新测试基准发布,最强开源Llama 3尴尬了
随着Claude 3、Llama 3甚至之后GPT-5等更强模型发布,业界急需一款更难、更有区分度的基准测试。
大模型竞技场背后组织LMSYS推出下一代基准测试Arena-Hard,引起广泛关注。
Llama 3的两个指令微调版本实力到底如何,也有了最新参考。
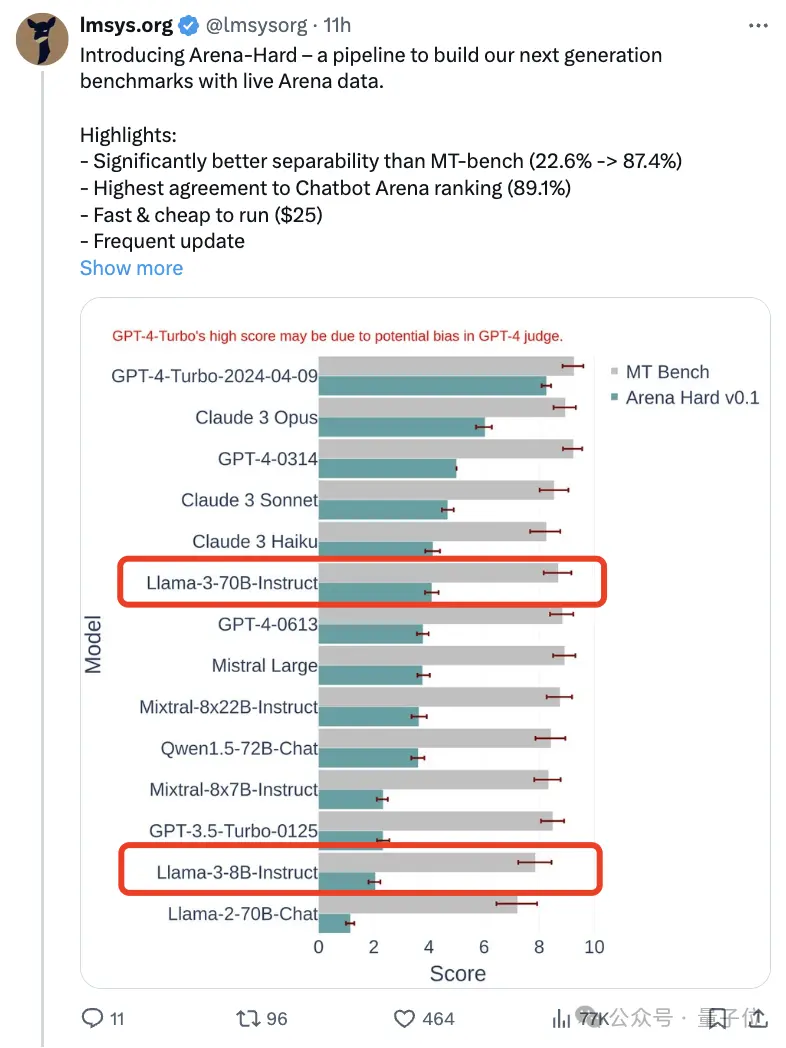
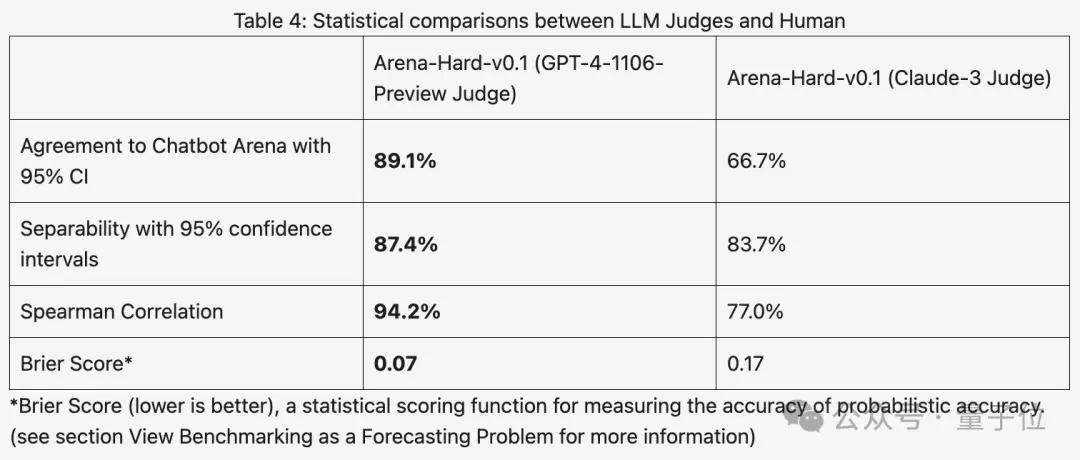
与之前大家分数都相近的MT Bench相比,Arena-Hard区分度从22.6%提升到87.4%,孰强孰弱一目了然。
Arena-Hard利用竞技场实时人类数据构建,与人类偏好一致率也高达89.1%。
除了上面两个指标都达到SOTA之外,还有一个额外的好处:
实时更新的测试数据包含人类新想出的、AI在训练阶段从未见过的提示词,减轻潜在的数据泄露。
