

谷歌DeepMind研究再登Nature封面,隐形水印让AI无所遁形_tiknovel-最新最全的nft,web3,AI技术资讯技术社区
谷歌DeepMind研究再登Nature封面,隐形水印让AI无所遁形
君可知,我们每天在网上的见闻,有多少是出自AI之手?

除了「注意看!这个男人叫小帅」让人头皮发麻,
真正的问题是,我们无法辨别哪些内容是AI生成的。
养大了这些擅长一本正经胡说八道的AI,人类面临的麻烦也随之而来。
(LLM:人与AI之间怎么连最基本的信任都没有了?)
子曰,解铃还须系铃人。近日,谷歌DeepMind团队发表的一项研究登上了Nature期刊的封面:

研究人员开发了一种名为SynthID-Text的水印方案,可应用于生产级别的LLM,跟踪AI生成的文本内容,使其无所遁形。

论文地址:https://www.nature.com/articles/s41586-024-08025-4
一般来说,文本水印跟我们平时看到的图片水印是不一样的。
图片可以采用明显的防盗水印,或者为了不影响内容观感而仅仅修改一些像素,人眼发现不了。
但本文添加的水印想要隐形貌似不太容易。

为了不影响LLM生成文本的质量,SynthID-Text使用了一种新颖的采样算法(Tournament sampling)。
与现有方法相比,检测率更高,并且能够通过配置来平衡文本质量与水印的可检测性。
怎么证明文本质量不受影响?直接放到自家的Gemini和Gemini Advanced上实战。
研究人员评估了实时交互的近2000万个响应,用户反馈正常。
SynthID-Text的实现仅仅修改了采样程序,不影响LLM的训练,同时在推理时的延迟也可以忽略不计。
另外,为了配合LLM的实际使用场景,研究者还将水印与推测采样集成在一起,使之真正应用于生产系统。
大模型的指纹
下面跟小编一起来看下DeepMind的水印有何独到之处。
识别AI生成的内容,目前有三种方法。
第一种方法是在LLM生成的时候留个底,这在成本和隐私方面都存在问题;
第二种方法是事后检测,计算文本的统计特征或者训练AI分类器,运行成本很高,且限制在自己的数据域内;
而第三种就是加水印了,可以在文本生成前(训练阶段,数据驱动水印)、生成过程中、和生成后(基于编辑的水印)添加。
数据驱动水印需要使用特定短语触发,基于编辑的水印一般是同义词替换或插入特殊Unicode字符。这两种方法都会在文本中留下明显的伪影。
SynthID-Text 生成水印
本文的方法则是在生成过程中添加水印。
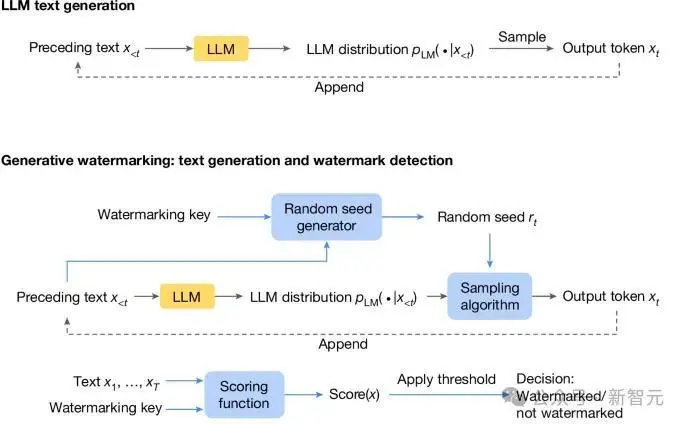
下图是标准的LLM生成过程:根据之前的token计算当前时刻token的概率分布,然后采样输出next token。

