

OpenAI满血版o1剧透:数学代码能力再破天花板,已开启测试评估_tiknovel-最新最全的nft,web3,AI技术资讯技术社区
OpenAI满血版o1剧透:数学代码能力再破天花板,已开启测试评估
“性能远超o1预览版,满血版o1即将推出”。
OpenAI在官网商业化频道下,对满血版o1来了一波提前剧透。
视频截图中,满血版o1和GPT-4o、o1-preview(预览版)同台竞技,且在数学/编码上遥遥领先。
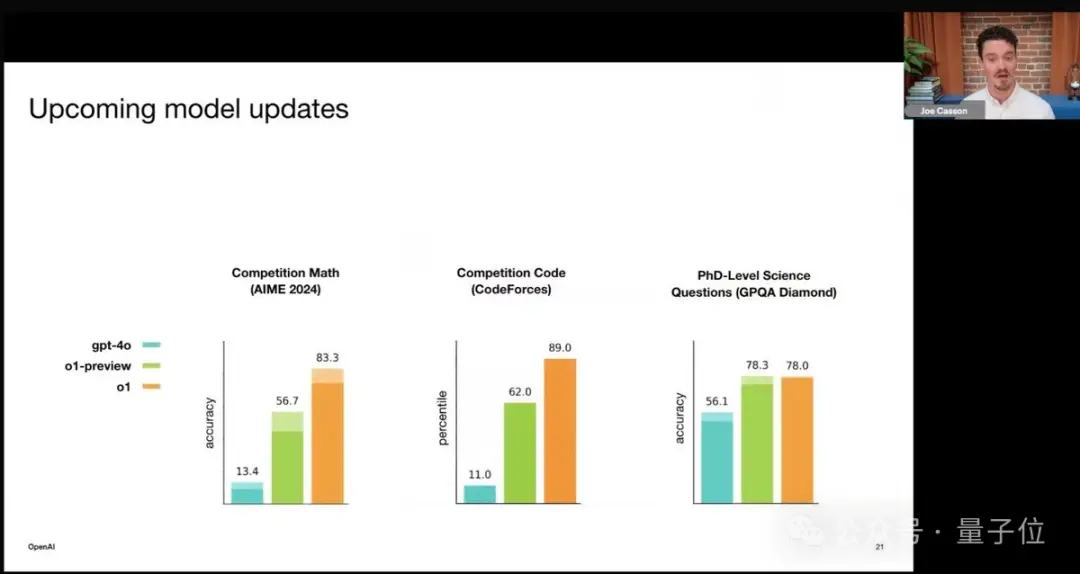
经透露,OpenAI将同步发布GPT系列和o1系列,且正在对满血版o1进行基准测试和运行评估。
此外,官方计划在未来几个月内为o1系列模型添加更多功能,例如网页浏览、文件和图像上传等,并支持ChatGPT自动选择合适模型。
不过扫到最后,网友们却发现了一个华点:
啥?在PhD级别的科学任务上,满血版o1竟打不过o1-preview?

对于这点,我们不妨从OpenAI首席产品官最近的采访中找找答案,刚好他也谈到了o1模型——

满血版o1即将推出
OpenAI于上月无预警发布了传说中的“草莓”模型:o1系列。
它是OpenAI首个经过强化学习训练的模型,在输出回答之前,会再产生一个很长的思维链,以此增强模型的能力。
o1系列一共3档,满血版因过于强大至今仍未公布。
o1(满血版):新的大模型天花板,专注于深度思考和逻辑推理
o1-preiview:o1的早期预览版本,在数学、编码能力上相比GPT-4o大幅提升
o1-mini:速度更快、性价比更高,适用于需要推理和无需广泛世界知识的任务
不过就在最近,关于o1模型的更多消息释出——
OpenAI员工在一场研讨会中详细介绍了o1-preview模型的最新案例,并提到满血版o1即将发布。
一开始,OpenAI产品营销团队的Victoria Chernova确认,公司将同步开发和发布GPT和o1两个系列的模型,因为它们各自擅长解决不同的问题。
这就像OpenAI官方一直提到的“范式转变”,GPT系列侧重于预测性回答,模式为“提问-回答”,而o1系列在回答前加入了更多思考。
Victoria Chernova也提到,很多客户实际上在同时使用GPT和o1两个系列的模型,包括OpenAI内部也是如此。
接下来,解决方案工程团队的Joe Casson分享了o1模型的几个最新应用:战略制定、代码编写,研究分析。
在第一个案例中,他演示了如何用o1-preview分析巴黎或其他欧洲城市,以决定下一个市场开拓地。
过程中需要模型考虑市场潜力、市场进入策略、人才招聘等多个方面,最终生成了一份包含执行摘要和电子邮件的报告。

然后他分享了如何用o1-mini从零创建一个带有Node.js后端和React前端的Web应用程序。
他还提到,o1-mini可以帮助开发者连接到Azure数据库等外部服务。

最后,他展示了如何用o1-preview帮助制定一份狗狗的最佳饮食计划等。

在展示分享中,他们也提到了人们目前对o1模型的一些“吐槽”:比如o1-preview非多模态,上下文窗口长度也比GPT-4o更短……
对此,OpenAI计划在未来几个月内为o1系列模型添加更多功能,包括网页浏览、文件和图像上传等,并支持ChatGPT自动选择合适的模型。

OpenAI首席产品官谈o1模型
除了上述研讨会,最近还有一场对OpenAI首席产品官Kevin Weil的采访。
其中谈到,目前o1推理模型仅处于GPT-2级别,因此它将很快改进。

另外他还分享了在OpenAI与其他公司构建产品的不同之处。
最大区别在于,技术基础是不固定的。
以前在我工作过的几乎所有地方,在拥有固定的技术基础之前,都在试图弄清楚如何利用它来构建最好的产品。

而回到一开始的问题,为什么在PhD级别的科学任务上,满血版o1竟打不过o1-preview?
也许在于哪怕是细微差距,两者的构建方式也是如此不同。

至于这0.3的差距到底有多大,也许即将公布的测试结果将为我们进一步揭晓。
参考链接:
[1]https://openai.com/business/solving-complex-problems-with-openai-o1-models/
[2]https://x.com/rohanpaul_ai/status/1847682643166650761
Prev Chapter:Meta 上周开源了一个端到端的语音模型 Spirit LM
Next Chapter:高通与谷歌达成多年战略合作,提供生成式AI数字座舱解决方案
评论区
- 这篇文章还没有收到评论,赶紧来抢沙发吧~
【随机内容】