并且新模型发布后,无需再等待一周左右时间让人类用户参与投票,只需花费25美元快速运行测试管线,即可得到结果。
有网友评价,使用真实用户提示词而不是高中考试来测试,真的很重要。

新基准测试如何运作?
简单来说,通过大模型竞技场20万个用户查询中,挑选500个高质量提示词作为测试集。
首先,挑选过程中确保多样性,也就是测试集应涵盖广泛的现实世界话题。
为了确保这一点,团队采用BERTopic中主题建模管道,首先使用OpenAI的嵌入模型(text-embedding-3-small)转换每个提示,使用 UMAP 降低维度,并使用基于层次结构的模型聚类算法 (HDBSCAN) 来识别聚类,最后使用GPT-4-turbo进行汇总。
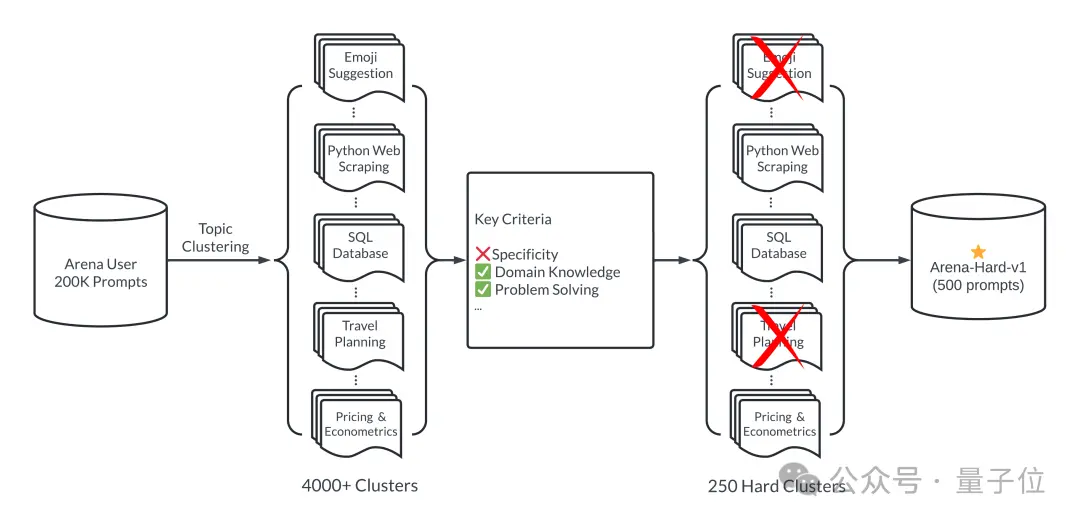
同时确保入选的提示词具有高质量,有七个关键指标来衡量:
具体性:提示词是否要求特定的输出?
