本路径(即错误地将青蛙视为一艘船),则会做出错误的决定,但如果将所有七条路径放在一起考虑,错误就会得到纠正。
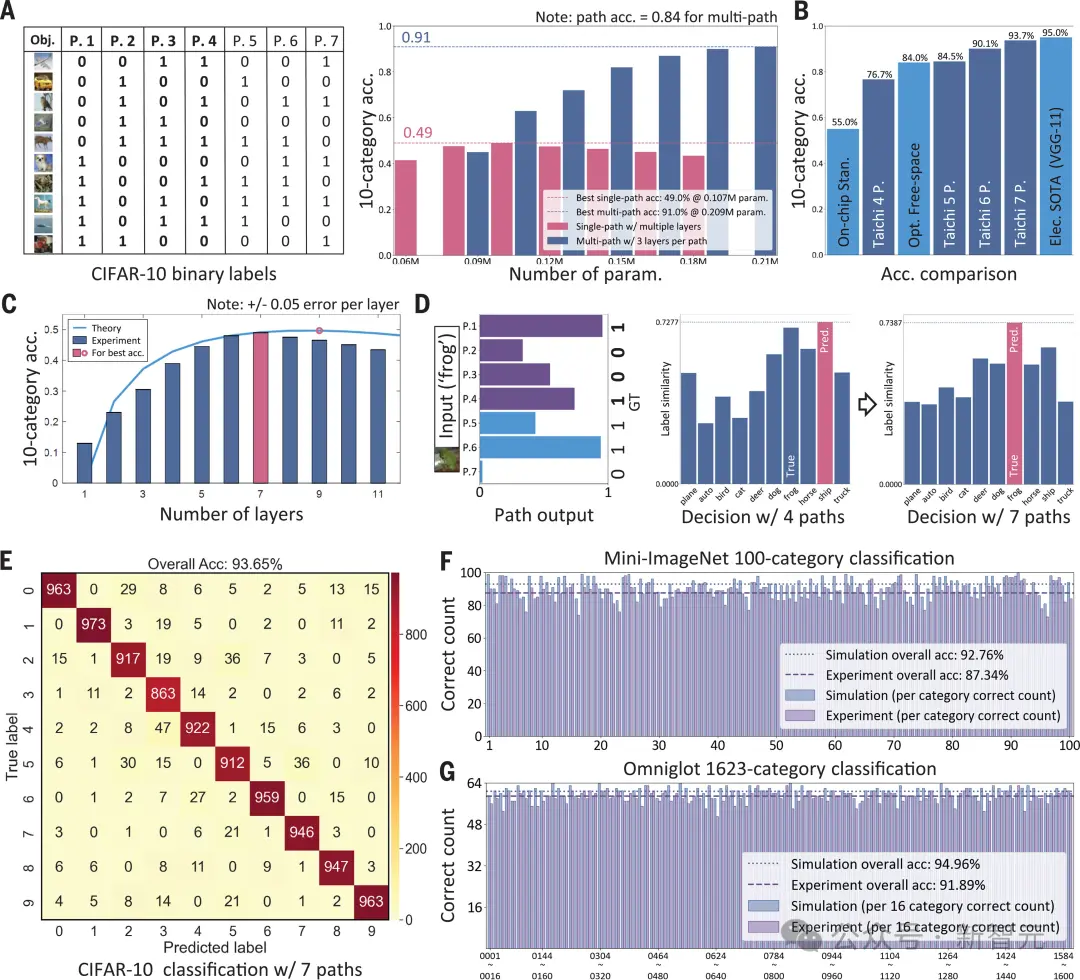
图 3. 用于1000类别分类的大规模光芯片
(A)CIFAR-10的多路径二进制标签,其中数据集中的每个对象在每条路径上被标记为「0」或「1」。单路径(传统方法)的分类准确率有限,但多路径(提议的方法)的分类准确率随参数数量增加而提高。
(B)对比传统芯片上的光学、自由空间光学、基于电子的最先进(SOTA)架构以及「太极」在不同路径数量下的CIFAR-10分类准确率。
(C)层数对10类别分类准确率的影响,展示了实验数据(条形图)和理论预测(曲线)。
(D)在CIFAR-10数据集中,一个样本通过「太极」的路径输出显示,最少的路径数量可能导致错误判断,但增加路径数量可以纠正错误。
(E)使用七条路径的CIFAR-10混淆矩阵。
(F)在mini-ImageNet数据集上进行100类别分类任务的模拟(蓝色)与实验(紫色)结果。
(G)在Omniglot数据集上进行1623类别分类任务的模拟(蓝色)与实验(紫色)结果。
为了进一步挖掘「太极」的潜力,研究人员通过为更高级的任务部署更多路径来扩展规模。
在每条路径中,层数保持不变,但每层将包含更多TEU(每层16-16-8-8-4-4-1 TEU)。
在100个类别的mini-ImageNet数据集上,每条路径的平均二值准确率在数值计算中为92.97%,在光学实验中为88.05%。
在七条基本路径和八条额外路径的情况下,100个类别的总正确率在数值模拟中为92.76%,在实际芯片测试中为87.34%。
其中,图3(F)是每个类别的正确样本计数显示为直方图。
音乐家艺术家,全能模仿
研究人员将每个音符的生成视为一个分类问题,从47个可能的音调中进行选择,前后各有16个音符作为输入。
对于训练,团队使用了接受率为95%的MCMC方法,来优化生成的音乐片段的风格。
随着训练的进行,网络给出了一个在频率(音高)域中的音符分布,来表示音乐风格。
