

让大模型“瘦身”90%!清华&哈工大提出极限压缩方案:1bit量化,能力同时保留83%_tiknovel-最新最全的nft,web3,AI技术资讯技术社区
让大模型“瘦身”90%!清华&哈工大提出极限压缩方案:1bit量化,能力同时保留83%
对大模型进行量化、剪枝等压缩操作,是部署时最常见不过的一环了。
不过,这个极限究竟有多大?
清华大学和哈工大的一项联合研究给出的答案是:
90%。
他们提出了大模型1bit极限压缩框架OneBit,首次实现大模型权重压缩超越90%并保留大部分(83%)能力。
可以说,玩儿的就是“既要也要”~

一起来看看。
大模型1bit量化方法来了
从剪枝、量化,到知识蒸馏、权重低秩分解,大模型已经可以实现压缩四分之一权重而几乎无损。
权重量化通常是指把大模型的参数转化为低位宽的表示,可以通过对充分训练后的模型进行转换(PTQ)或在训练中引入量化步骤(QAT)来实现。
然而,现有量化方法在低于3bit时面临严重的性能损失,这主要是由于:
现有的参数低位宽表示方法在1bit时存在严重的精度损失。基于Round-To-Nearest方法的参数以1bit表示时,其转换的缩放系数s和零点z会失去实际意义。
现有的1bit模型结构没有充分考虑到浮点精度的重要性。浮点参数的缺失可能影响模型计算过程的稳定性,严重降低其本身的学习能力。
为了克服1bit超低位宽量化的阻碍,作者提出一种全新的1bit模型框架:OneBit,它包括全新的1bit线性层结构、基于SVID的参数初始化方法和基于量化感知知识蒸馏的深度迁移学习。
这种新的1bit模型量化方法能够以极大的压缩幅度、超低的空间占用和有限的计算成本,保留原模型绝大部分的能力。这对于实现大模型在PC端甚至智能手机上的部署意义非凡。
