

谷歌Gemini 1.5爆炸上线,多模态硬刚GPT-5!MoE首破100万极限上下文纪录_tiknovel-最新最全的nft,web3,AI技术资讯技术社区
谷歌Gemini 1.5爆炸上线,多模态硬刚GPT-5!MoE首破100万极限上下文纪录
刚刚,我们经历了LLM划时代的一夜。谷歌又在深夜发炸弹,Gemini Ultra发布还没几天,Gemini 1.5就来了。卯足劲和OpenAI微软一较高下的谷歌,开始进入了高产模式。
自家最强的Gemini 1.0 Ultra才发布没几天,谷歌又放大招了。
就在刚刚,谷歌DeepMind首席科学家Jeff Dean,以及联创兼CEO的Demis Hassabis激动地宣布了最新一代多模态大模型——Gemini 1.5系列的诞生。
其中,最高可支持10,000K token超长上下文的Gemini 1.5 Pro,也是谷歌最强的MoE大模型。
不难想象,在百万级token上下文的加持下,我们可以更加轻易地与数十万字的超长文档、拥有数百个文件的数十万行代码库、一部完整的电影等等进行交互。


同时,为了介绍这款划时代的模型,谷歌还发布了长达58页的技术报告。

论文地址:https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf
毫不夸张地说,大语言模型领域从此将进入一个全新的时代!
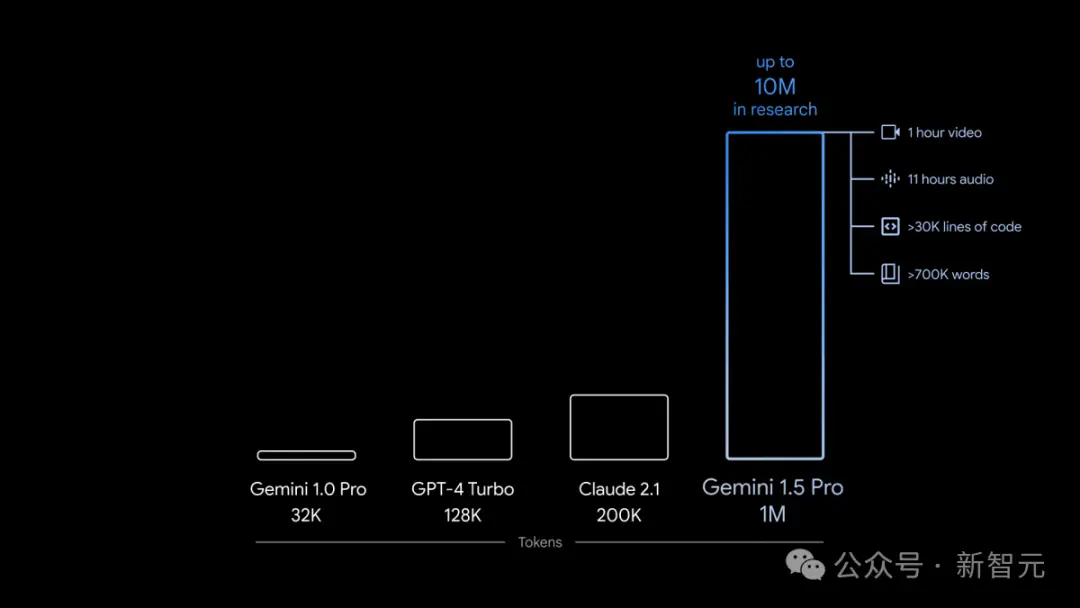
1,000,000 token超超超长上下文,全面碾压GPT-4 Turbo
在上下文窗口方面,此前的SOTA模型已经「卷」到了200K token(20万)。
如今,谷歌成功将这个数字大幅提升——能够稳定处理高达100万token(极限为1000万token),创下了最长上下文窗口的纪录。
1000万token极限海底捞针几乎全绿
首先,我们看看Gemini 1.5 Pro在多模态海底捞针测试中的成绩。
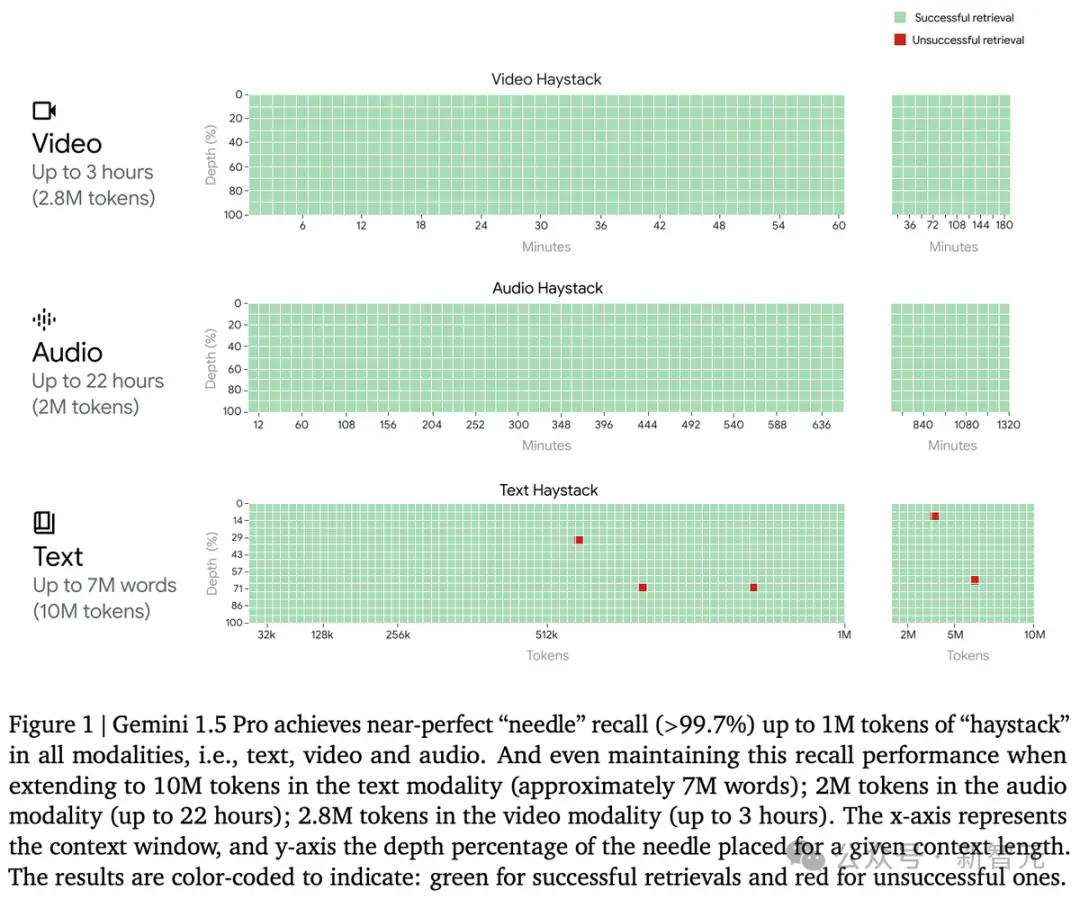
对于文本处理,Gemini 1.5 Pro在处理高达530,000 token的文本时,能够实现100%的检索完整性,在处理1,000,000 token的文本时达到99.7%的检索完整性。
甚至在处理高达10,000,000 token的文本时,检索准确性仍然高达99.2%。
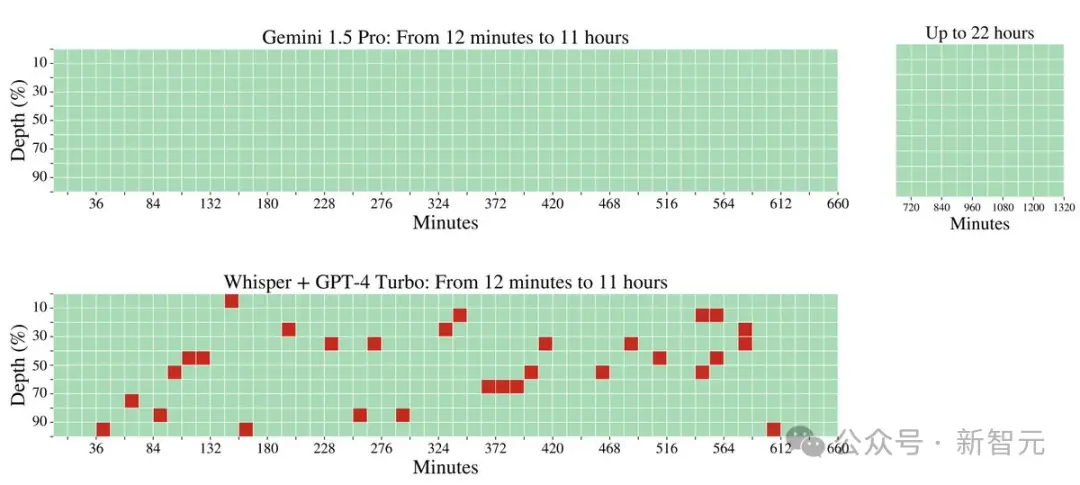
在音频处理方面,Gemini 1.5 Pro能够在大约11小时的音频资料中,100%成功检索到各种隐藏的音频片段。
