

Sora团队罕见专访:短期内不会向公众开放,目前还不是一个产品_tiknovel-最新最全的nft,web3,AI技术资讯技术社区
Sora团队罕见专访:短期内不会向公众开放,目前还不是一个产品
最近,Sora 团队三位负责人露面,接受了科技博主 @MKBHD 约 16 分钟的专访。
整个视频掐头去尾,再除去想词和提问的时间,透露的信息并不多,还回避了训练数据之类的敏感问题。
或许因为没有采访经验,他们盯着镜头,坐姿有些拘束,YouTube 网友评价:OpenAI 的采访给人的感觉,就像旁边有个拿着枪的律师。

采访得到最为明确的信息是,Sora 短期内不会向公众开放。
另外,他们也谈到了 Sora 的原理、优缺点、发展路线、安全问题,以及对创造力的影响。
但无论如何,这都是在外界众说纷纭和等待 Sora 之时,OpenAI 公开表达态度的一次采访,值得一看。
Q:科技博主@MKBHD
A:三位 OpenAI 团队成员
Bill Peebles,OpenAI 研究科学家,Sora 负责人。
Tim Brooks,OpenAI 研究科学家,Sora 负责人。
Aditya Ramesh,OpenAI 图像生成模型 DALL·E 开发者,Sora 负责人。
Q:简单地解释一下 Sora 的工作原理?
A:总的来说,Sora 是一个生成模型。
这几年面世的生成模型很多,包括 GPT 等语言模型,DALL·E 等图像生成模型,而 Sora 是视频生成模型,通过大量的视频数据,学习生成逼真的现实世界和数字世界视频。
Sora 的工作方式,借鉴了类似 DALL·E 的基于扩散的模型,以及类似 GPT 系列的大语言模型,但介于两者之间,像 DALL·E 那样被训练,在架构上更像 GPT 系列。
Q:Sora 是基于什么训练的?
A:这个我们不能透露太多,只能说基于公开可用的数据以及 OpenAI 已经获得许可的数据。
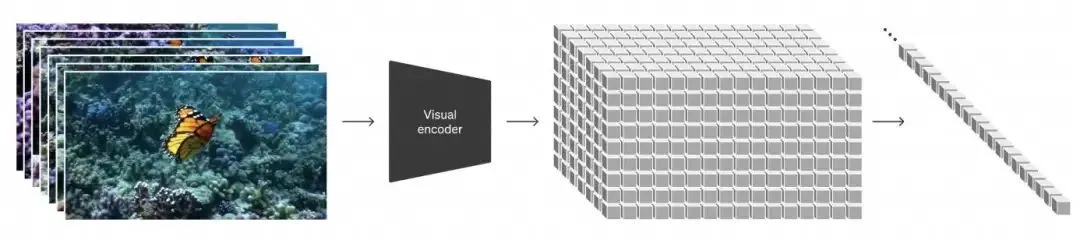
Sora 在训练方面有一项创新,能在不同时长、宽高比、分辨率的视频上训练。以前训练图像或视频生成模型时,素材的尺寸通常是非常固定的,例如只有一个分辨率。
但我们将所有宽高比、时间长短、高分辨率、低分辨率的图像和视频,全部变成叫作补丁(patch)的小块,然后根据输入的大小,在不同数量补丁(patch)的视频上训练模型。
这样一来,我们的模型非常灵活,既能在更广泛的数据上训练,也能用于生成不同分辨率和大小的内容。

Sora 可以采样 1920x1080、1080x1920 以及介于两者之间的所有视频.
Q:现阶段的 Sora 在创作方面的优点和缺点是什么?
A:Sora 的逼真度,以及 1 分钟的时长,都是巨大的进步,但也有些地方还不够好。
一般来说,手还是一个痛点。