整体框架
OneBit框架总体上可以包括:全新设计的1bit模型结构、基于原模型初始化量化模型参数的方法以及基于知识蒸馏的深度能力迁移。
这种全新设计的1bit模型结构能够有效克服以往量化工作在1bit量化时严重的精度损失问题,并且在训练、迁移过程中表现出出色的稳定性。
量化模型的初始化方法能为知识蒸馏设置更好的起点,加速收敛的同时获得更加的能力迁移效果。
1、1bit模型结构
1bit要求每个权重值只能用1bit表示,所以最多只有两种可能的状态。
作者选用±1作为这两种状态,好处就是,它代表了数字系统中的两种符号、功能更加完备,同时可以通过Sign(·)函数方便地获得。
作者的1bit模型结构是通过把FP16模型的所有线性层(嵌入层和lm_head除外)替换为1bit线性层实现的。
这里的1bit线性层除通过Sign(·)函数获得的1bit权重之外,还包括另外两个关键组件—FP16精度的值向量。
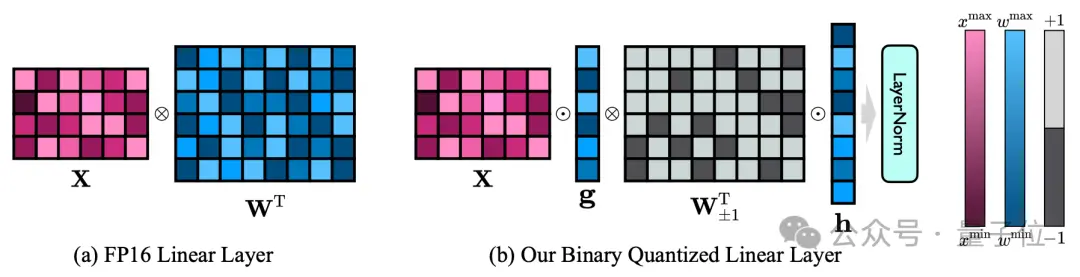
FP16线性层与OneBit线性层的对比
这种设计不仅保持了原始权重矩阵的高秩,而且通过值向量提供了必要的浮点精度,对保证稳定且高质量的学习过程很有意义。
从上图可以看出,只有值向量g和h保持FP16格式,而权重矩阵则全部由±1组成。
作者通过一个例子可以一观OneBit的压缩能力。
假设压缩一个40964096的FP16线性层,OneBit需要一个40964096的1bit矩阵和两个4096*1的FP16值向量。
这里面总的位数为16,908,288,总的参数个数为16,785,408,平均每个参数占用仅仅约1.0073 bit。
这样的压缩幅度是空前的,可以说是真正的1bit LLM。
