

谷歌推出“社会学习”AI框架,可让模型互相教学_tiknovel-最新最全的nft,web3,AI技术资讯技术社区
谷歌推出“社会学习”AI框架,可让模型互相教学
日前,谷歌方面公布了一项名为“社会学习”(Social Learning)全新AI框架。据了解,该框架允许大模型通过自然语言互相学习,并号称由于学习过程中不涉及敏感关键信息的直接交换,因此该框架训练出的大模型更具隐私保护性。
对此谷歌方面表示,“大模型显著提高了使用自然语言解决指定任务的技术水平,通常达到接近人类的性能。随着这些模型越来越多地支持辅助代理(assistive agents),他们可以有效地相互学习,就像人们在社交环境中所做的那样”。
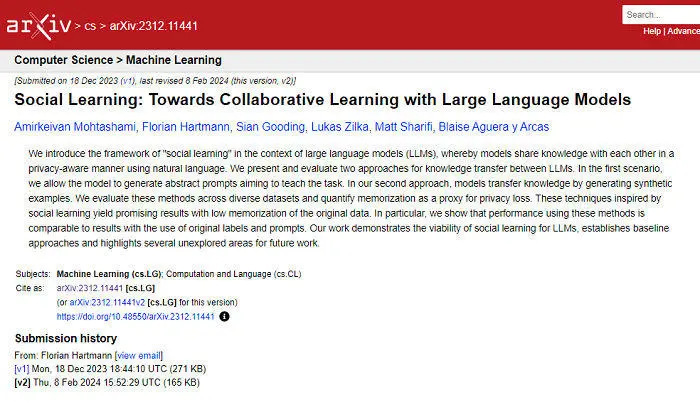
具体而言,在“社会学习”框架中,“学生模型”会向多个已知特定任务解法的“教师模型”学习各种问题的解决方案。目前,谷歌研究人员已设计了“垃圾信息检测”、“解决小学数学问题”、“根据特定文字回答问题”等多项测试,来评估“社会学习”框架的成效。
据谷歌方面相关研究人员透露,部分大模型只经过短暂的“社会学习”框架训练,便能够能获得良好的任务解决能力。例如在“垃圾消息检测任务”中,“教师模型”会先从用户所标记的数据中学习,然后指导“学生模型”如何区分垃圾和非垃圾信息。这种学习方法不仅提高了大模型的识别准确率,还避免了对敏感数据的直接使用,降低了个人隐私泄露的风险。
为进一步强化隐私保护,相关“教师模型”可以依据实际数据集,合成出新的范例与“学生模型”共享。据称合成数据集与原始数据完全不同,因此能在保证起到相同教育作用的同时,降低原始数据中隐私内容泄露的可能性。
此外值得一提的是,谷歌研究人员还尝试了合成指令的方式,即让“教师模型”针对特定任务生成一系列指令,然后“学生模型”依据这些指令学习如何执行任务。这种方法类似于人类按照他人的口头指令去做事,并在实际操作中学会如何完成工作。据研究人员表示,实验证明“教师模型”生成的指令能够提高“学生模型”执行任务的效率,并且他们认为,相比于零样本学习,这显示出大模型在遵循指令方面的强大能力。
Prev Chapter:消息称苹果已发起对华为“Vision Pro”商标无效宣告申请
Next Chapter:GPT-4.5疑似面世,OpenAI官网网页被索引,最快3月14日发布?
评论区
- 这篇文章还没有收到评论,赶紧来抢沙发吧~
【随机内容】

