

王小川首个AI应用来了!一手测评:有特点,但不完美_tiknovel-最新最全的nft,web3,AI技术资讯技术社区
王小川首个AI应用来了!一手测评:有特点,但不完美
昨天,百川智能发布了新一代的基座大模型 Baichuan 4,同时推出了首款 AI 应用——百小应。
与市场上大部分大模型厂商一样,百川智能瞄准的是AI智能助手。有意思的地方是,虽然定位于AI 智能助手,但百小应主打的特点却是「懂搜索、会提问」。这点又与目前很火的 AI 搜索应用类似。
强调搜索特点,并不意外。王小川可以说是国内最懂搜索的人之一,其创立的搜狗长期稳坐搜索行业第二把交椅。AI搜索又是AI应用的三大场景,连OpenAI都在布局。
令人好奇的是,从移动互联网到生成式AI,王小川是如何理解搜索产品的变化?百小应与市面上的AI搜索产品又有什么不同?在百小应上线的第一时间,乌鸦君就上手用了下。今天,大家可以跟着乌鸦君,先来探探水。
/ 01 /
懂搜索,但又不止搜索
从定位上,百川推出的“百小应”是一款类似于ChatGPT、Kimi的智能助手产品,不仅可以随时回答用户提出的各种问题,速读文件、整理资料、辅助创作等,还具备多轮搜索、定向搜索等搜索能力。
产品本身也具备多模态相关功能,用户可以上传图片、pdf等文档,让百小应辨别其中的内容,并且完成相应指令,如撰写文案等。