2、参数初始化和迁移学习
为了利用充分训练好的原模型更好地初始化量化后的模型,作者提出一种新的参数矩阵分解方法,称为“值-符号独立的矩阵分解(SVID)”。
这一矩阵分解方法把符号和绝对值分开,并把绝对值进行秩-1近似,其逼近原矩阵参数的方式可以表示成:
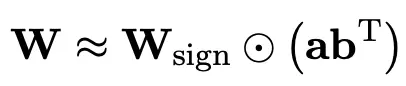
秩-1近似可以通过常用矩阵分解方法实现,例如奇异值分解(SVD)和非负矩阵分解(NMF)。
作者在数学上给出,这种SVID方法可以通过交换运算次序来和1bit模型框架相匹配,进而实现参数初始化。
此外,符号矩阵在分解过程中对近似原矩阵的贡献也被证明,详情见论文。
作者认为,解决大模型超低位宽量化的有效途径可能是量化感知训练QAT。
因此,在SVID给出量化模型的参数起点后,作者把原模型作为教师模型并通过知识蒸馏从中学习。
具体而言,学生模型主要接受教师模型的logits和hidden state的指导。
训练时,值向量和参数矩阵的值会被更新,而在部署时,则可以直接使用量化后的1bit参数矩阵进行计算。
模型越大,效果越好
作者选择的基线是FP16 Transformer、GPTQ、LLM-QAT和OmniQuant。
后三个都属于量化领域中经典的强基线,特别是OmniQuant是自作者之前最强的2bit量化方法。
由于目前还没有1bit权重量化的研究,作者只对OneBit框架使用1bit权重量化,而对其他方法采取2bit量化设置。
对于蒸馏数据,作者仿照LLM-QAT利用教师模型自采样的方式产生数据。
作者从1.3B到13B不同大小、OPT和LLaMA-1/2不同系列的模型来证明OneBit的有效性。在评价指标上,使用验证集的困惑度和常识推理的Zero-shot准确度。详情见论文。