在视频处理方面,Gemini 1.5 Pro能够在大约3小时的视频内容中,100%成功检索到各种隐藏的视觉元素。
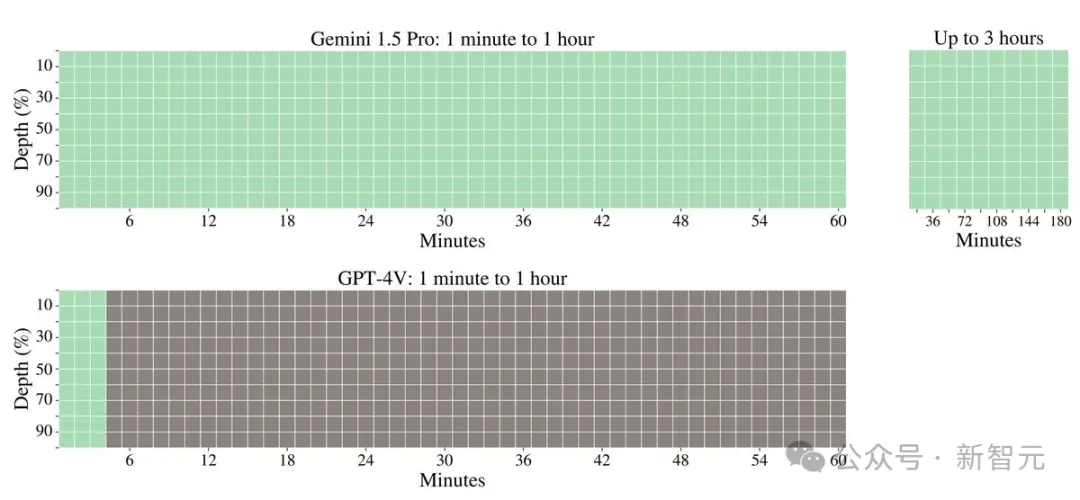
此外,谷歌研究人员还开发了一个更通用的版本的「大海捞针」测试。
在这个测试中,模型需要在一定的文本范围内检索到100个不同的特定信息片段。
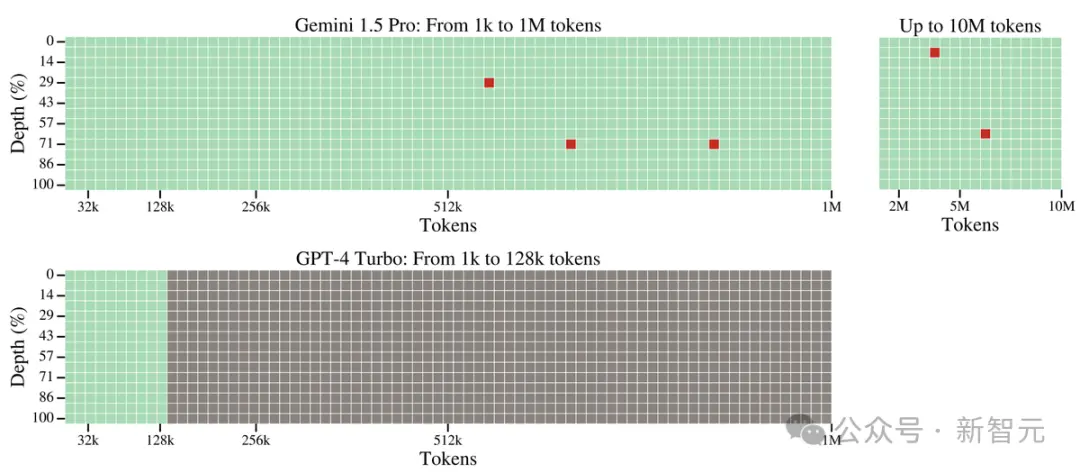
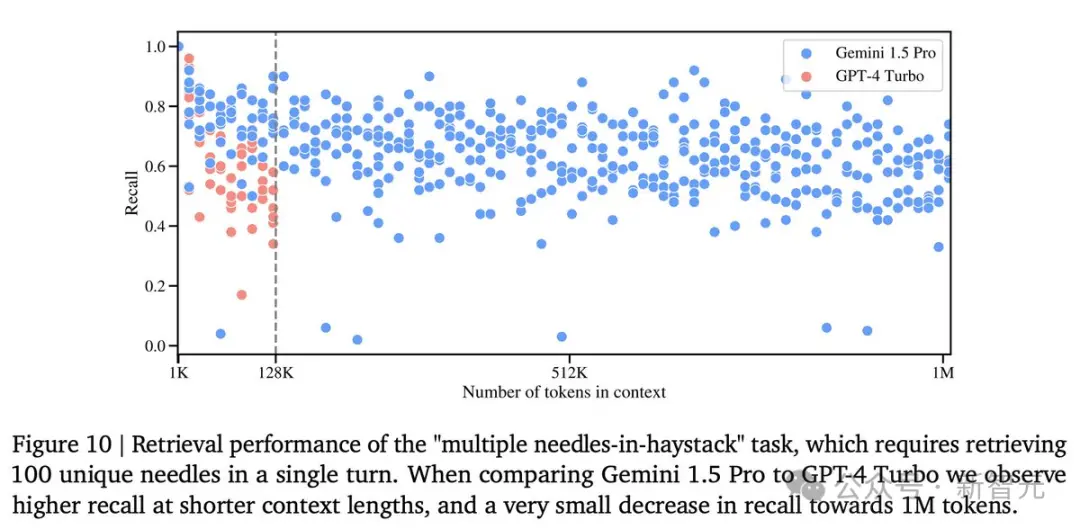
在这个测试中,Gemini 1.5 Pro在较短的文本长度上的性能超过了GPT-4-Turbo,并且在整个100万token的范围内保持了相对稳定的表现。
与之对比鲜明的是,GPT-4 Turbo的性能则飞速下降,且无法处理超过128,000 token的文本,表现惨烈。
大模型视野,被「史诗级」拓宽
LLM发展到这个阶段,模型的上下文窗口已经成为了关键的掣肘。
模型的上下文窗口由许多token组成,它们是处理单词、图像、视频、音频、代码这些信息的基础构建。
模型的上下文窗口越大,它处理给定提示时能够接纳的信息就越多——这就使得它的输出更加连贯、相关和实用。
而这次,谷歌通过一系列机器学习的创新,大幅提升了1.5 Pro的上下文窗口容量,从Gemini 1.0的原始32,000 token,直接提升到了惊人的1,000,000 token。
这就意味着,1.5 Pro能够一次性处理海量信息——比如1小时的视频、11小时的音频、超过30,000行的代码库,或是超过700,000个单词。
甚至,谷歌曾经一度成功测试了高达10,000,000的token。
深入理解海量信息
脱胎换骨的Gemini 1.5 Pro,已经可以轻松地分析给定提示中的海量内容!
它能够洞察文档中的对话、事件和细节,展现出对复杂信息的深刻理解。

我们甩给它一份阿波罗11号任务到月球的402页飞行记录,它对于多复杂的信息,都能表现出深刻的理解。
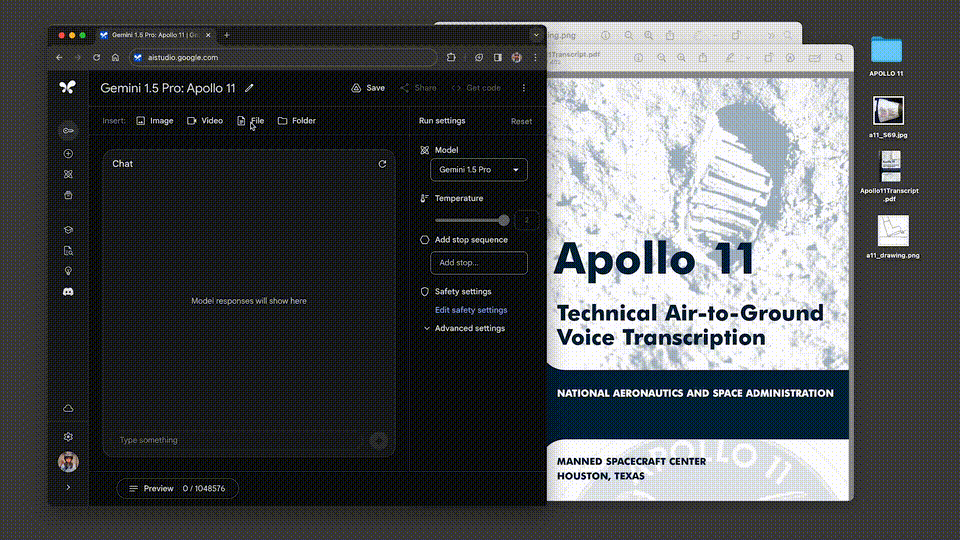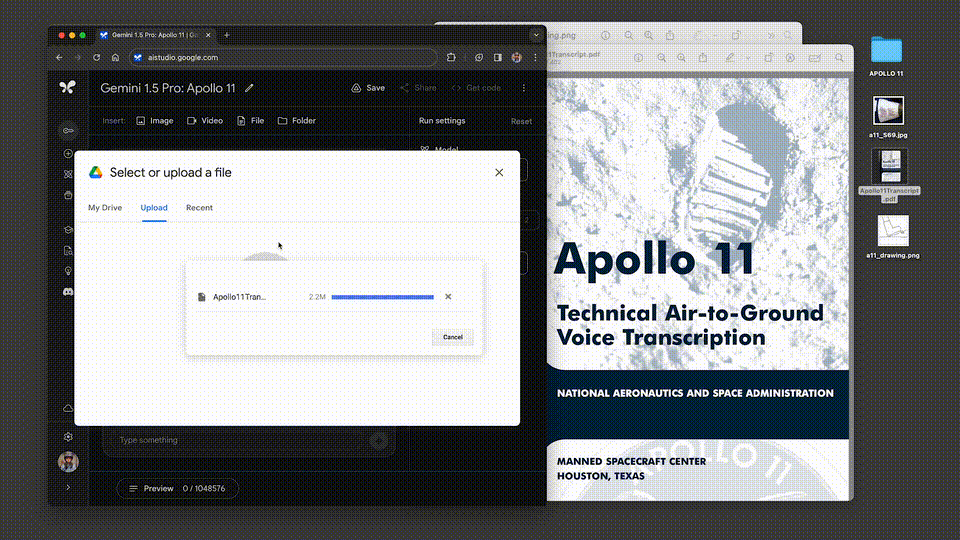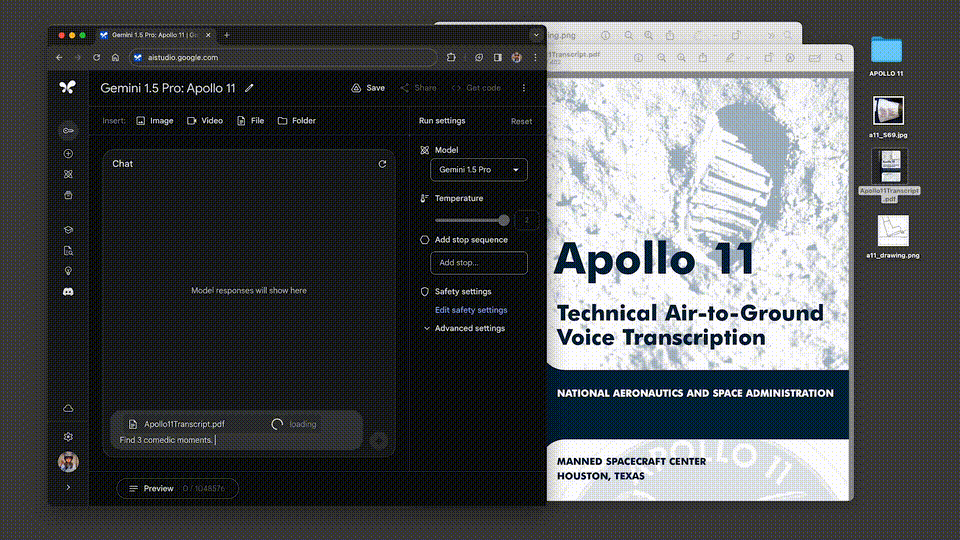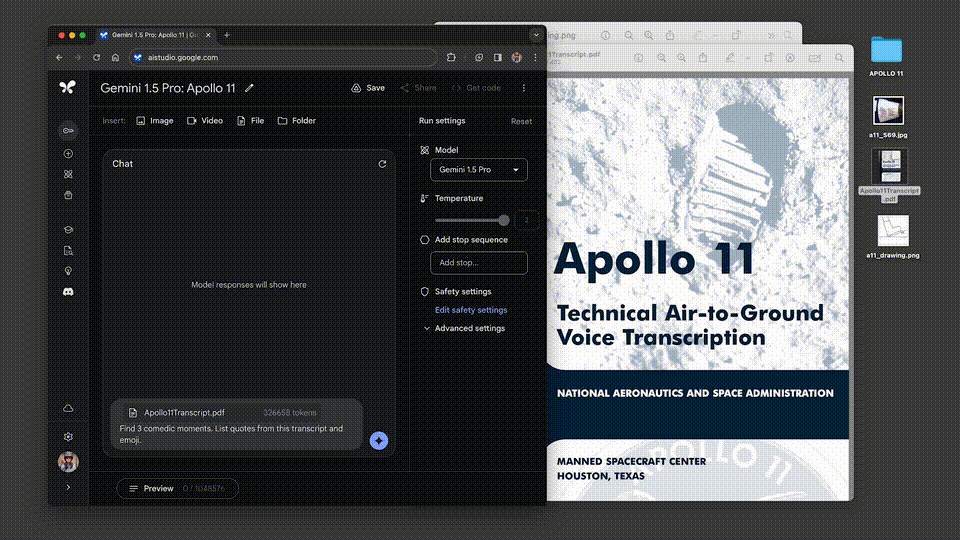
让它从文件中列举出3个喜剧性的时刻,接下来,就是见证奇迹的时刻——
才过了30秒出头,答案就已经生成了!