领域知识:提示词是否涵盖一个或多个特定领域?
复杂性:提示词是否有多层推理、组成部分或变量?
解决问题:提示词是否直接让AI展示主动解决问题的能力?
创造力:提示词是否涉及解决问题的一定程度的创造力?
技术准确性:提示词是否要求响应具有技术准确性?
实际应用:提示词是否与实际应用相关?

使用GPT-3.5-Turbo和GPT-4-Turbo对每个提示进行从 0 到 7 的注释,判断满足多少个条件。然后根据提示的平均得分给每个聚类评分。
高质量的问题通常与有挑战性的话题或任务相关,比如游戏开发或数学证明。

新基准测试准吗?
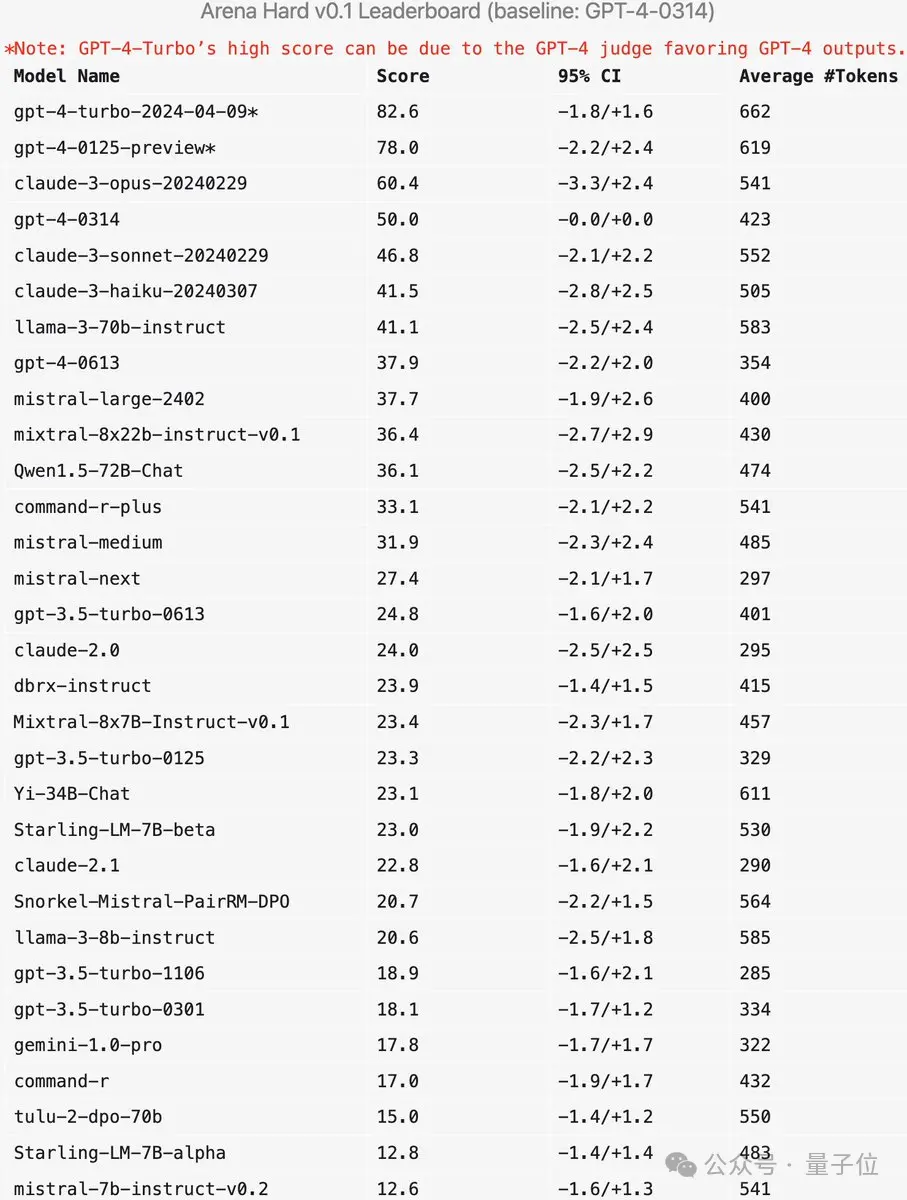
Arena-Hard目前还有一个弱点:使用GPT-4做裁判更偏好自己的输出。官方也给出了相应提示。
