

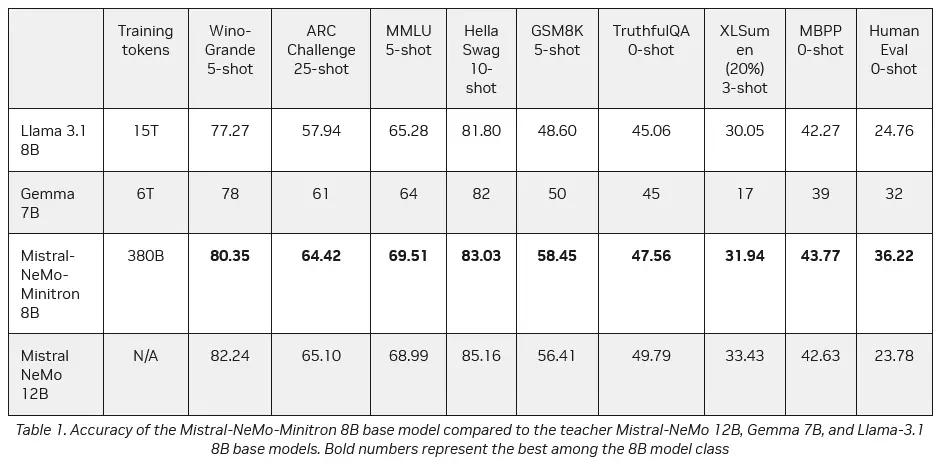
英伟达发布80亿参数新AI模型:精度、效率高,可在RTX工作站上部署_tiknovel-最新最全的nft,web3,AI技术资讯技术社区
英伟达发布80亿参数新AI模型:精度、效率高,可在RTX工作站上部署
2024-08-23 13:32:13 浏览:293 作者:管理员
英伟达发布80亿参数新AI模型:精度、效率高,可在RTX工作站上部署


Prev Chapter:文生图AI工具Midjourney开放网页版,新用户附赠25张免费试用额度
Next Chapter:AI正污染我们的世界
评论区
共 0 条评论
- 这篇文章还没有收到评论,赶紧来抢沙发吧~
【随机内容】