要说百小应与市面上智能助手产品最大的不同,还得是搜索功能。用王小川的话说,“百小应”的一大特点在于,可以让模型学会“多轮搜索”。
什么是“多轮搜索”?多轮搜索就是指,针对用户提出的问题,百小应能够更进一步,探究问题的核心答案。相比单轮搜索,在市场调研、产业分析等复杂场景下,多轮搜索能够有效地获取更专业、更有深度的信息。
在搜索结果呈现方面,与其他在单次搜索后简单总结网页信息的应用不同,百小应将能够搜索结果作为观点、论据直接应用到问答结果中,能够将搜索结果以表格等结构化形式呈现,优化信息布局,便于用户快速定位、解读所需信息。
尽管以“搜索“功能作为特点,但百川并不希望将其看做一款搜索+AI的产品。用王小川的话说,“如果是将搜索结果简单总结,搜索公司自己就可以做,不是创业公司做的事。”长期来看,AI助手将会从AI“工具”升级到“伙伴”。
也就是说,比起市面上直接给到搜索结果的搜索产品,百小应更愿意将搜索作为与用户互动的场景。
/ 02 /
搜索功能一手测评:有特点,但并不完美
打开百小应应用,会直接出现一个对话框,这也是搜索功能的入口。
为了更好感受百小应与市面上AI搜索产品的差异,我们通过三个问题对百小应的AI 搜索实用能力进行了一个测试。
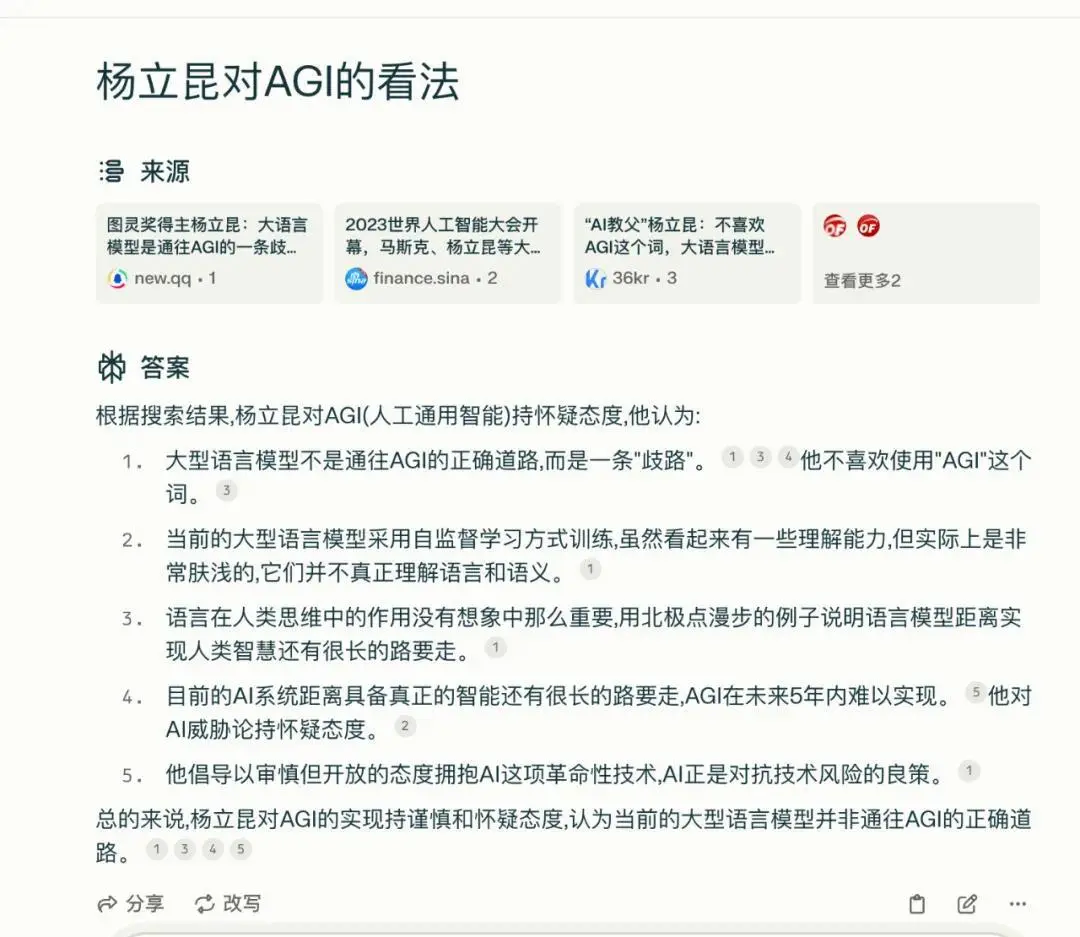
第一个问题是,杨立昆对AGI的看法。对于这个看似并不难的问题,百小应的回答令人意外:
杨立昆教授是中国科学院自动化研究所的研究员。同时,百小应也没办法给出杨立昆的观点,原因是:由于无法访问最新资料库,其无法提供最新观点。

对比之下,秘塔AI和Perplexity的表现要好很多。
秘塔不仅给出了杨立昆的部分核心观点,还对观点进行了梳理,形成了大纲。在回答的后面,还有与杨立昆相关的信息、事件科普。

Perplexity尽管不能做到像秘塔一样详细,但至少能给到一些核心观点,算是基本合格。
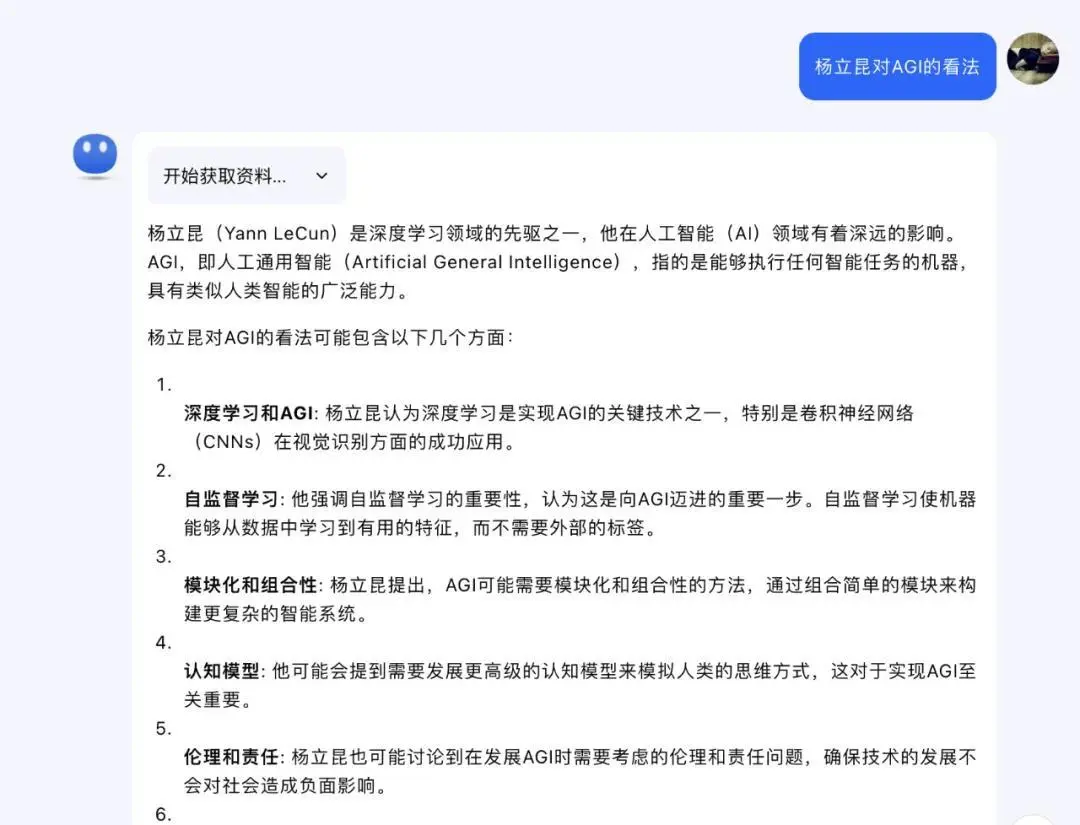
就算是与同样定位于AI助手的Kimi,至少给出了杨立昆的一些基本资料和笼统的观点。
问题二是,AI搜索与传统搜索相比有什么不同?对于这个问题,秘塔的表现一如既往地稳定,既有整体的总结,又有要点的分类。

Perplexity则直接给出了AI搜索与传统搜索的6个不同点,从要点总结来看,Perplexity与秘塔略有差异。

再来看百小应的表现,百小应同样给出了五点不同分别是:搜索结果的相关性、交互方式、学习与优化、搜索结果呈现、搜索引擎的智能化程度。

不仅如此,百小应还基于用户AI搜索的信息需求更进一步,给出了百度、谷歌在AI搜索领域的实际应用案例。至少在这个问题上,百小应在与秘塔和Perplexity的对比中没有落于下风。