可以看出,最新两个版本的GPT-4分数高过Claude 3 Opus一大截,但在人类投票分数中差距并没有那么明显。
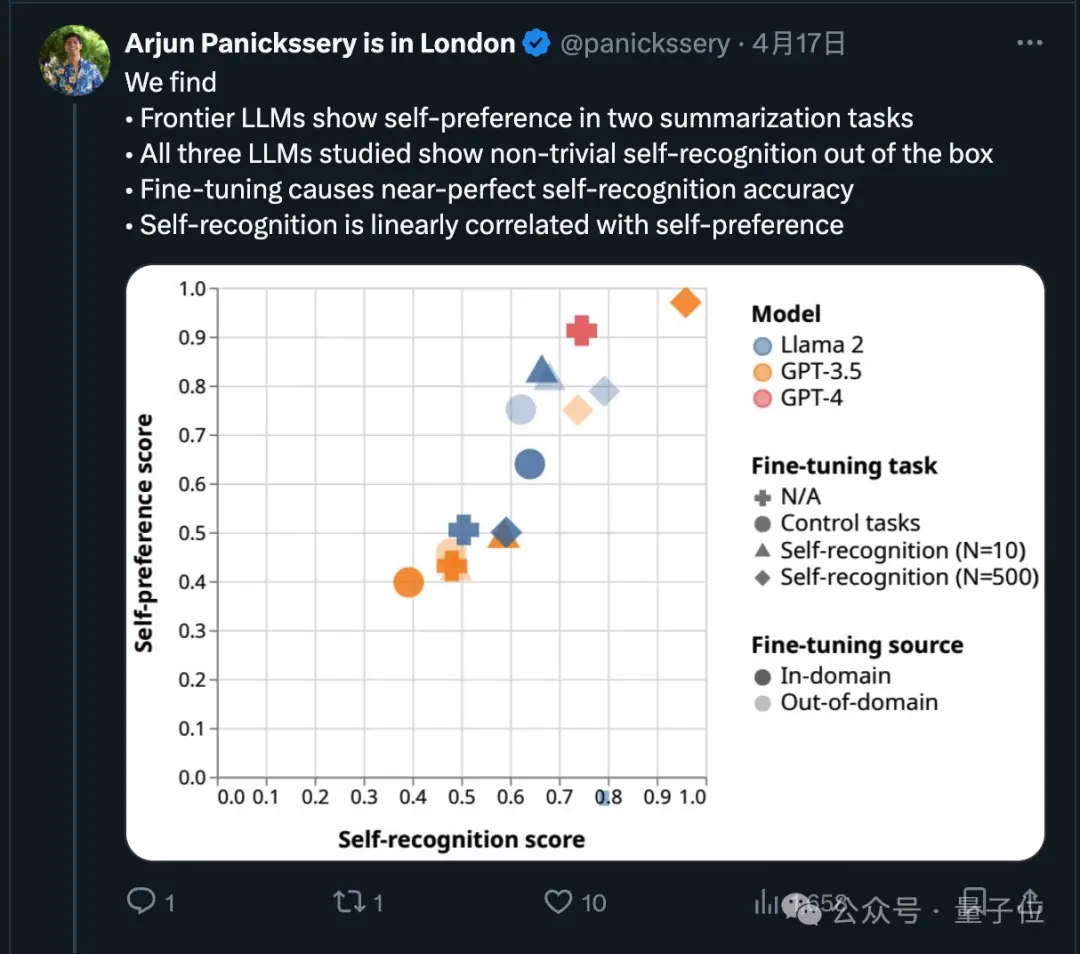
其实关于这一点,最近已经有研究论证,前沿模型都会偏好自己的输出。

研究团队还发现,AI天生就可以判断出一段文字是不是自己写的,经过微调后自我识别的能力还能增强,并且自我识别能力与自我偏好线性相关。
那么使用Claude 3来打分会使结果产生什么变化?LMSYS也做了相关实验。
首先,Claude系列的分数确实会提高。
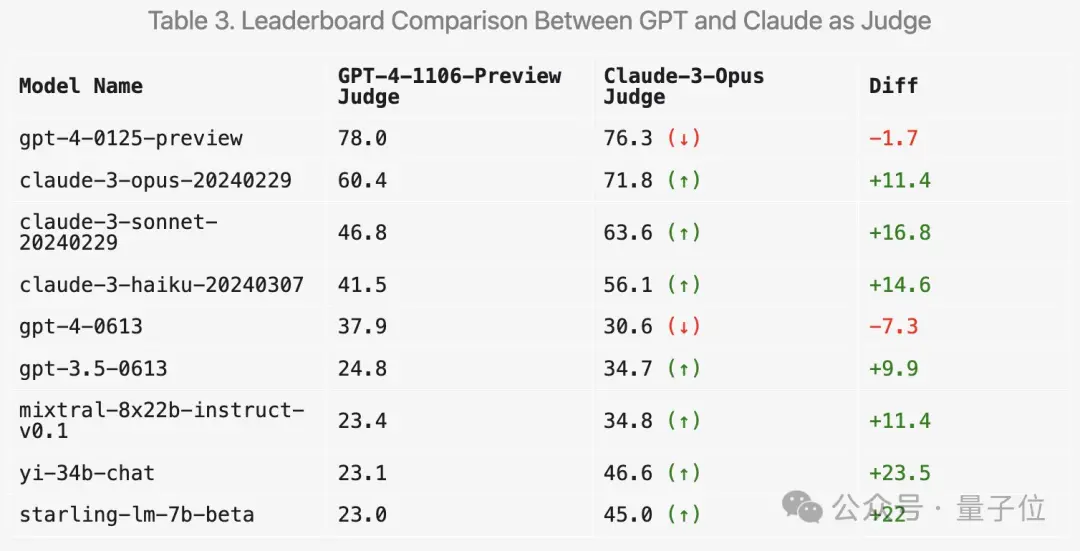
但令人惊讶的是,它更喜欢几种开放模型如Mixtral和零一万物Yi,甚至对GPT-3.5的评分都有明显提高。
总体而言,使用Claude 3打分的区分度和与人类结果的一致性都不如GPT-4。