Sora 可能生成六个手指.
另外还有一些物理方面的问题,比如 3D 打印机的例子。

Sora 没理解 3D 打印机,也没理解延时摄影.
如果要求提得更加具体,像是随时间变化的运动和摄像机轨迹,对 Sora 来说也有困难。
(编者注:采访者 @MKBHD 也在 X 分享了他的观点。
1.Sora 往往无法处理好步行等动作,双腿经常交叉并相互融合。
2.Sora 生成的商品与现实生活不完全相符,汽车、相机等无法识别为特定型号。
3.Sora 的灯光和阴影效果有时候很自然。
4.Sora可以很写实,体现光线和反射,甚至特写和纹理,也可以要求 Sora 生成具体的拍摄风格,比如 35 毫米胶片,或者背景模糊的数码单反相机,体现对焦的效果。)
Q:但是这些视频都没有声音,加入声音很难吗,你们计划什么时候在 AI 生成的视频里加入 AI 生成的声音?
A:很难给出一个确切的时间,初代的 Sora 就是一个视频生成模型,我们的重心在于改进视频生成的能力。
在 Sora 之前,很多 AI 生成的视频,只有 4 秒钟,帧率很低,质量不是很好,目前来讲,视频生成仍然是我们努力的主要方向。
当然,加入其他类型的内容会使视频更加沉浸,这也是我们正在考虑的事情。
有人用 ElevenLabs 等音频工具和剪辑工具,让 Sora 视频更有电影感.
Q:你们怎么判断 Sora 到达一个临界点,你们能够掌控它,知道怎么改进它,也准备好把它分享出来?
A:Sora 还没有准备好。
我们以博客文章形式发布 Sora(并提供部分访问权限),就是为了获得反馈,了解它对人类有什么用,还需要做哪些工作保证安全,我们也在听取艺术家的意见,看 Sora 怎么在工作流发光发热,从而指引我们的研究路线。
但 Sora 目前不是一个产品,在 ChatGPT 或者其他地方都不可用,我们甚至还没有将其转化为产品的时间表,现在就是一个获取反馈的阶段。
我们肯定会改进它,但应该如何改进它,还是一个等待解答的、开放的问题。
Q:目前你们听到了什么有趣的反馈?
A:我们收到了一个重要的反馈,人们希望能更细节地控制 Sora,不想只是借助一个较短的提示词,而是更好地控制生成的内容,这很有趣,也会是我们研究的一个方向。
Q:未来有没有这样的可能,Sora 生成一个与普通视频无法区分的视频,就像 DALL·E 制作逼真的图片?
A:这确实是可能的,当然,当我们快要接近时,必须小心谨慎,确保相关的功能不被用来传播虚假信息。
现在人们刷社交媒体时,已经在担心看到的视频是真的还是假的,是否来自权威的信源。

Q:Sora 生成的视频在底部角落有一个水印,但这样的水印可以被裁掉,你们是否考虑了其他方法,简单地识别 AI 生成的视频?
A:是的,对于 DALL·E 3,我们训练了可以识别图像是否由模型生成的溯源分类器(provenance classifier),我们也将让这项技术适用于 Sora 生成的视频。不过,这还不是一个全面的解决方案,只是第一步而已。
(编者注:DALL·E 3 官网显示,「溯源分类器」还在内测,OpenAI 称,如果图片从未修改,判断是否由 DALL·E 生成的准确率超过 99%,如果经过裁剪、压缩、叠加文本或图像等修改,准确率仍在 95% 以上。)
Q:这是否有点像元数据或者嵌入式的标志?
A:C2PA(Adobe、微软等发起的技术协议,在媒体文件中嵌入元数据,验证其来源和修改历史)是这样的。但我们训练的分类器可以在任何图像或视频上运行,并判断某个内容是否由我们的模型之一生成。
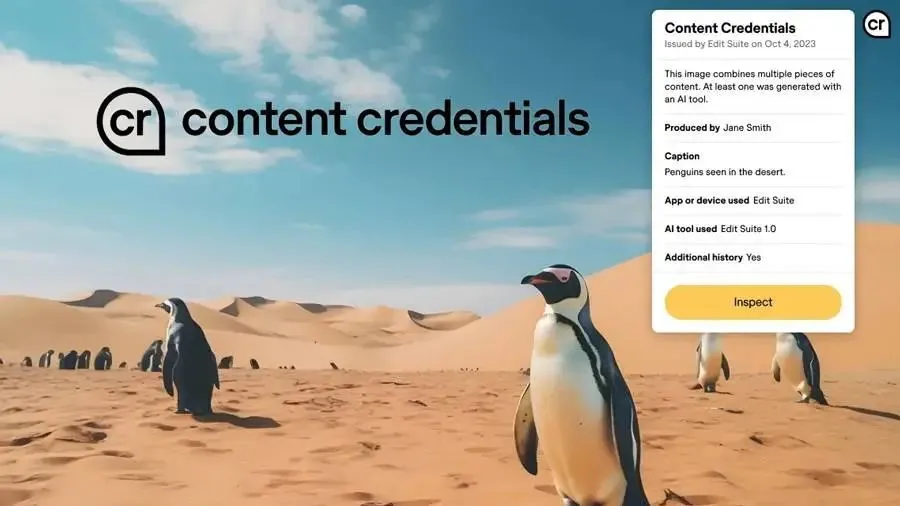
C2PA 的图标「CR」,鼠标悬停时会出现详细信息.
Q:Sora 官宣后,有人说这太酷了、太神奇了,也有人觉得害怕,工作岌岌可危了。对于大众的这些反应,你们又有什么反应?
A:焦虑肯定是存在的。
关于接下来会发生什么,我们的使命是确保这项技术安全地部署,并负起相关的责任。
同时,也有很多新的机会。例如,如果一个人有制作电影的想法,但拿到投资真正地制作电影很难,因为制作公司必须衡量预算和风险,而 AI 可以极大地降低从产生创意到完成视频的成本,这就很酷。
Q:我现在用 DALL·E 头脑风暴、制作视频缩略图,Sora 应该也有许多类似的工具化用途。但 Sora 还处于测试阶段,它会不会尽快向公众开放?
A:不会很快。

