

48个文生视频+技术报告,揭秘OpenAI最强视频GPT_tiknovel-最新最全的nft,web3,AI技术资讯技术社区
48个文生视频+技术报告,揭秘OpenAI最强视频GPT
2月16日消息,今日凌晨,OpenAI推出其首款文生视频大模型Sora。该模型能根据提示词生成长达1分钟的视频,或者扩展生成的视频使其更长,同时视觉质量相当惊艳。

相比以往的视频模型,Sora的亮点非常明显,不仅对文本理解更深刻,可以准确地呈现提示词,而且能在一个生成的视频中创建多个镜头,准确地保留角色和视觉风格。

尤其值得一提的是,Sora在细节处理上做得非常出挑,能够理解复杂场景中不同元素之间的物理属性及其关系,正确呈现它们在物理世界中的存在方式。

除了支持文本指令输入外,该模型支持生成图像,也支持将现有静止图像变成视频,能对现有视频进行扩展、将两个视频衔接并填充缺失的帧。
其3D仿真能力非常突出,无论是制作短视频、动画、电影画面,还是渲染视频游戏,Sora都展示出了令人期待的落地前景。

为了全方位展示Sora的水平,OpenAI一口气放出了48个用Sora直接生成、未经修改、长度不等(9秒~60秒)的视频。下文附有48个视频的完整展示,火眼金睛的读者朋友们可以研究下这些视频的准确程度,或者从专业性上找找bug。
OpenAI将这个大模型称作是“能够理解和模拟现实世界的模型的基础”,相信其能力“将是实现AGI的重要里程碑”。其技术报告今日刚刚新鲜出炉:

技术报告指路:https://openai.com/research/video-generation-models-as-world-simulators
一、Sora技术拆解:60秒视频、理解力强大、一次预见多帧
OpenAI首个文生视频大模型Sora是一个在可变持续时间、分辨率、宽高比的视频和图像上联合训练的文本条件扩散模型。

与GPT模型类似,Sora使用Transformer架构,扩展性很强大,能一次生成时长1分钟的视频,或者扩展生成的视频使其更长。
随着训练计算量增加,样本质量显著提高。

具体来看,该模型能生成具有多个角色、特定类型的运动以及精确的主题和背景细节的复杂场景。
通过赋予模型一次多帧的预见能力,OpenAI团队解决了一个具有挑战性的问题,即确保一个主题即使暂时消失在视野之外也保持不变。
过去的图像和视频生成方法通常是调整大小,裁剪或修剪视频到标准尺寸——例如,4秒视频、256×256分辨率。而OpenAI发现在原始大小的数据上进行训练提供了一些好处:
(1)采样的灵活性:Sora可以采样宽屏1920x1080p视频、垂直1080×1920视频以及介于两者之间的所有视频。这让Sora可直接以不同设备的原始宽高比为其创建内容。它还支持在生成全分辨率的内容之前,以较小的尺寸快速创建内容原型——所有内容都使用相同的模型。

(2)改进框架和构图:OpenAI通过经验发现,在视频的原始长宽比上进行训练可以改善构图和框架。研究团队将Sora与其模型的一个版本进行比较,该版本将所有训练视频裁剪为方形。在正方形裁剪(左图)上训练的模型有时会生成仅部分显示主题的视频。相比之下,来自Sora(右图)的视频有改进的帧。

此外,Sora文生视频大模型具备如下特点:
1、强大的语言理解能力:训练文本到视频生成系统需要大量带有相应文本说明的视频。OpenAI将DALL·E 3中介绍的字幕重配技术(Recaptioning)应用到视频中,首先训练一个高度描述性的字幕模型,然后使用它为其训练集中的所有视频生成文本字幕。OpenAI发现,对高度描述性的视频字幕进行训练可提高文本保真度以及视频的整体质量。与DALL·E 3类似,研究团队还利用GPT将简短的用户提示转换为更长的详细字幕,并将其发送到视频模型。这使得Sora能准确按照用户提示生成高质量的视频。

2、支持现有的图像或视频输入:这种功能使Sora能够执行广泛的图像和视频编辑任务——创建完美的循环视频、动画静态图像、向前或向后扩展视频等。比如,基于DALL·E 3图像生成视频,从一个生成的视频片段开始向前/向后扩展视频,编辑转换视频的风格/环境,将两个输入视频无缝衔接在一起。