在此基础之上,生成水印方案由三个新加入的组件组成(下图蓝色框):随机种子生成器、采样算法和评分函数。
随机种子生成器在每个生成步骤(t)上提供随机种子 r(t)(基于之前的文本token以及水印key),采样算法使用 r(t) 从LLM生成的分布中采样下一个token。
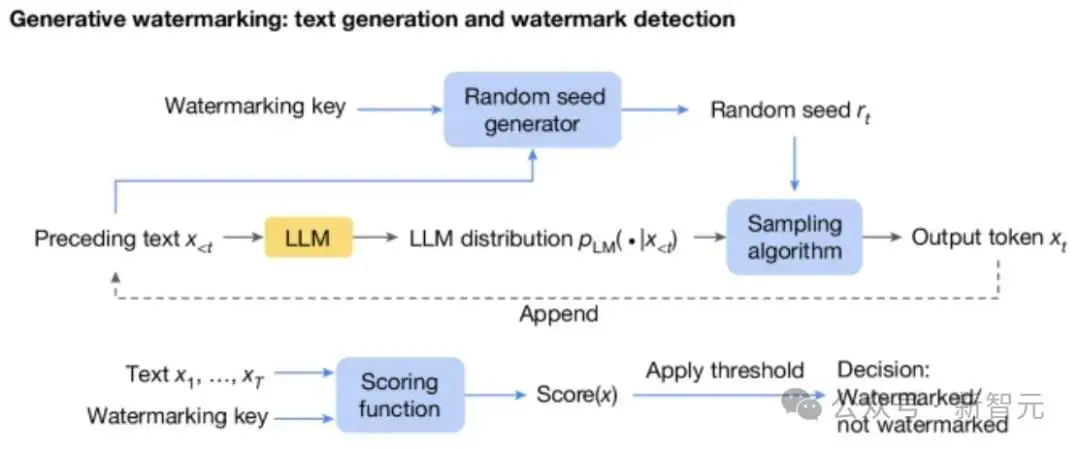
通过这种方式,采样算法把水印引入了next token中(即r(t)和x(t)的相关性),在检测水印的时候,就使用Scoring函数来衡量这种相关性。
下面给出一个具体的例子:简单来说就是拿水印key和前几个token(这里是4个),过一个哈希函数,生成了m个向量,向量中的每个值对应一个可选的next token。

然后呢,通过打比赛的方式,从这些token中选出一个,也就是SynthID-Text使用的Tournament采样算法。
如下图所示,拿2^m个token参加m轮比赛(这里为8个token3轮比赛,token可重复),
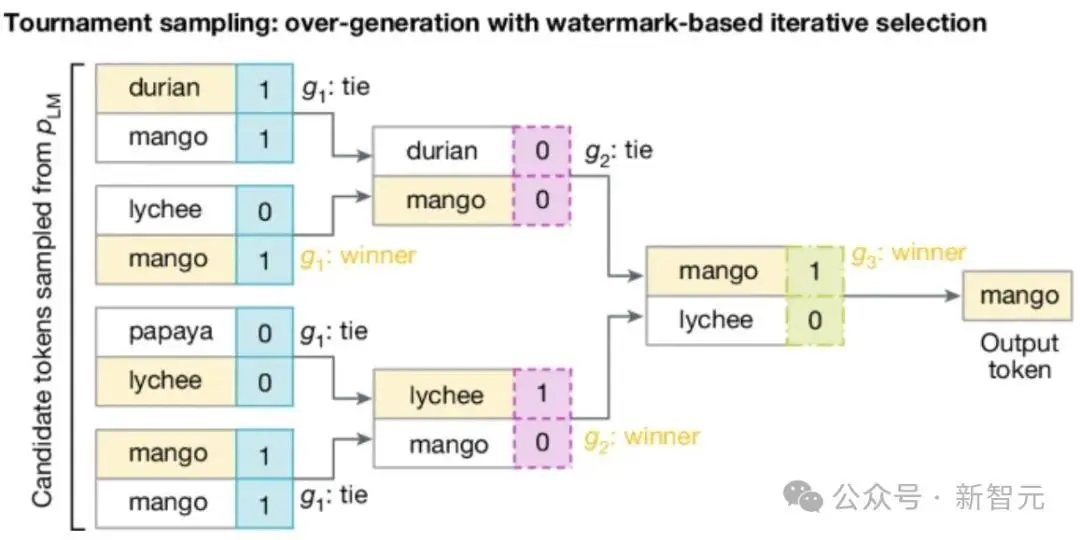
每轮中的token根据当前轮次对应的向量两两pk,胜者进入下一轮,如果打平,则随机选一个胜者。
以下是算法的伪代码:

水印检测
根据上面的赛制,最终胜出的token更有可能在所有的随机水印函数(g1,g2,...,gm)中取值更高,
所以可以使用下面的Scoring函数来检测文本:
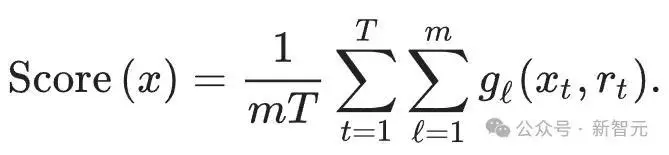
把所有的token扔进所有的水印函数中,最后计算平均值,则带水印的文本通常应该得分高于无水印的文本。
由此可知,水印检测是一个程度的问题。影响评分函数检测性能的主要因素有两个。
首先是文本的长度:较长的文本包含更多的水印证据,可以让检测有更多的统计确定性。
第二个因素是LLM本身的情况。如果LLM输出分布的熵非常低(意味着对相同的提示几乎总是返回完全相同的响应),那么锦标赛采样(Tournament)无法选择在g函数下得分更高的token。
此时,与其他生成水印的方案类似,对于熵较小的LLM,水印的效果会较差。
LLM本身的熵取决于以下几个因素:
模型(更大或更高级的模型往往更确定,因此熵更低);
来自人类反馈的强化学习会减少熵(也称为模式崩溃);
LLM的提示、温度和其他解码设置(比如top-k采样设置)。
一般来说,增加比赛的轮数(m),可以提高方法的检测性能,并降低Scoring函数的方差。
但是,可检测性不会随着层数的增加而无限增加。比赛的每一层都使用一些可用的熵来嵌入水印,水印强度会随着层数的加深而逐渐减弱。本文通过实验确定m=30。
文本质量
作者为非失真给出了由弱到强的明确定义:
最弱的版本是单token非失真,表示水印采样算法生成的token的平均分布等于LLM原始输出的分布;
更强的版本将此定义扩展到一个或多个文本序列,确保平均而言,水印方案生成特定文本或文本序列的概率与原始输出的分布相同。
当Tournament采样为每场比赛配置恰好两个参赛者时,就是单token非失真的。而如果应用重复的上下文掩码,则可以使一个或多个序列的方案不失真。
在本文的实验中,作者将SynthID-Text配置为单序列非失真,这样可以保持文本质量并提供良好的可检测性,同时在一定程度上减少响应间的多样性。
计算可扩展性
生成水印方案的计算成本通常较低,因为文本生成过程仅涉及对采样层的修改。
对于Tournament采样,在某些情况下,还可以使用矢量化来实现更高效率,在实践中,SynthID-Text引起的额外延迟可以忽略不计。
在大规模产品化系统中,文本生成过程通常比之前描述的简单循环更复杂。
产品化系统通常使用speculative sampling来加速大模型的文本生成。
小编曾在将Llama训练成Mamba的文章中,介绍过大模型的推测解码过程。
简单来说就是用原来的大模型蒸馏出一个小模型,小模型跑得快,先生成出一个序列,大模型再对这个序列进行验证,由于kv cache的特性,发现不符合要求的token,可以精准回滚。
这样的做法既保证了输出的质量,又充分利用了显卡的计算能力,当然主要的目的是为了加速。
所以在实践中,生成水印的方案需要与推测采样相结合,才能真正应用于生产系统。
对此,研究人员提出了两种带有推测采样算法的生成水印。
一是高可检测性水印推测采样,保留了水印的可检测性,但可能会降低推测采样的效率(从而增加整体延迟)。
二是快速水印推测采样,(当水印是单token非失真时)保留了推测采样的效率,但可能会降低水印的可检测性。
作者还提出了一个可学习的贝叶斯评分函数,以提高后一种方法的可检测性。当速度在生产环境中很重要时,快速带水印的推测采样最有用。
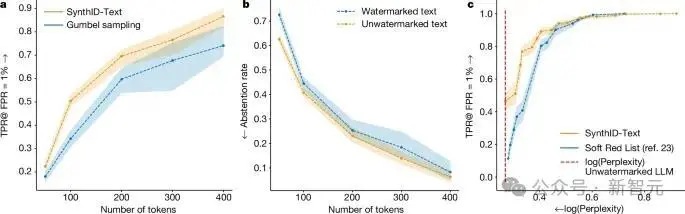
上图表明,在非失真类别中,对于相同长度的文本,非失真SynthID-Text提供比Gumbel采样更好的可检测性。在较低熵的设置(如较低的温度)下,SynthID-Text对Gumbel采样的改进更大。
Prev Chapter:消息称Perplexity AI搜索公司正融资5亿美元,市值将破90亿美元
Next Chapter:谷歌Gemini 2.0 AI模型现踪迹,响应速度更快
评论区
- 这篇文章还没有收到评论,赶紧来抢沙发吧~
【随机内容】