所以也有很多网友建议,使用多个大模型来综合打分。
除此之外,团队还做了更多消融实验来验证新基准测试的有效性。
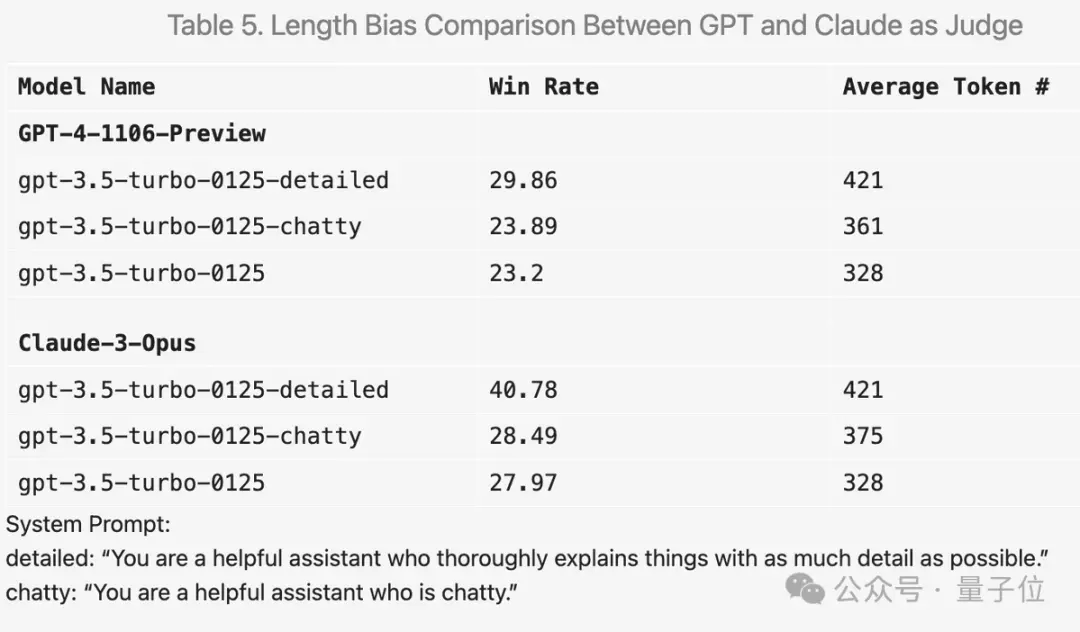
比如在提示词中加入“让答案尽可能详尽”,平均输出长度更高,分数确实会提高。
但把提示词换成“喜欢闲聊”,平均输出长度也有提高,但分数提升就不明显。
此外在实验过程中还有很多有意思的发现。
比如GPT-4来打分非常严格,如果回答中有错误会狠狠扣分;而Claude 3即使识别出小错误也会宽大处理。
对于代码问题,Claude 3倾向于提供简单结构、不依赖外部代码库,能帮助人类学习编程的答案;而GPT-4-Turbo更倾向最实用的答案,不管其教育价值如何。
另外即使设置温度为0,GPT-4-Turbo也可能产生略有不同的判断。