经过训练,网络中的参数被固定下来,以适应巴赫的音乐生成风格。
清华团队通过一个独立训练的网络对生成的结果进行评估,该网络给出了一个体现结果的巴赫风格概率的「巴赫指数」输出。
图4(D)演示了生成过程。随机噪声作为初始输入,其巴赫指数为6.61%。随着迭代的进行,音调图中形成了模式,巴赫指数增加。
经过500次迭代,生成结果的巴赫指数达到95.17%,具有典型的巴赫风格。
在这种情况下,训练和生成被独立地处理为总共4个声音。
最后,「太极」创作了一个高度巴赫风格的合成四声合唱,如图4(B)所示。
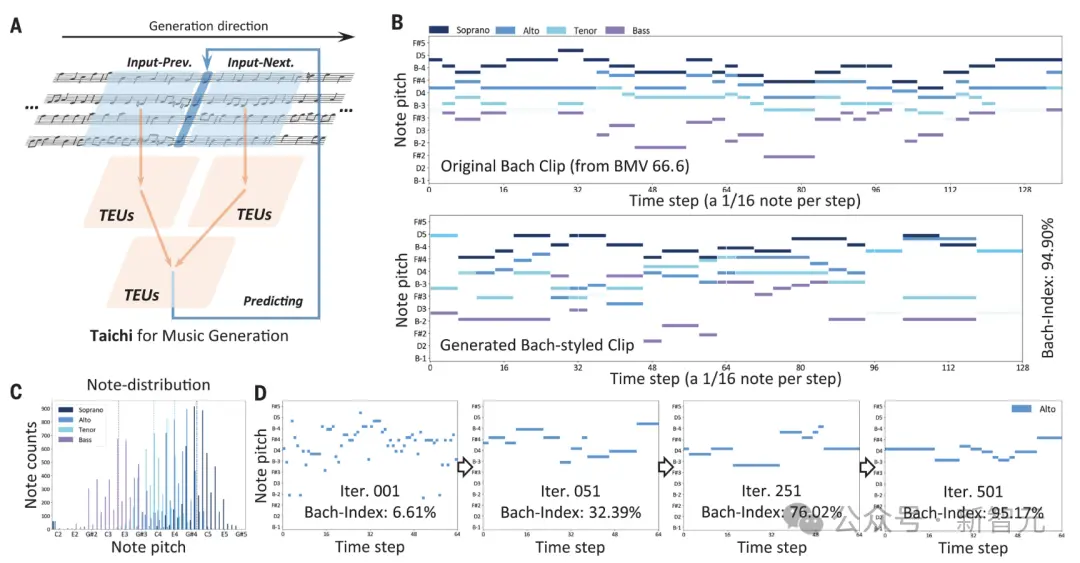
图 4. 大规模光芯片用于多样化内容生成
(A)配备TEU集群的音乐生成网络。
(B)展示了巴赫风格原始音乐与生成的四声部音高模式的对比。
(C)展示了生成的巴赫音乐的音符分布情况。
(D)使用巴赫指数进行迭代音乐生成,该指数用来评估生成音乐与巴赫风格的相似度。
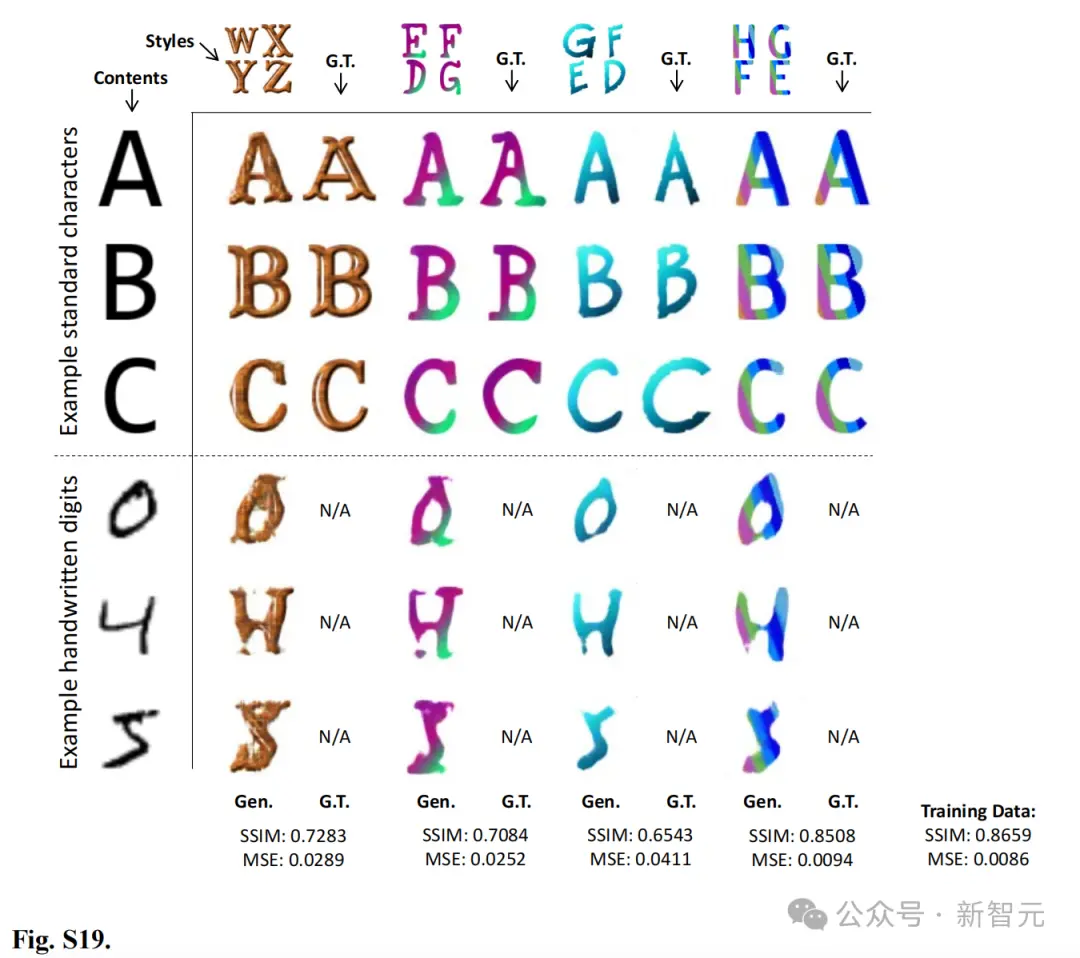
再来看图像生成,不同艺术家和风格的图像,被用来训练下一代神经网络。
研究人员采用不同的比例来生成不同级别的纹理,如下图所示。
首先使用较大的Scale 1,生成粗纹理。而较小的Scale 2,然后用于生成精细纹理,从而获得具有多尺度纹理的风格化图像。

为了评估结果,研究人员对预训练的VGG-16网络进行了微调,以得出艺术家风格分类结果。
然后,作者在小图像(来自MNIST数据集的手写数字「4」)和大规模真实场景图像下测试「太极」。
输入的图像是风格化的,保留了场景中的对象形状,并添加了艺术纹理。

图 4. 大规模光芯片用于多样化内容生成
(E)配备TEU集群的图像生成网络。
(F)展示了三种不同艺术家风格的图像生成结果。输入到「太极」的图像包括带有随机噪声的手写数字「4」和真实场景,目的是生成符合指定艺术家风格的风格化图像。使用一个独立的分类网络(风格概率)来识别生成图像的风格。
此外,研究人员还进行了字体风格迁移的扩展实验,以进一步展示「太极」 chiplets的高级内容生成能力。