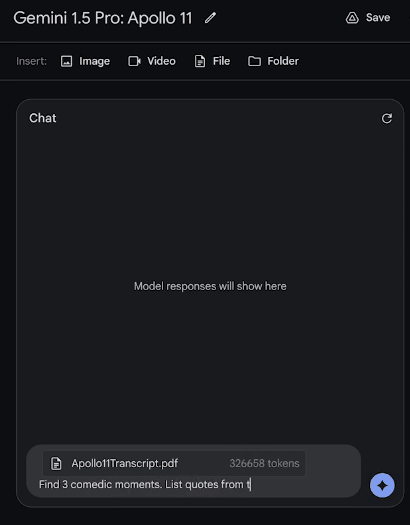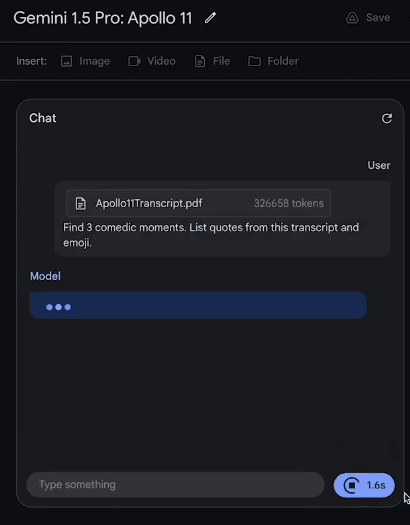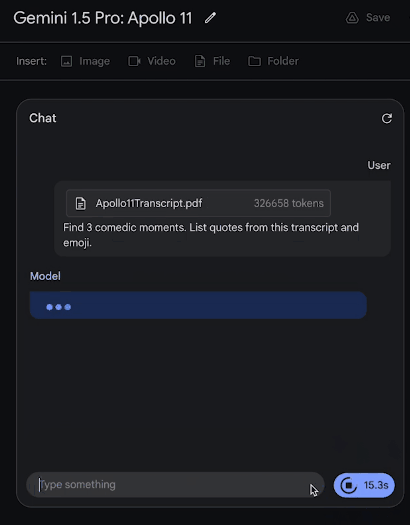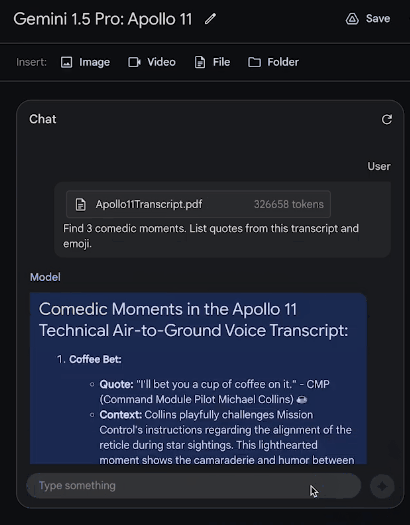
接下来,看看它的多模态功能。
把这张图输入进去,问它:这是什么时刻?
它会回答,这是阿姆斯特朗迈上月球的一小步,也是人类的一大步。

这次,谷歌还新增了一个功能,允许开发者上传多个文件(比如PDF),并提出问题。
更大的上下文窗口,就让模型能够处理更多信息,从而让输出结果更加一致、相关且实用。
横跨各种不同媒介
与此同时,Gemini 1.5 Pro还能够在视频中展现出深度的理解和推理能力!
得益于Gemini的多模态能力,上传的视频会被拆分成数千个画面(不包括音频),以便执行复杂的推理和问题解决任务。