3、图像生成功能:研究团队通过在一个时间范围为一帧的空间网格中排列高斯噪声块来实现这一点。该模型可以生成可变大小的图像,最高可达2048 × 2048分辨率。

4、新兴的仿真能力:OpenAI发现视频模型在大规模训练时表现出许多有趣的突发能力。这些功能使Sora能够从现实世界中模拟人、动物和环境的某些方面。Sora可以生成带有动态摄像机运动的视频。随着摄像机的移动和旋转,人物和场景元素在三维空间中始终如一地移动。
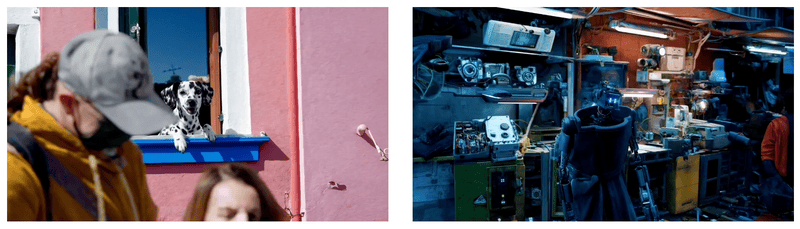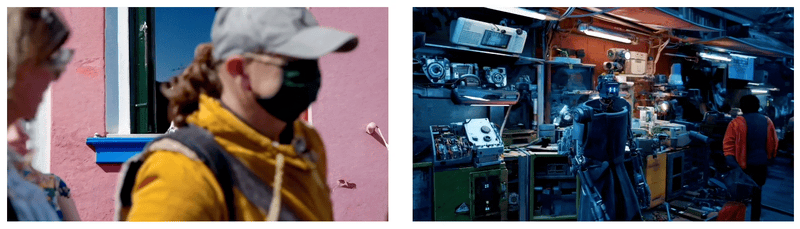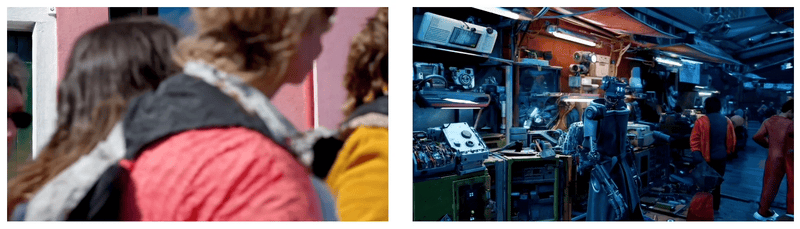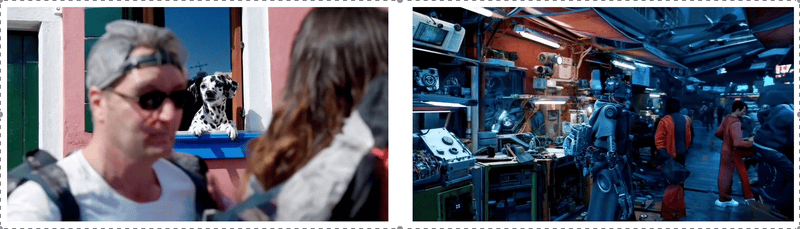
Sora经常能够有效地为短期和长期依赖关系建模,可以在单个样本中生成同一角色的多个镜头,在整个视频中保持其外观一致。该模型有时可以用简单的方式模拟影响世界状态的行为,例如,画家可以在画布上留下新的笔触,随着时间的推移,或者一个人吃汉堡时留下咬痕。