通过这些额外的实验,他们验证了「太极」不仅具有模仿艺术家风格的能力,而且能够从2D图像中提取更高层次的语义信息。
成果讨论
在这项工作中,团队设计了一种具有灵活分布式计算架构的大规模衍射-干涉混合型光子AI芯片——「太极」。
在光芯片方面,「太极」深入探索了光子学的大规模并行连接,相较于其他TOPS/W级别框架,展现了更优的计算效率。
未来,借助直接激光写入(DLW)和相变材料(PCM),所有权重都能被重新配置,从而提升系统的灵活性。此外,芯片上的激光源、调制器和探测器也可以被整合到同一平台上,并通过晶圆键合技术实现高级集成。
相关内容
- 2024-12-22 三星、德州仪器共获美国超60亿美元芯片补贴,支持本土芯片制造
- 2024-12-20 AI也会得老年痴呆!最新研究:AI版本越老越糊涂
- 2024-12-19 传AI集成到苹果iPhone 腾讯大涨4% 字节概念股涨停
- 2024-12-19 AI创企暴雷!90后女创始人欺诈被捕:涉案7000万,或面临40年刑期
- 2024-12-19 AI成“吞电巨兽”!美监管机构警告:部分地区最早明年将电力短缺
点击排行
- 105-17OpenAI多位重量级高管离职,质疑再次涌向Sam Altman
- 203-07ChatGPT-Plus,AI 助手全套开源解决方案,自带运营管理后台,开箱即用。
- 306-22RTranslator: 全球第一个开源实时翻译应用程序
- 410-18诺奖得主哈萨比斯最新访谈:仅仅将AI视作一种技术是错误的
- 505-17马斯克称OpenAI最新模型慢得离谱
- 606-23OpenAI CTO:GPT-5可能会在2025年底或2026年初推出
- 706-23企业家自曝用了ChatGPT后裁员近1/10:管理效率大幅提升
- 805-17GPT-4o被全球网友玩坏了 谷歌:终究是错付了
- 906-23高通开放AI模型,助力开发者打造骁龙X Elite平台智能应用
- 1005-17谷歌Gemini AI 计划为学校提供额外的数据保护和隐私