比如,输入这部44分钟的无声电影——Buster Keaton主演的经典之作《小神探夏洛克》。
模型不仅能够精准地捕捉到电影的各个情节和发展,还能洞察到极易被忽略的细微之处。
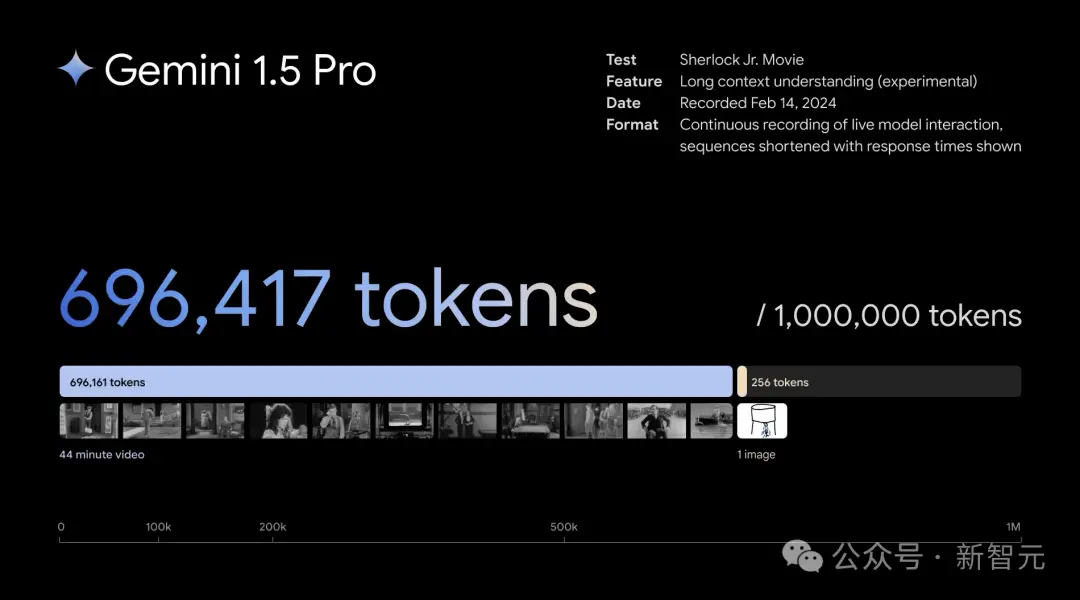
我们可以问它:找到一张纸从主角口袋中被拿出的瞬间,然后告诉我关于这个细节的信息。
令人惊喜的是,模型大约用了60秒左右就准确地找出,这个镜头是在电影的12:01,还描述出了相关细节。
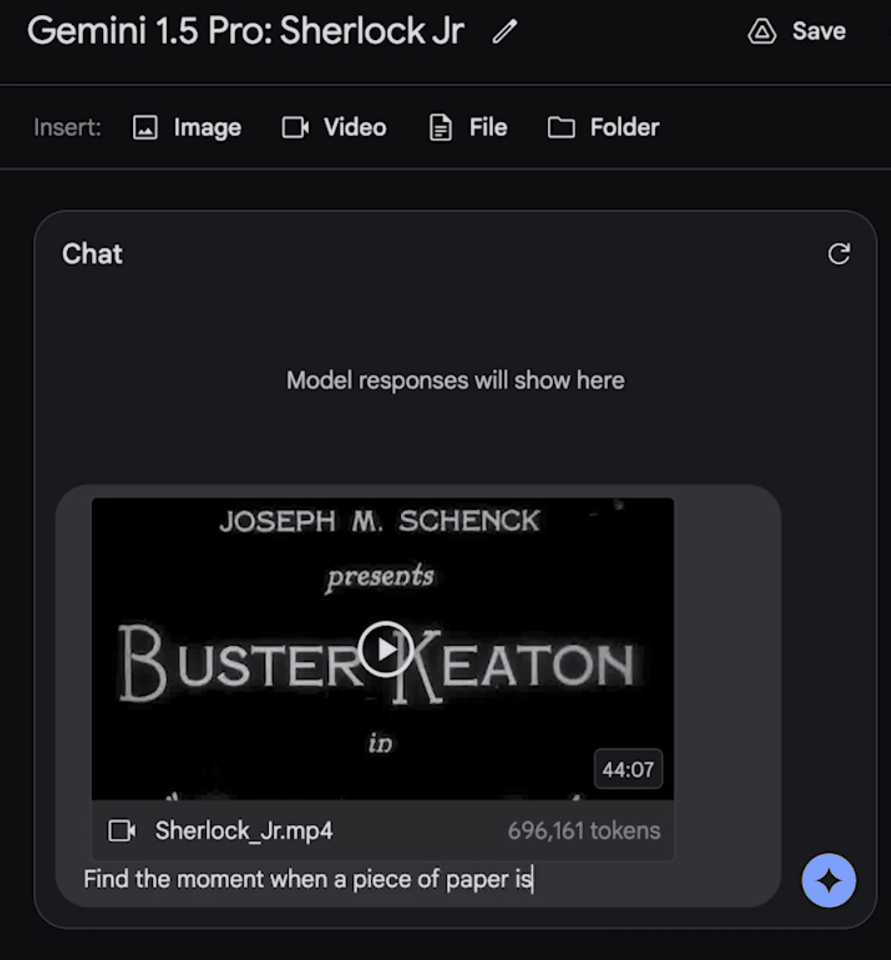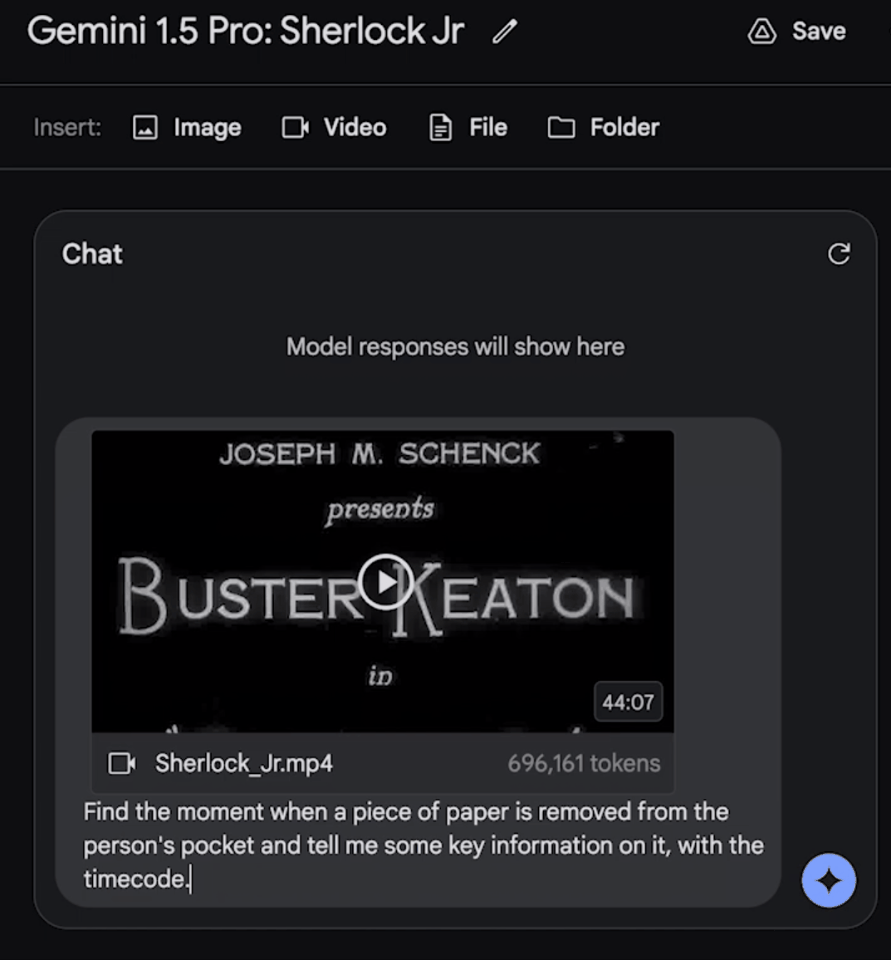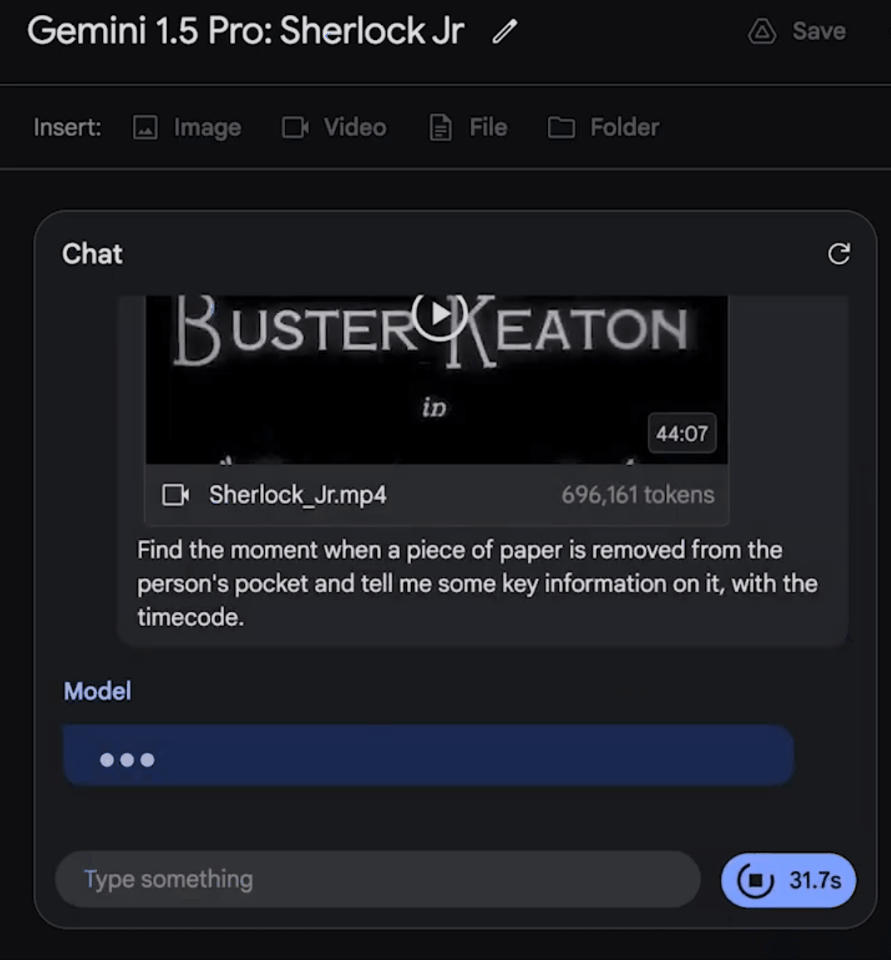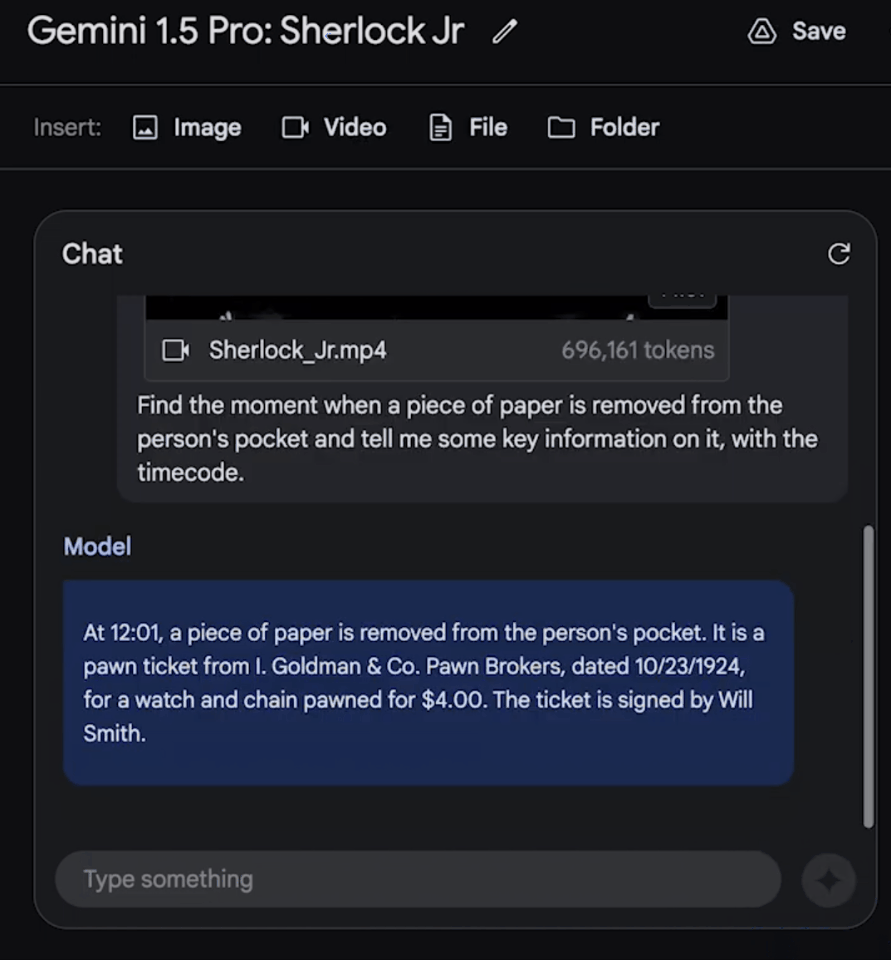
果然,模型精准找出了这个镜头的时间点,所述细节也完全准确!