在模拟数字世界方面,Sora能够模拟人工过程,比如视频游戏,可在高保真度渲染世界及其动态的同时,用基本策略控制《我的世界》中的玩家。

这些功能表明,视频模型的持续扩展是发展物理和数字世界以及生活在其中的物体、动物和人的高性能模拟器的一条有希望的道路。
OpenAI从大语言模型获得灵感,大语言模型的成功部分归功于tokens优雅地统一了文本代码、数学及各种自然语言的不同模式。Sora研究则考虑到让视觉数据的生成模型继承这些优点。
此前视觉patch已经被证明是视觉数据模型的有效表示。OpenAI发现patch是一种高度可扩展且有效的表示形式,可用于在不同类型的视频和图像上训练生成模型。
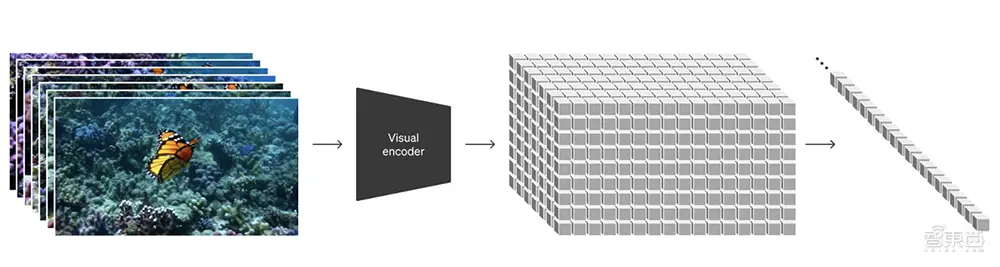
OpenAI将视频转换成patch,训练了一个降低视觉数据维度的网络,该网络将原始视频作为输入并输出在时间和空间上压缩的潜在表示。Sora在这个压缩的潜在空间中接受训练并随后生成视频。 OpenAI还训练了相应的解码器模型。
给定一个压缩的输入视频,研究团队提取一系列时空patch,充当Transformer tokens,这种基于patch的表示使得Sora能对不同时长、宽高比、分辨率的视频和图像进行训练。在推理时,可通过在适当大小的网格中排列随机初始化的patches来控制生成视频的大小。
Sora是一个扩散模型;输入一个噪声patch,它被训练来预测原始的“干净”patch。在这项工作中,OpenAI发现扩散Transformer可以作为视频模型有效扩展。
二、48个视频Demo:动漫电影、逼真自然、魔幻大片
OpenAI一共放出了48个视频来展示Sora模型的强大之处。受站点上传限制,下文主要以动图形式来简要呈现这些生成视频的部分视觉效果。
提示词1:一个时髦的女人走在东京的街道上,到处都是温暖的霓虹灯和生动的城市标志。她穿着黑色皮夹克、红色长裙、黑色靴子,拿着一个黑色钱包。她戴着太阳镜,涂着红色的口红。她走起路来自信而随意。街道是潮湿和反光的,创造了一个彩色灯光的镜子效果。许多行人走来走去。

提示词2:几只巨大的长毛猛犸象穿过一片白雪覆盖的草地,它们长长的毛茸茸的皮毛在风中轻拂,远处白雪覆盖的树木和戏剧性的雪山,午后的光线与缕缕的云和远处的太阳创造了温暖的光芒,低相机的视角是惊人的,捕捉到了美丽的摄影,景深的大型毛茸茸的哺乳动物。

提示词3:这是一部电影预告片,讲述了30岁的太空人戴着红色羊毛针织摩托车头盔的冒险经历,蓝天,盐沙漠,电影风格,用35毫米胶片拍摄,色彩鲜艳。

提示词4:无人机拍摄的海浪冲击着大苏尔加雷角海滩上崎岖的悬崖。蓝色的海水拍打着白色的波浪,夕阳的金色光芒照亮了岩石海岸。远处有一座小岛,岛上有一座灯塔,悬崖边上长满了绿色的灌木丛。从公路到海滩的陡峭落差是一个戏剧性的壮举,悬崖的边缘突出在海面上。这是一幅捕捉到海岸原始美景和太平洋海岸公路崎岖景观的景色。

提示词5:动画场景特写了一个毛茸茸的矮个子怪物跪在融化的红烛旁。美术风格是3D和现实的,重点是照明和纹理。这幅画的气氛是一种惊奇和好奇,因为怪物睁大眼睛,张开嘴巴凝视着火焰。它的姿势和表情传达了一种天真和顽皮的感觉,好像它是第一次探索周围的世界。暖色和戏剧性灯光的使用进一步增强了图像的舒适氛围。

提示词6:一个华丽渲染的珊瑚礁纸工艺品世界,到处都是五颜六色的鱼和海洋生物。

提示词7:这个维多利亚冠鸽的特写展示了它引人注目的蓝色羽毛和红色胸部。它的羽冠是由精致的花边羽毛制成的,而它的眼睛是醒目的红色。鸟的头微微向一侧倾斜,给人一种帝王和威严的印象。背景是模糊的,吸引人们注意到这只鸟引人注目的外表。