Sora 提示词:一只中等体型、看起来很友好的狗走过工业停车场。环境多雾、多云。采用 35mm 胶片拍摄,色彩鲜艳.
Q:相比照片,视频有时间、物理、反射、声音等更多的维度和变量。在更远的未来,当 Sora 制作出有声音的、完美写实的五分钟 YouTube 视频时,AI 生成媒体的下一个发展方向会是什么?
A:其实更让我们兴奋的是,AI 工具的使用,如何促进创造全新的内容。
我们往往很容易想象,AI 工具如何被用来创造现有的东西,但当新工具到最有创意的人手中,我们才能知道他们如何使用工具,创造的事物会是什么样子,或许是当前不可能的、想象不到的、全新的体验。
通过制作新的工具,让真正有创造力的人推动创意的边界,是非常激动人心的,也是我们一直以来的动力。
Q:让 Sora 更有创造力的方式,是通过更好的提示词吗?
A:Sora 还有其他特别酷的提示方式,而不仅仅是基于文本的提示。
我们发布的 Sora 技术报告中有一个示例,展示了两个输入视频如何融合,左边的视频是无人机穿过斗兽场,右边的视频是蝴蝶在水下的珊瑚礁游泳,而融合的视频是,其中的一个过渡时刻,斗兽场开始腐烂,部分埋入水下被珊瑚礁覆盖,无人机变成了蝴蝶。
这种生成视频,与使用旧技术制作的内容相比,确实给人眼前一亮的感觉。
所以,我们对于创作这类事物的兴奋超出了提示词的范畴,人们可以用像 Sora 这样的技术生成新的体验。
某种程度上可以说,我们将「建模现实」视为「超越现实」的第一步。

Q:这很有趣,Sora 模拟现实的能力越强,我们也能够更快地在其基础上构建,将它作为一个工具,解锁新的创造可能。关于 Sora 和 OpenAI,你们还有什么想分享的吗?
A:让我们兴奋的另一件事是,如何让 AI 从视频数据中学习,发挥更多的作用,而不仅仅是创作视频。
在我们生活的世界,观察事物就像观看视频,很多信息不能用文本表达,虽然像 GPT 这样的模型非常聪明,对世界已经了解很多,但如果它们无法像我们一样以视觉方式看待世界,就会缺失一些信息。
所以我们希望 Sora 和未来在 Sora 基础上构建的其他 AI 模型,从关于世界的视觉数据中学习,更好地理解我们生活的世界和其中的事物,然后更好地帮助人类。
Prev Chapter:GPT-4.5疑似面世,OpenAI官网网页被索引,最快3月14日发布?
Next Chapter:中国大厂押注AI这么久,为何还不跟进Sora?
评论区
- 这篇文章还没有收到评论,赶紧来抢沙发吧~
【随机内容】