输入一张粗略的涂鸦,要求模型找到电影中的对应场景,模型也在一分钟内找到了答案。
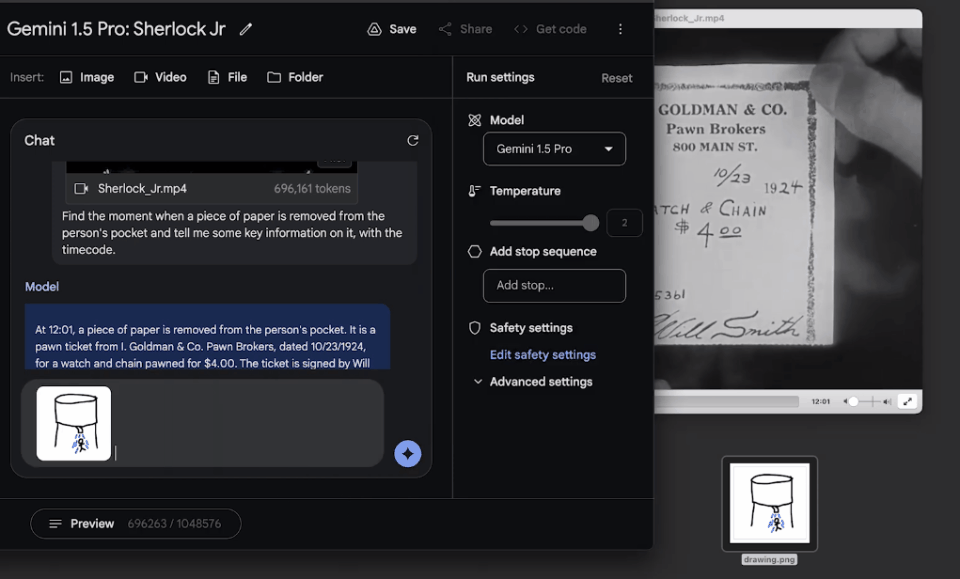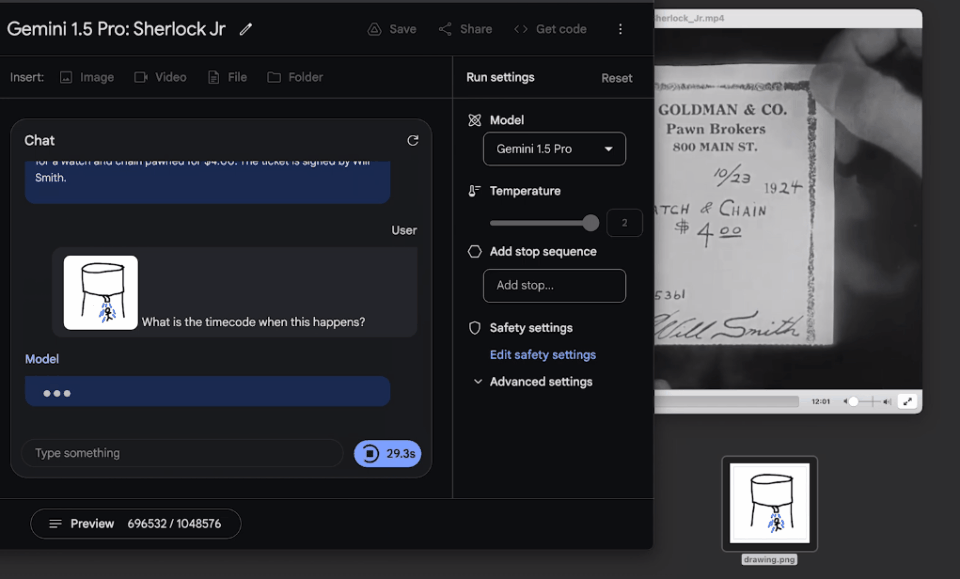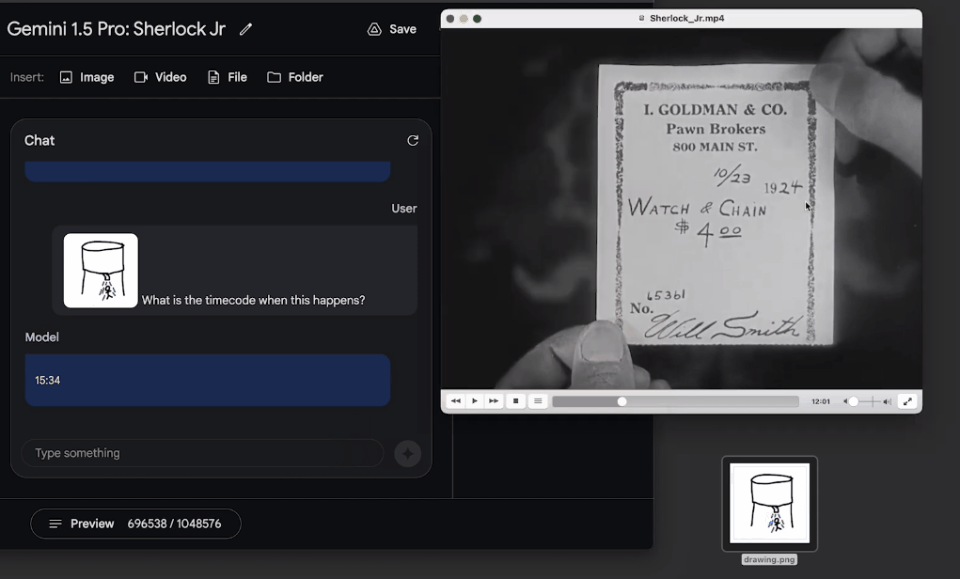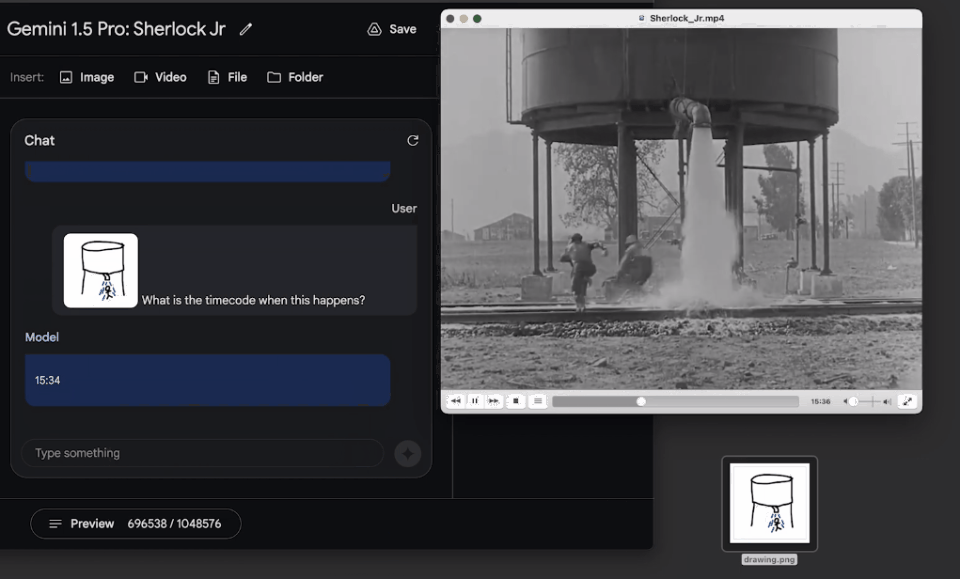
高效处理更长代码
不仅如此,Gemini 1.5 Pro在处理长达超过100,000行的代码时,还具备极强的问题解决能力。
![]()
面对如此庞大的代码量,它不仅能够深入分析各个示例,提出实用的修改建议,还能详细解释代码的各个部分是如何协同工作的。
开发者可以直接上传新的代码库,利用这个模型快速熟悉、理解代码结构。
高效架构的秘密:MoE
Gemini 1.5的设计,基于的是谷歌在Transformer和混合专家(MoE)架构方面的前沿研究。
不同于传统的作为一个庞大的神经网络运行的Transformer,MoE模型由众多小型的「专家」神经网络组成。
这些模型可以根据不同的输入类型,学会仅激活最相关的专家网络路径。
这样的专门化,就使得模型效率大幅提升。
而谷歌通过Sparsely-Gated MoE、GShard-Transformer、Switch-Transformer、M4研究,早已成为深度学习领域中MoE技术的领航者。
Gemini 1.5的架构创新带来的,不仅仅是更迅速地掌握复杂任务、保持高质量输出,在训练和部署上也变得更加高效。
因此,团队才能以惊人的速度,不断迭代和推出更先进的Gemini版本。