在这里,乌鸦君还多问了一句:在AI搜索上,秘塔和百度谁更有优势?百小应并没有直接给出结论,反而分别给出了秘塔和百度各自的优势,甚至还做了表格。更多样的结构化呈现形式,也是百小应的一大特色。
从前两个问题看,相比秘塔和Perplexity,百小应在信息准确性上表现很不稳定。要想把 AI 搜索真正用到工作里,比起什么连续对话和实时性,答案的准确度才是优先考虑项。
所以,最后的测验里,乌鸦君特地挖了一个坑,问了一个根本不存在的数据:拼多多2010年的用户数量?
百小应不仅没有上套,还直接点破了这个套路:拼多多成立于2015年9月,所以2010年没有用户数据。
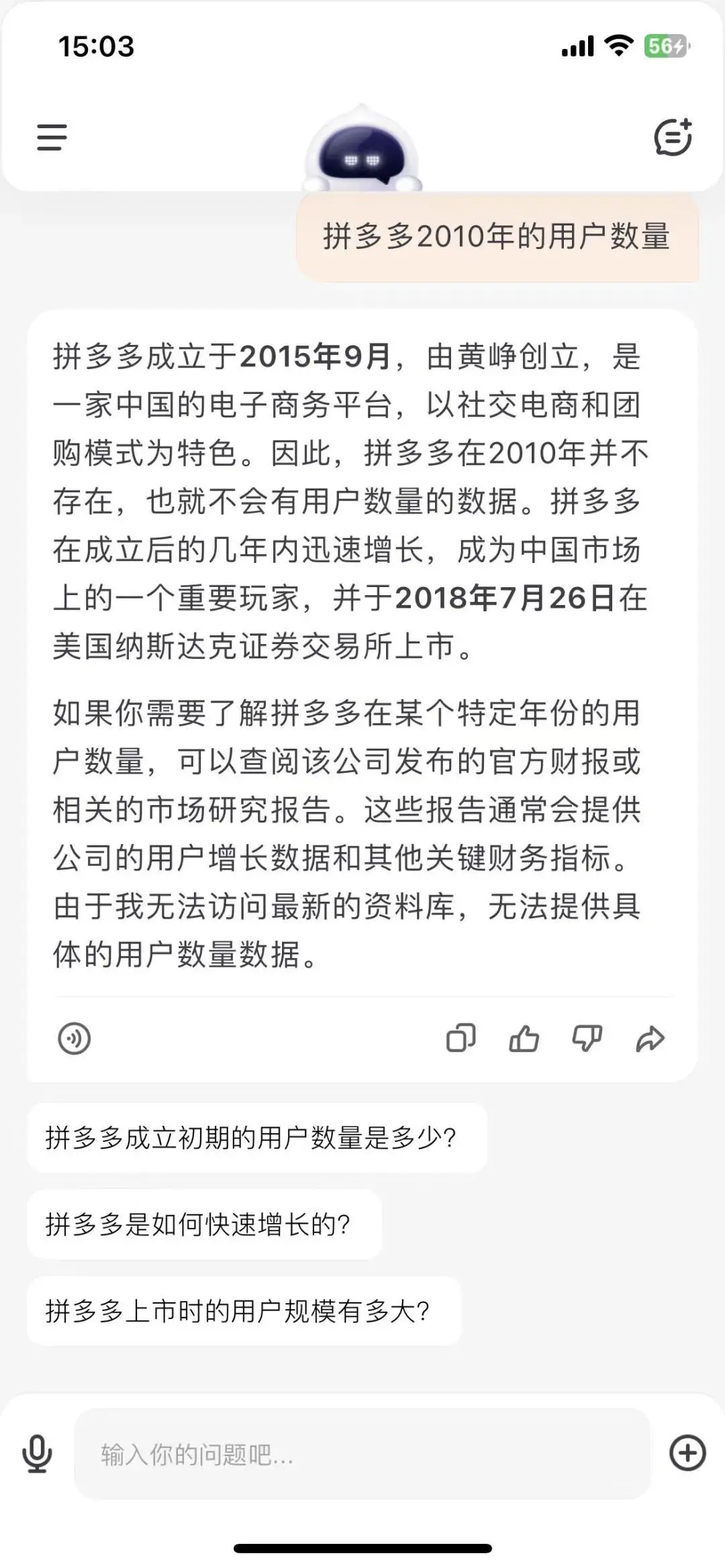
Perplexity也没有上套,不仅给出了正确信息,还围绕拼多多用户表现这一信息点,给出了更多的相关信息。
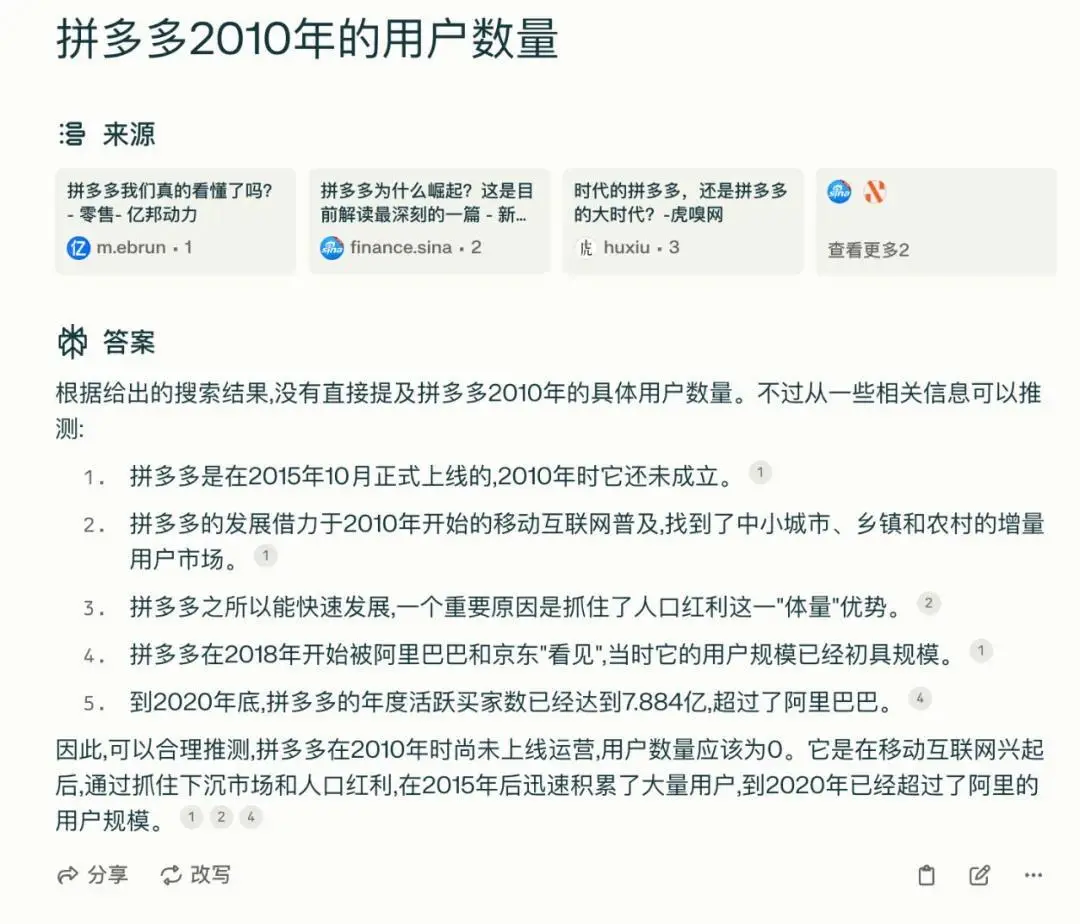
让乌鸦君没有想到的是,之前表现很不错的秘塔,却在这个问题上犯晕了。虽然秘塔在总结里说的是,没办法给到拼多多2010年的数据,但在概括里仍然给到了一个错误事实:拼多多成立于2010年。
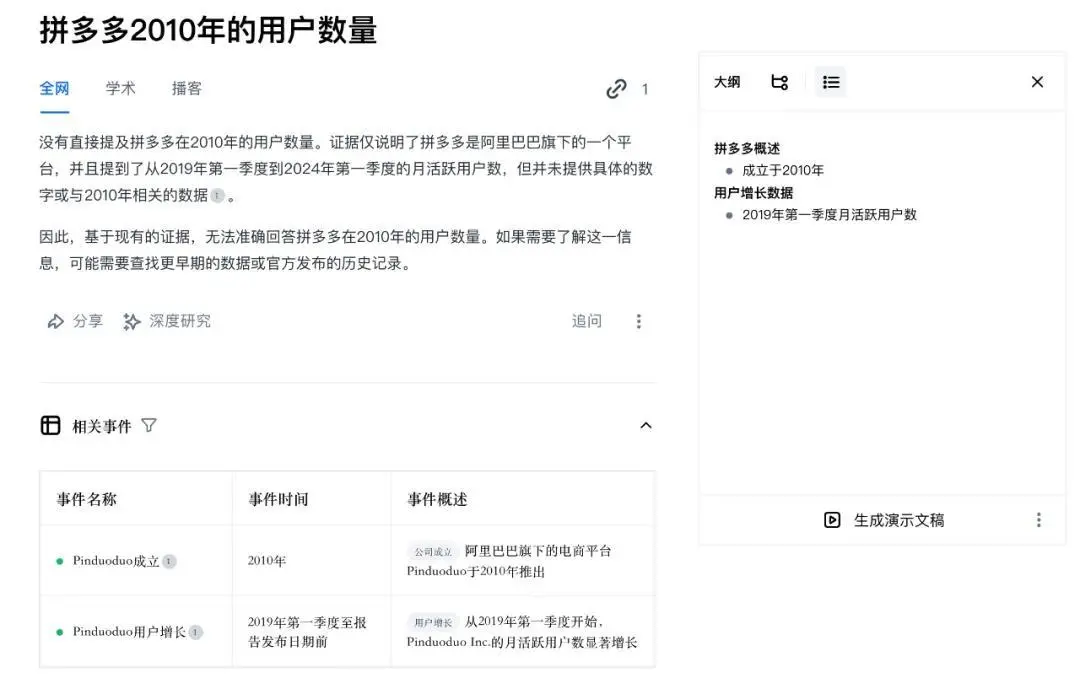
三轮测试下来,除了Perplexity表现稳定外,百小应与秘塔在信息准确性都“翻了车“,相比之下,百小应的错误要更严重一些。