提示词8:两艘海盗船在一杯咖啡中航行时相互争斗的逼真特写视频。

提示词9:一个20多岁的年轻人坐在天空的一片云上读书。

提示词10:淘金热时期加州的历史镜头

提示词11:一个玻璃球的近景,里面有一个禅宗花园。球体中有一个小矮人正在耙花园,并在沙子上创造图案。

提示词12:一个24岁的女人眨着眼睛的极端特写,站在马拉喀什的神奇时刻,电影胶片拍摄,70mm,景深,生动的色彩,电影感。

提示词13:一只卡通袋鼠跳迪斯科。

提示词14:一个美丽的自制视频,展示了2056年尼日利亚拉各斯的人们。用手机摄像头拍摄的。

提示词15:一个培养皿,里面生长着竹林,小熊猫在里面跑来跑去。

提示词16:摄像机围绕着一大堆老式电视旋转,这些电视播放着不同的节目——20世纪50年代的科幻电影、恐怖电影、新闻、静态、70年代的情景喜剧等,背景设在纽约博物馆的一个大型画廊里。

提示词17:一个小的、圆的、毛茸茸的、有一双大而富有表现力的眼睛的生物探索了一个充满活力的魔法森林的3D动画。这种动物是兔子和松鼠的异想天开的混合体,有着柔软的蓝色皮毛和浓密的条纹尾巴。它沿着波光粼粼的小溪跳跃,惊奇地睁大了眼睛。森林里充满了神奇的元素:发光和变色的花朵,紫色和银色叶子的树木,以及像萤火虫一样的小浮动灯。这只生物停下来和一群在蘑菇圈周围跳舞的小仙女嬉戏。这只生物敬畏地仰望着一棵巨大的、发光的树,这棵树似乎是森林的中心。

提示词18:摄像机跟在一辆黑色车顶架的白色复古SUV后面,它在陡峭的山坡上沿着松树环绕的陡峭土路加速行驶,灰尘从轮胎上扬起,阳光照在越野车上,在土路上加速行驶,在现场投下温暖的光芒。这条土路弯弯曲曲地延伸到远处,看不到其他的汽车或车辆。道路两旁的树木都是红杉,点缀着一片片绿色植物。从后面看到的汽车跟随曲线轻松,使它看起来好像是在崎岖不平的地形上行驶。土路本身被陡峭的丘陵和山脉包围,上面是清澈的蓝天和缕缕的云。

提示词19:火车在东京郊区行驶时,车窗上的倒影。

提示词20:一架无人机摄像机环绕着一座美丽的历史悠久的教堂,这座教堂建在阿马尔菲海岸的岩石上,这张照片展示了历史和宏伟的建筑细节,分层的小路和露台,海浪撞击着下面的岩石,俯瞰着意大利阿马尔菲海岸的海岸水域和丘陵景观,远处的几个人在露台上散步,欣赏着壮观的海景。下午温暖的阳光为现场创造了一种神奇而浪漫的感觉,美丽的摄影捕捉到了令人惊叹的景色。

提示词21:一只巨大的橙色章鱼在海底休息,与沙质和岩石地形融为一体。它的触手在身体周围展开,眼睛是闭着的。章鱼没有意识到一只帝王蟹正从岩石后面向它爬来,它的爪子抬起,准备攻击。这种螃蟹是棕色的、多刺的,有长腿和触角。这个场景是从广角拍摄的,展示了海洋的广阔和深度。海水清澈湛蓝,阳光透过来。镜头锐利,动态范围大。章鱼和螃蟹是焦点,而背景稍微模糊,创造了景深效果。

Prev Chapter:OpenAI“AI视频”工具出炉:别争了,“视频GPT”还是我的
Next Chapter:与微软竞争 苹果开发AI工具帮助开发人员编写App代码
评论区
- 这篇文章还没有收到评论,赶紧来抢沙发吧~
【随机内容】
-

Chaotic Sword God Chapter 2145 - Sitting Ducks
2024-11-14 -
Nine Star Hegemon Body Arts Chapter 4012 Heavenly Collapse Manifestation
2024-11-13 -
Chaotic Sword God Chapter 1650: Prior to the Negotiations (Four)
2024-11-14 -
Infinite Mana In The Apocalypse Chapter 1872 The Will Of A Great Commander!
2024-11-19