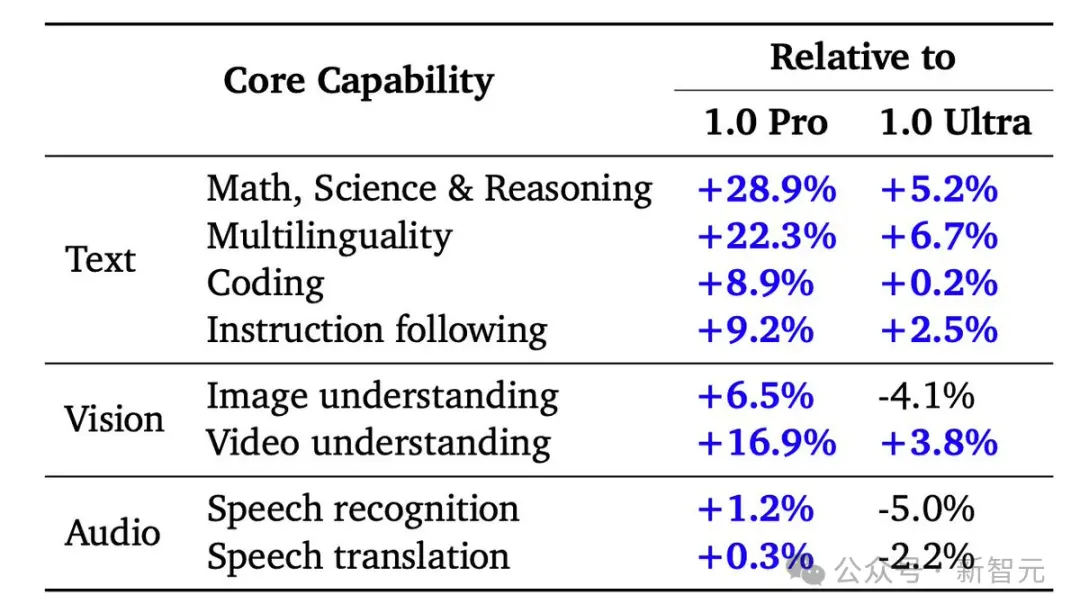
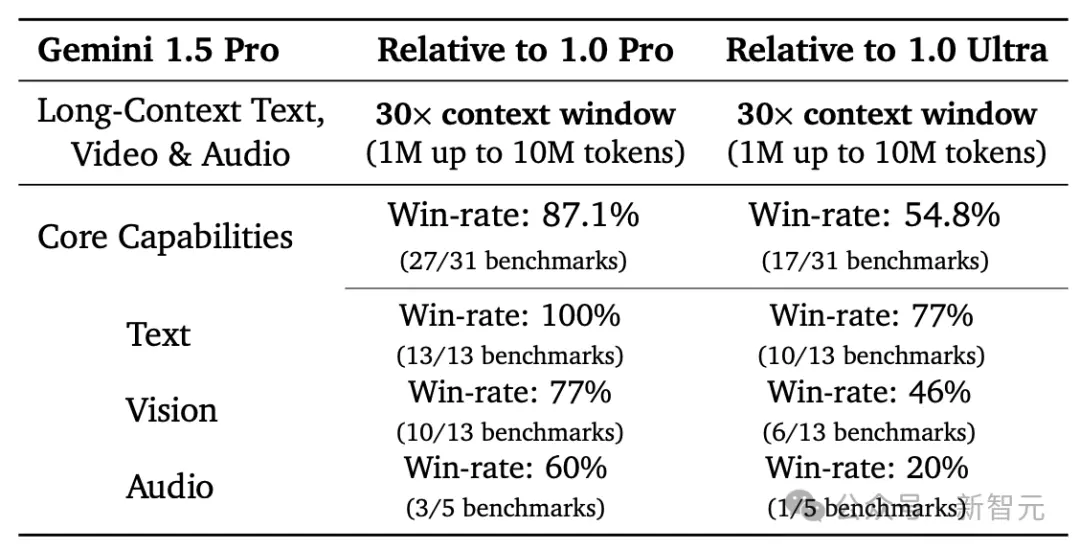
性能比肩Ultra,大幅超越1.0 Pro
在涵盖文本、代码、图像、音频和视频的综合性测试中,1.5 Pro在87%的基准测试上超越了1.0 Pro。
与1.0 Ultra在相同基准测试的比较中,1.5 Pro的表现也相差无几。
Gemini 1.5 Pro在扩大上下文窗口后,依然保持了高水平的性能。在「大海捞针 (NIAH)」测试中,它能够在长达100万token的文本块中,在99%的情况下,准确找出隐藏有特定信息的文本片段。
此外,Gemini 1.5 Pro展现了卓越的「上下文学习」能力,能够仅凭长提示中提供的信息掌握新技能,无需进一步细化调整。
这一能力在「从一本书学习机器翻译 (MTOB)」基准测试中得到了验证,该测试检验了模型学习从未接触过的信息的能力。
对于一本关于全球不足200人使用的Kalamang语的语法手册,模型能够学会将英语翻译成Kalamang,学习效果与人类学习相似。
谷歌的研究者成功地增强了模型处理长文本的能力,而且这种增强并没有影响到模型的其他功能。
虽然这项改进只用了Gemini 1.0 Ultra模型训练时间的一小部分,但1.5 Pro模型在31项性能测试中的17项上超过了1.0 Ultra模型。
与1.0 Pro模型相比,1.5 Pro在31项测试中的27项上,表现更佳。
具体结果如下:
![]()
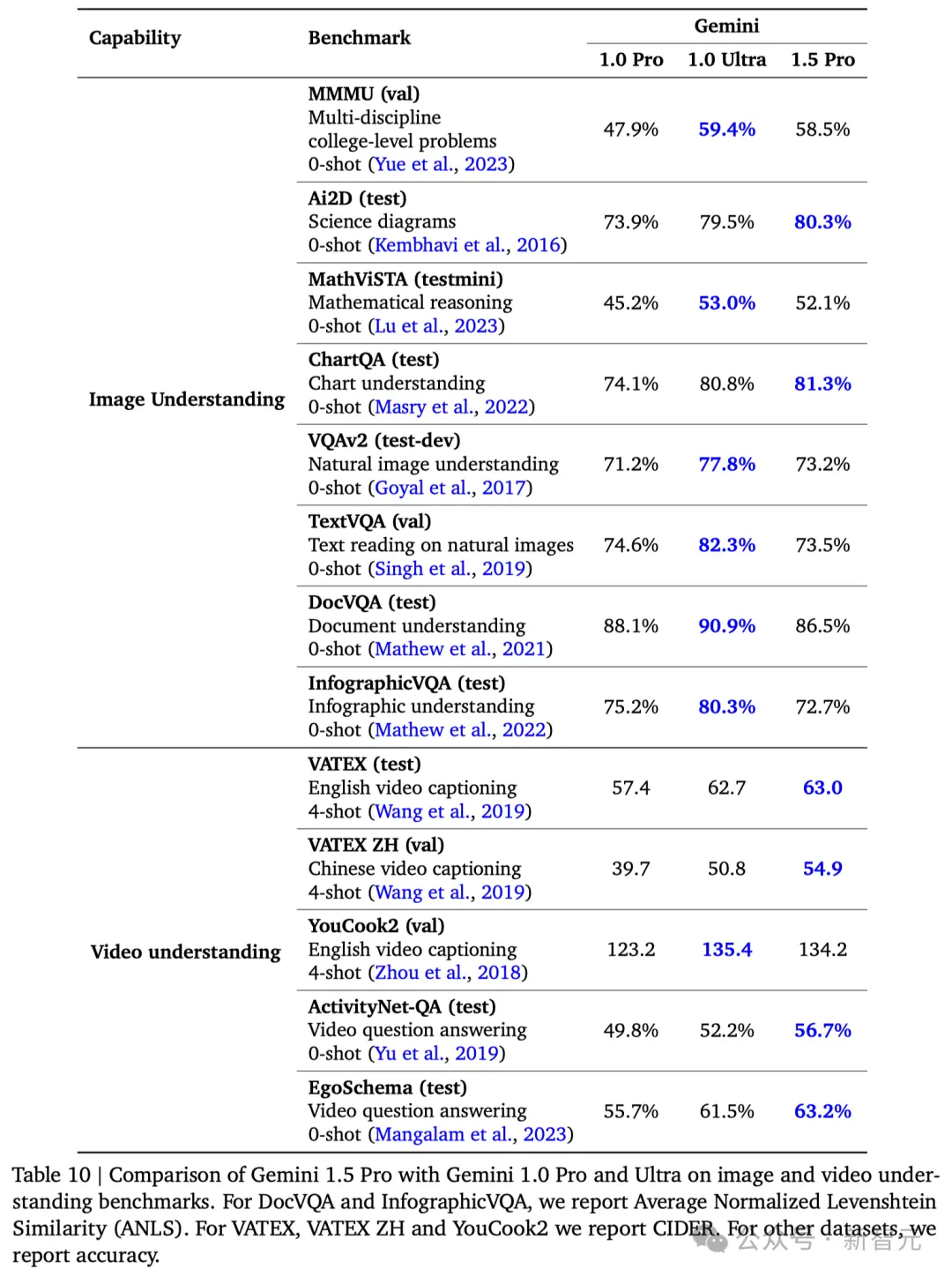

细节表现如何?