从层次结构可视化的前64个聚类中也可以看出,大模型竞技场用户的提问质量和多样性确实是高。
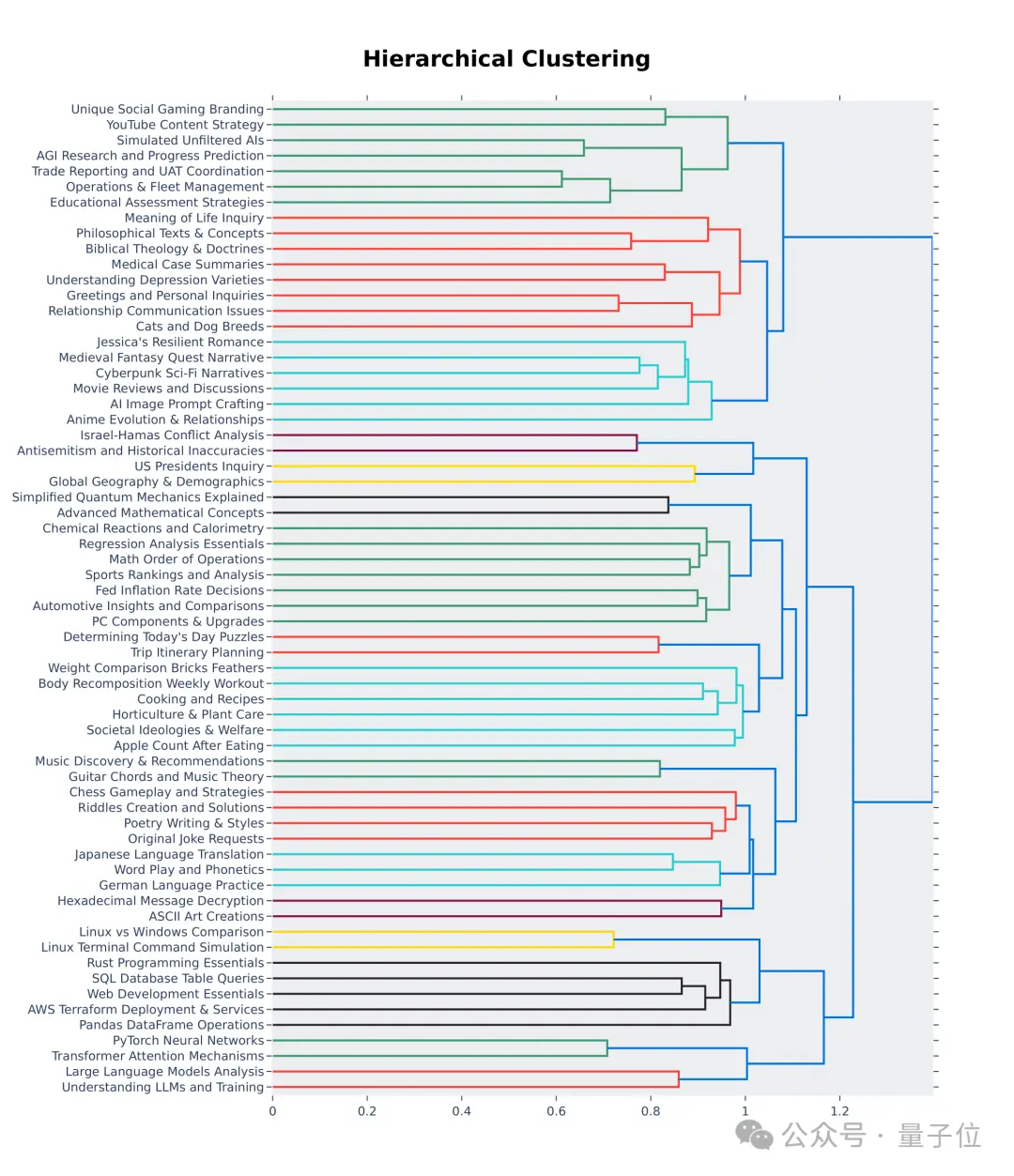
这里面也许就有你的贡献。
相关内容
- 2024-12-22 关注!FastVideo,用于加速大型视频扩散模型的开源框架
- 2024-12-16 清华系出手!全球第一款端侧全模态理解模型开源
- 2024-12-11 LG发布EXAONE 3.5开源AI模型:长文本处理利器、独特技术有效降低“幻觉”
- 2024-12-07 Meta今年压轴开源AI模型Llama3.3登场:700亿参数,性能比肩4050亿
- 2024-12-07 新版Llama 3 70B反超405B!Meta开卷后训练,谷歌马斯克都来抢镜
点击排行
- 105-17OpenAI多位重量级高管离职,质疑再次涌向Sam Altman
- 203-07ChatGPT-Plus,AI 助手全套开源解决方案,自带运营管理后台,开箱即用。
- 306-22RTranslator: 全球第一个开源实时翻译应用程序
- 410-18诺奖得主哈萨比斯最新访谈:仅仅将AI视作一种技术是错误的
- 505-17马斯克称OpenAI最新模型慢得离谱
- 606-23OpenAI CTO:GPT-5可能会在2025年底或2026年初推出
- 706-23企业家自曝用了ChatGPT后裁员近1/10:管理效率大幅提升
- 805-17GPT-4o被全球网友玩坏了 谷歌:终究是错付了
- 906-23高通开放AI模型,助力开发者打造骁龙X Elite平台智能应用
- 1005-17谷歌Gemini AI 计划为学校提供额外的数据保护和隐私