百小应对杨立昆AGI观点的事实错误,一部分原因是模型知识库造成的信息实时性不足。
比如,当我向百小应提问,评价一下GPT-4o?百小应会回答,数据知识更新日期为2023年,没有相关资料。但如果你把同样的问题给到秘塔和Perplexity,它们却能够给出有关GPT-4o的最新资料。

这与百小应产品定位有很大关系。百小应的定位是类似于ChatGPT的个人助手,这意味着其信息获取依赖于模型的训练数据,而AI搜索则可以实时抓取最新的网络信息,因此在信息实时性上更有优势。同样的Kimi也没办法给出GPT-4o的评价。
根据其他媒体的说法,在对百小应进行提问的时候,不一定会触发搜索功能。不过这样设计多少令人感到奇怪:
虽然定位于个人助手,但百小应在对外宣传时强调的是,搜索技术和大模型深度融合。“懂搜索的AI助手”,也是百小应的Slogan。但在实际使用过程中,无法像市面上AI搜索一样完成实时信息的获取,对用户体验影响极大。
当然,考虑百小应刚刚上线,这些不完善也能够理解,期待后面产品有进一步改善。
Prev Chapter:阿里投资Kimi AI开发商月之暗面:8亿美元购入约36%股权
Next Chapter:马斯克:人工智能将取代我们所有人的工作
评论区
- 这篇文章还没有收到评论,赶紧来抢沙发吧~
【随机内容】