分析和掌握复杂代码库
这款模型能够迅速吸收大型代码库,并解答复杂的问题,这一点非常引人注目。
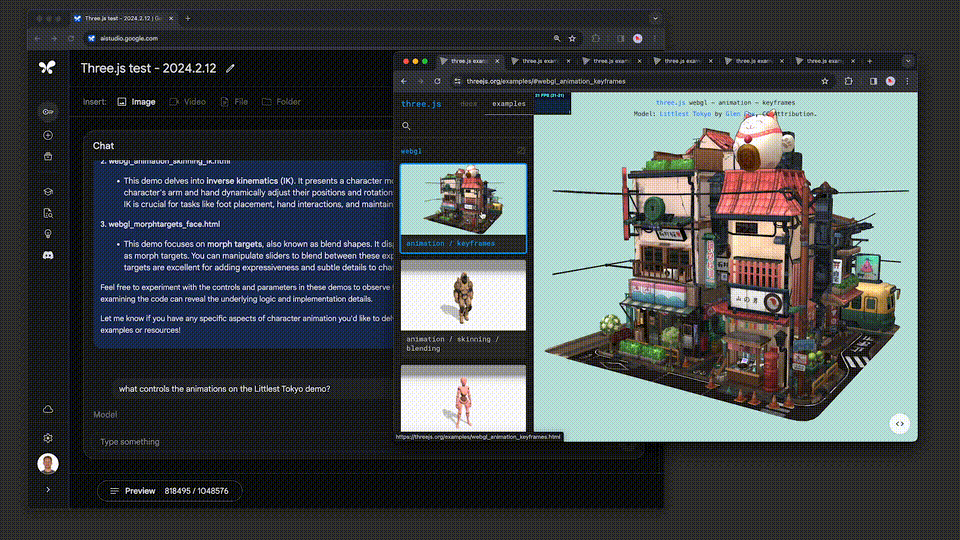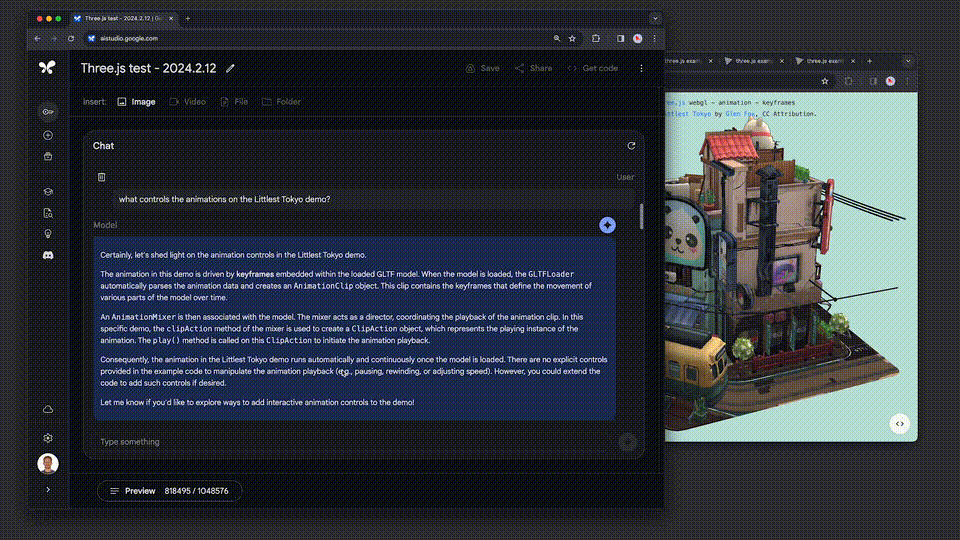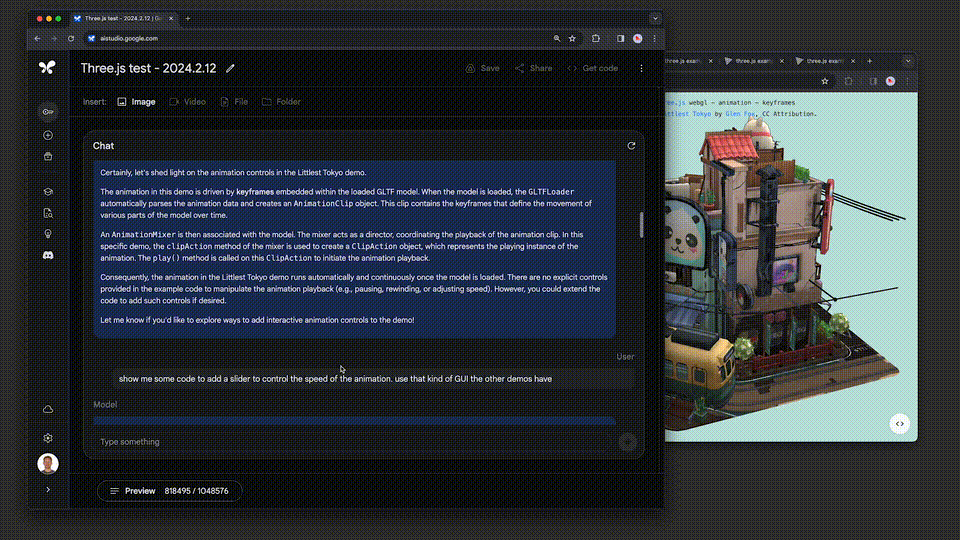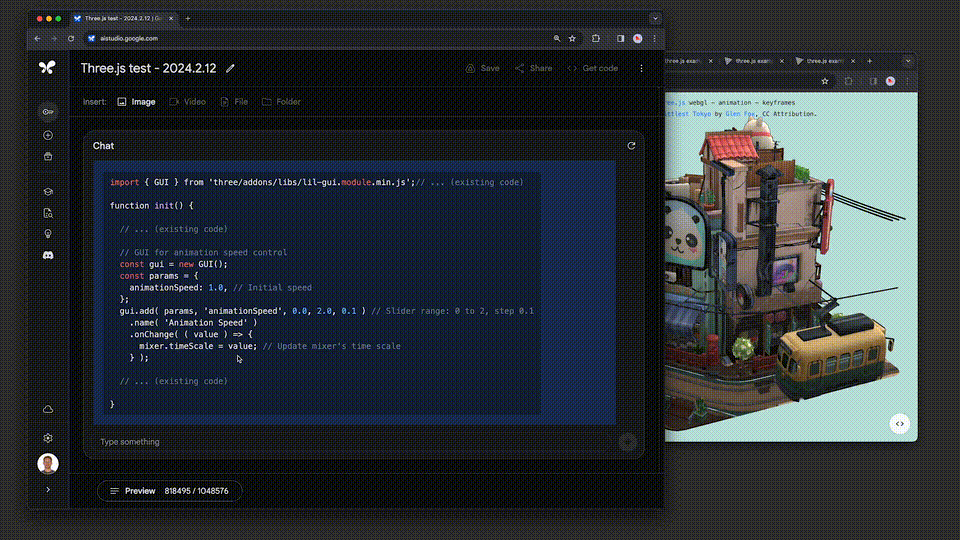
例如,three.js是一个包含约10万行代码、示例和文档等的3D Javascript库。
借助这个代码库作为背景,系统能够帮助用户深入理解代码,并能够根据人们提出的高层次要求来修改复杂的示例。
比如:「展示一些代码,用于添加一个滑块控制动画速度。采用和其他演示相同的GUI风格。」
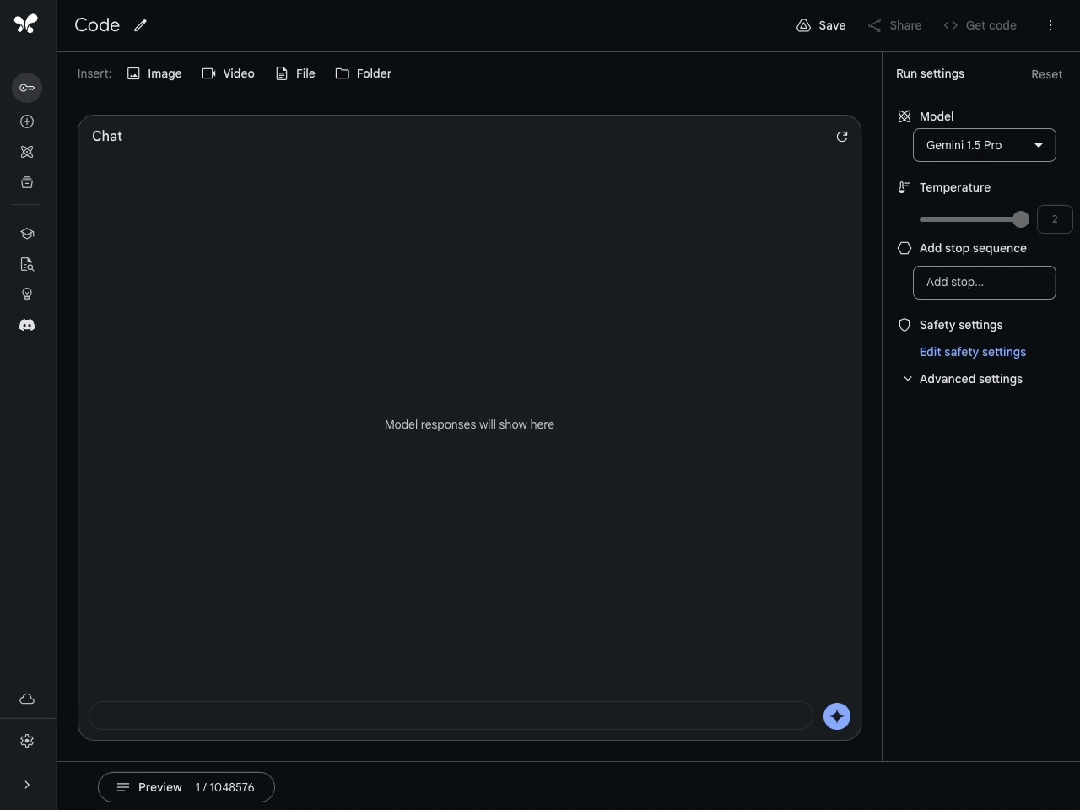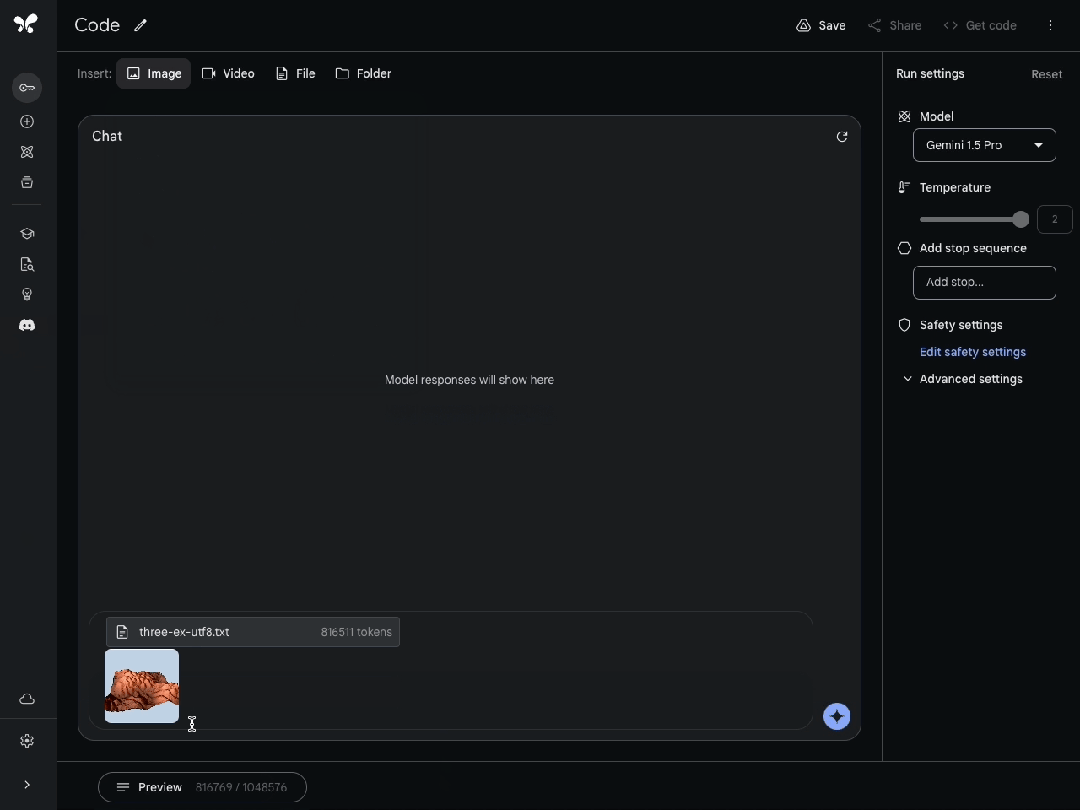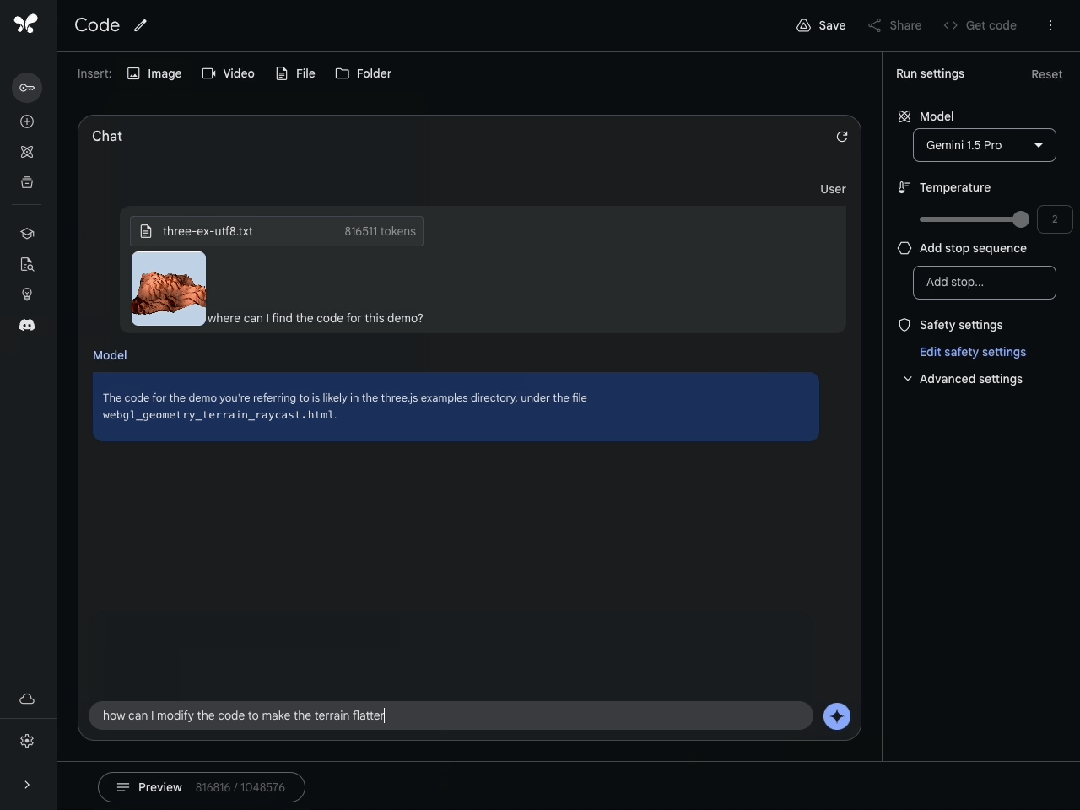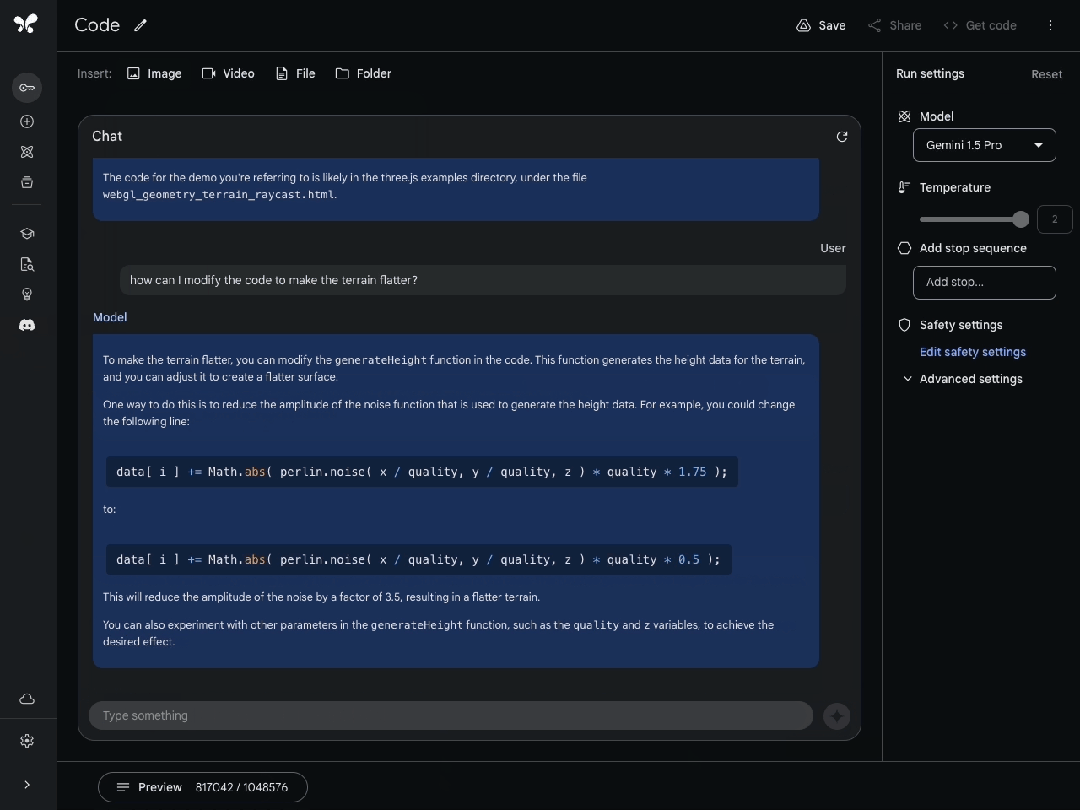
或者精确地指出需要修改的代码部分,以改变另一个示例中生成的地形的高度。
浏览庞大而陌生的代码库
