

Meta研发新方法:整合语言和扩散AI模型,降低计算量、提高运算效率、优化生成图像_tiknovel-最新最全的nft,web3,AI技术资讯技术社区
Meta研发新方法:整合语言和扩散AI模型,降低计算量、提高运算效率、优化生成图像
IT之家 8 月 24 日消息,Meta AI 公司最新推出了 Transfusion 新方法,可以结合语言模型和图像生成模型,将其整合到统一的 AI 系统中。
IT之家援引团队介绍,Transfusion 结合了语言模型在处理文本等离散数据方面的优势,以及扩散模型在生成图像等连续数据方面的能力。
Meta 解释说,目前的图像生成系统通常使用预先训练好的文本编码器来处理输入的提示词,然后将其与单独的扩散模型结合起来生成图像。
许多多模态语言模型的工作原理与此类似,它们将预先训练好的文本模型与用于其他模态的专用编码器连接起来。
不过 Transfusion 采用单一、统一的 Transformer 架构,适用于所有模式,对文本和图像数据进行端到端训练。文本和图像使用不同的损失函数:文本使用下一个标记预测,图像使用扩散。
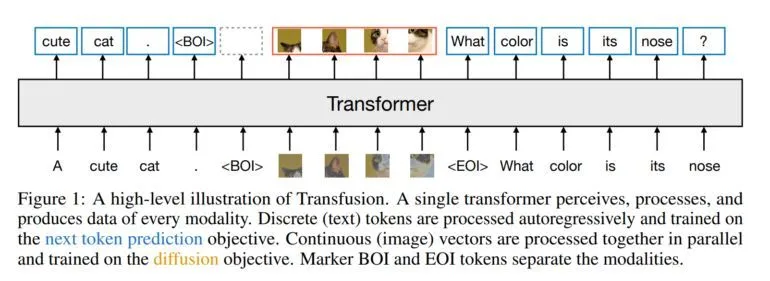
为了同时处理文本和图像,图像被转换成图像片段序列。这样,模型就能在一个序列中同时处理文本标记和图像片段,特殊的注意力掩码(attention mask)还能让模型捕捉图像内部的关系。
有别于 Meta 现有的 Chameleon(将图像转换成离散的标记,然后用处理文本的方式处理)等方法,Transfusion 保留了图像的连续表示法,避免了量化造成的信息损失。
实验还表明,与同类方法相比,"融合" 的扩展效率更高。在图像生成方面,它取得了与专门模型相似的结果,但计算量却大大减少,令人惊讶的是,整合图像数据还提高了文本处理能力。

研究人员在 2 万亿个文本和图像标记上训练了一个 70 亿参数的模型。该模型在图像生成方面取得了与 DALL-E 2 等成熟系统相似的结果,同时还能处理文本。
Prev Chapter:AI竟偷偷独自重写自己的代码
Next Chapter:OpenAI任命前Meta高管Irina Kofman为战略计划负责人
评论区
- 这篇文章还没有收到评论,赶紧来抢沙发吧~
【随机内容】