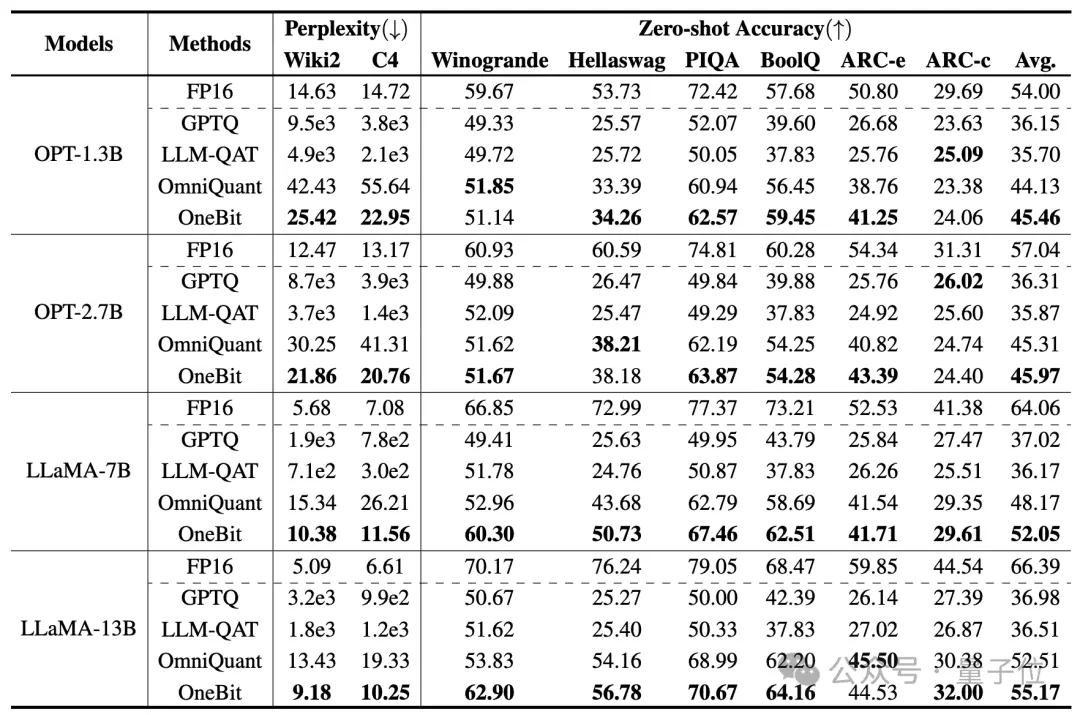
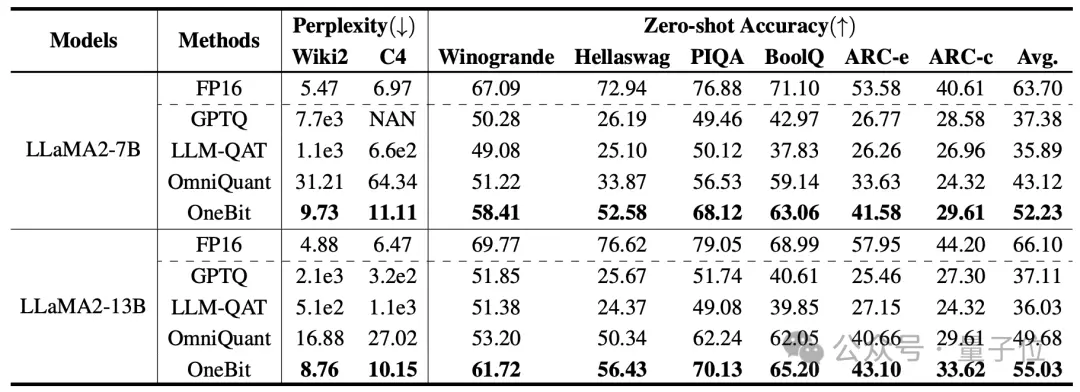
上表展示了OneBit相比于其他方法在1bit量化时的优势。值得注意的是,模型越大时,OneBit效果往往越好。
随着模型规模增大,OneBit量化模型降低的困惑度比FP16模型降低的困惑度要多。
以下是几种不同小模型的常识推理、世界知识和空间占用情况:
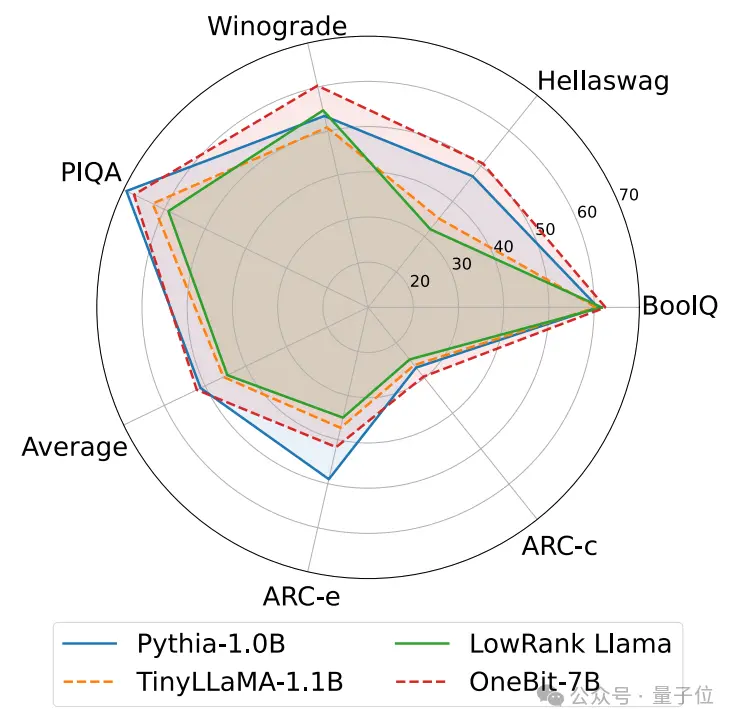
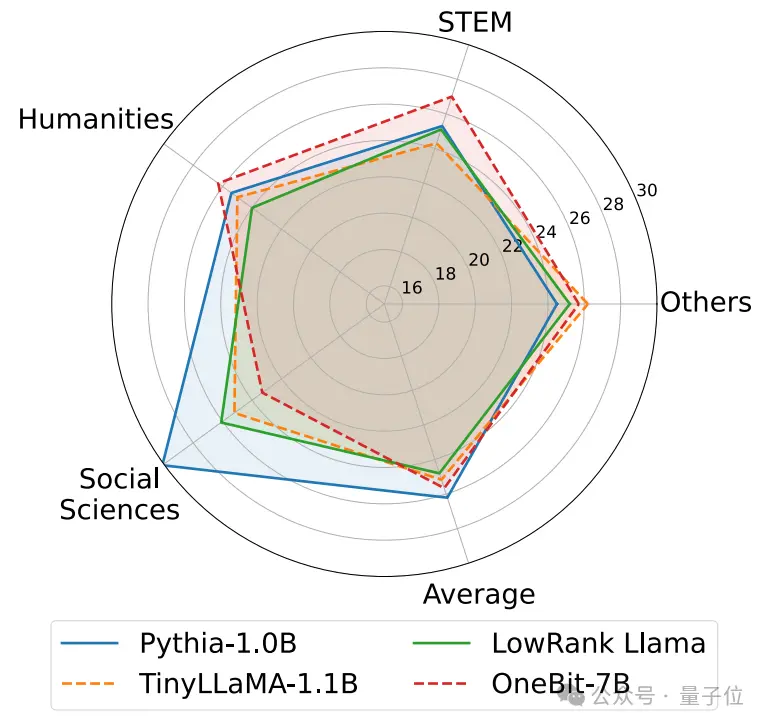
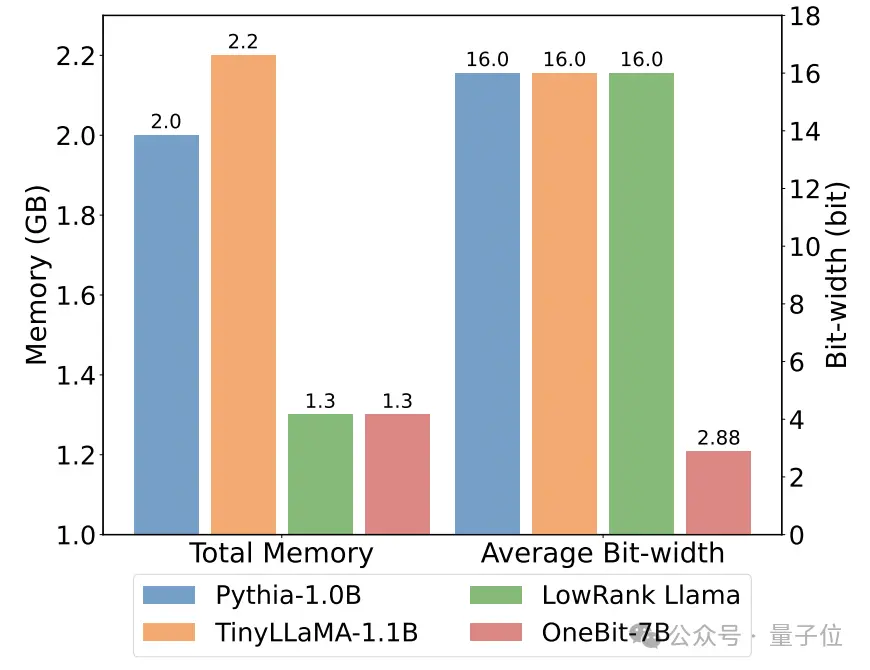
作者还比较了几种不同类型小模型的大小和实际能力。
作者发现,尽管OneBit-7B平均位宽最小、占用的空间最小、训练的步数也相对少,但它在常识推理能力上不逊于其他模型。
同时作者也发现,OneBit-7B模型在社会科学领域出现较严重的知识遗忘。

FP16线性层与OneBit线性层的对比一个OneBit-7B指令微调后的文本生成例子
上图还展示了一个OneBit-7B指令微调后的文本生成例子。可见,OneBit-7B有效地受到了SFT阶段的能力增益,可以比较流畅地生成文本,尽管总参数只有1.3GB(与FP16的0.6B模型相当)。总的来说,OneBit-7B展示出了其实际应用价值。
分析与讨论
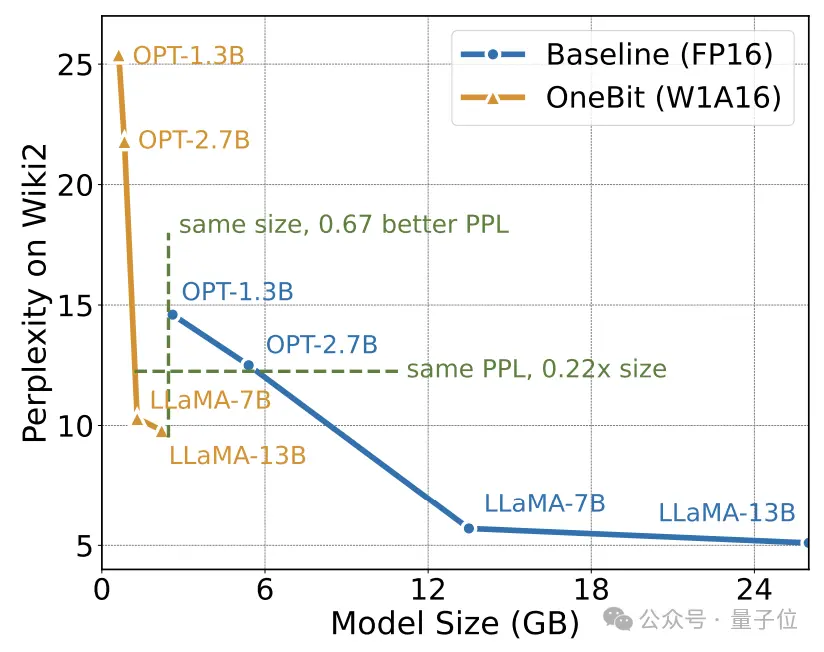
作者展示了OneBit对不同规模LLaMA模型的压缩比,可以看出,OneBit对模型的压缩比均超过惊人的90%。