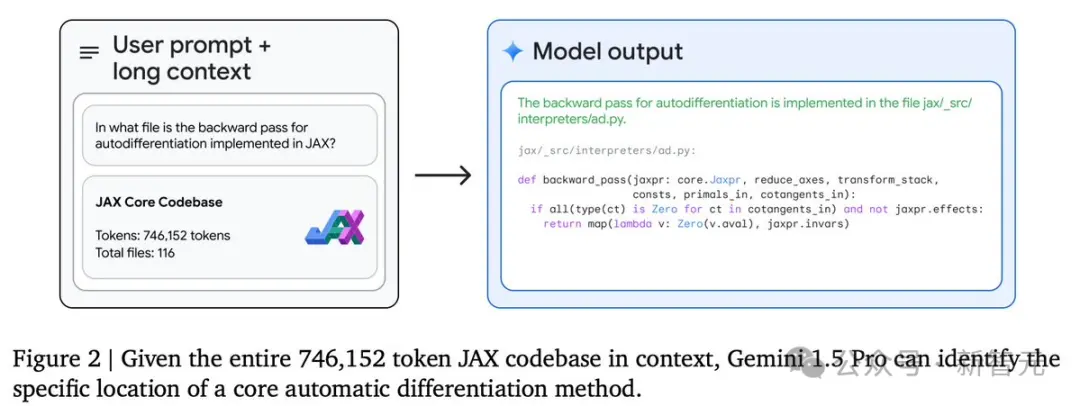
并且,模型能够帮我们理解代码,或定位某个特定功能的实现位置。
在这个例子中,模型能够处理整个包含116个文件的JAX代码库(746k token),并协助用户找到实现自动微分反向传播的确切代码位置。
显然,在深入了解一个陌生的代码库或日常工作中使用的代码库时,长上下文处理能力的价值不言而喻。
许多Gemini团队成员已经发现,Gemini 1.5 Pro的长上下文处理功能,对于Gemini 代码库大有裨益。
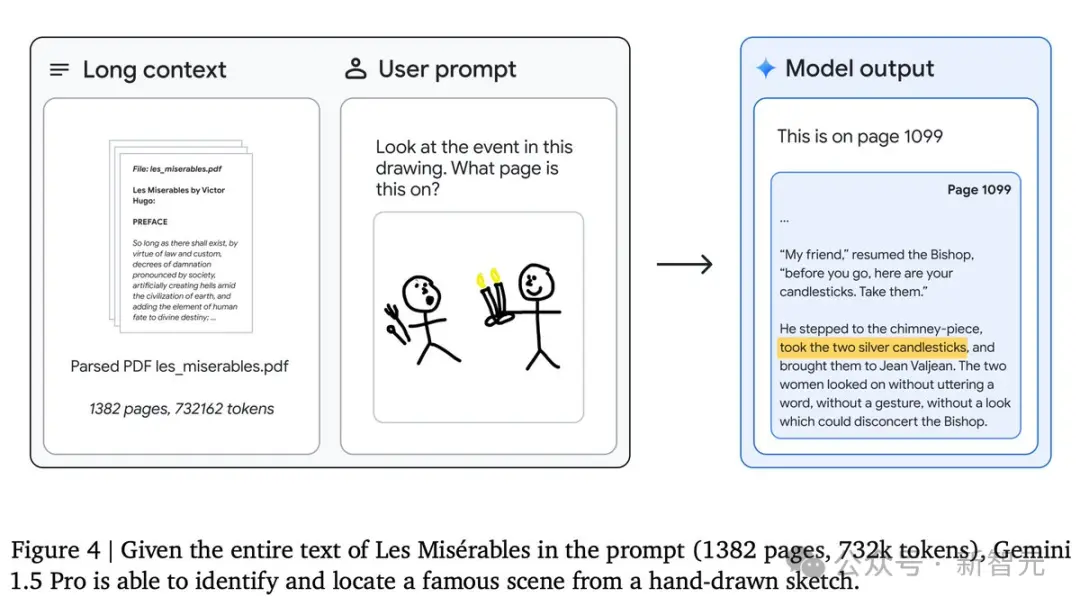
长篇复杂文档的推理
同时,模型在分析长篇、复杂的文本文档方面也非常出色,例如雨果的五卷本小说《悲惨世界》(共1382页,含732,000个token)。
下面这个简单的实验,就展示了模型的多模态能力:粗略地画出一个场景,并询问「请看这幅图画中的事件发生在书的哪一页?」
模型就能给出准确的答案——1099页!
Prev Chapter:与微软竞争 苹果开发AI工具帮助开发人员编写App代码
Next Chapter:OpenAI今天刷屏的视频模型,是如何做到这么强的?
评论区
- 这篇文章还没有收到评论,赶紧来抢沙发吧~
【随机内容】