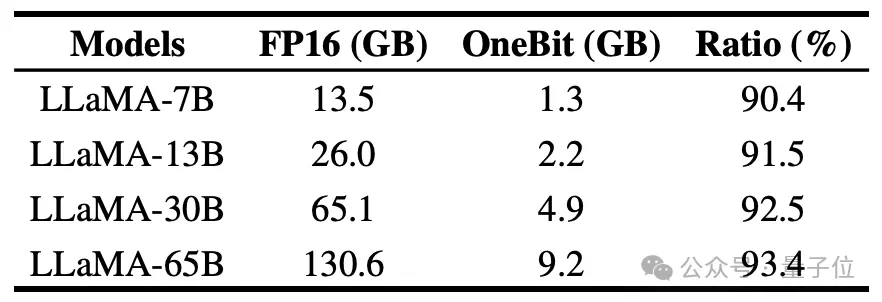
特别是,随着模型增大,OneBit的压缩比越高。
这显示出作者方法在更大模型上的优势:以更高的压缩比获得更大的边际收益(困惑度)。此外,作者的方法在大小和性能之间做到了很好的权衡。
1bit量化模型在计算上具有优势,意义十分重大。参数的纯二进制表示,不但可以节省大量的空间,还能降低矩阵乘法对硬件的要求。
高精度模型中矩阵乘法的元素相乘可以被变成高效的位运算,只需位赋值和加法就可以完成矩阵乘积,非常有应用前景。
此外,作者的方法在训练过程中保持了出色的稳定学习能力。
事实上,二值网络训练的不稳定问题、对超参数的敏感性和收敛困难一直受到研究人员关注。
作者分析了高精度值向量在促进模型稳定收敛过程中的重要意义。
有前人工作提出过1bit模型架构并用于从头训练模型(如BitNet[1]),但它对超参数敏感并且难以从充分训练的高精度模型中迁移学习。作者也尝试了BitNet在知识蒸馏中的表现,发现其训练还不够稳定。
总结
作者提出了一种用于1bit权重量化的模型结构和相应的参数初始化方法。
在各种大小和系列的模型上进行的广泛实验表明,OneBit在代表性的强基线上具有明显的优势,并实现了模型大小与性能之间的良好折中。
此外,作者进一步分析了这种极低比特量化模型的能力和前景,并为未来的研究提供了指导。
Prev Chapter:Inflection-2.5模型公布,全面提升聊天机器人Pi智商、情商
Next Chapter:曝GPT-4高居“抄袭”榜首!四大模型横评,GPT-4原文复制最严重
评论区
- 这篇文章还没有收到评论,赶紧来抢沙发吧~
【随机内容】

