

史上最强AI芯片面世:干翻英伟达_tiknovel-最新最全的nft,web3,AI技术资讯技术社区
史上最强AI芯片面世:干翻英伟达
AI大模型飞临,英伟达趁机火了一把,但世界没有永远的王位,英伟达GPU跌下神坛终有时。昨日,就有一个挑战者逆势而上。
3月14日,OpenAI创始人山姆·奥尔特曼曾投资的美国初创公司Cerebras Systems发布了他们的第三代晶圆级AI加速芯片“WSE-3”(Wafer Scale Engine 3),这款芯片的单颗面积达到了约46225平方毫米,是通常芯片面积的50倍以上,比一本书的面积还要大。
别看它大,但在功耗、价格不变的前提下性能却是翻了一番。在这个“超大号”芯片面前,英伟达的GPU简直弱爆了。
性能是H100的8倍
这种巨大的芯片被称为晶圆级芯片(Wafer Scale),简单解释就是在一片晶圆上能切多大芯片,就造多大芯片。
随着新一代芯片增加晶体管密度变得越来越困难,芯片制造商正在寻找其他方法来提高处理器的性能,造大就是一条可行之路。
这家专造大芯片的公司Cerebras Systems已经坚持造出两代产品,此次产品是第三代产品。此前,EEWorld历史文章《“最大”的芯片,都长什么样?》中也有提到该公司。
2019年的第一代WSE-1基于台积电16nm工艺,面积46225平方毫米,晶体管1.2万亿个,拥有40万个AI核心、18GB SRAM缓存,支持9PB/s内存带宽、100Pb/s互连带宽,功耗高达15千瓦。

2021年的第二代WSE-2升级台积电7nm工艺,面积不变还是46225平方毫米,晶体管增至2.6万亿个,核心数增至85万个,缓存扩至40GB,内存带宽20PB/s,互连带宽220Pb/s。其核心面积就已经达到了46225平方毫米,是彼时最大的GPU核心面积的56倍。2022年,Cerebras Systems生产的芯片被硅谷计算机历史博物馆收藏。

如今的第三代WSE-3再次升级为台积电5nm工艺,晶体管数量继续增加达到惊人的4万亿个,而相比之下,英伟达H100芯片所包含的晶体管数量只有800亿个。AI核心数量进一步增加到90万个,缓存容量达到44GB,外部搭配内存容量可选1.5TB、12TB、1200TB。
乍一看,核心数量、缓存容量增加的不多,但性能实现了飞跃,峰值AI算力高达125PFlops,也就是每秒12.5亿亿次浮点计算,堪比顶级超算。

它可以训练相当于GPT-4、Gemini十几倍的下一代AI大模型,能在单一逻辑内存空间内存储24万亿参数,无需分区或者重构。
尽管WSE-3芯片核心数量、缓存容量增加的不多,但性能实现了飞跃,峰值AI算力高达125PFlops,也就是每秒12.5亿亿次浮点计算,堪比顶级超算。用它来训练1万亿参数大模型的速度,相当于用GPU训练10亿参数。四颗并联,它能在一天之内完成700亿参数的调教,而且支持最多2048路互连,一天就可以完成Llama 700亿参数的训练。
值得一提的是,Cerebras Systems放出了与英伟达H100性能参数的详细对比,公司介绍页信息显示,在人工智能训练加速方面,该芯片的性能是H100的8倍。
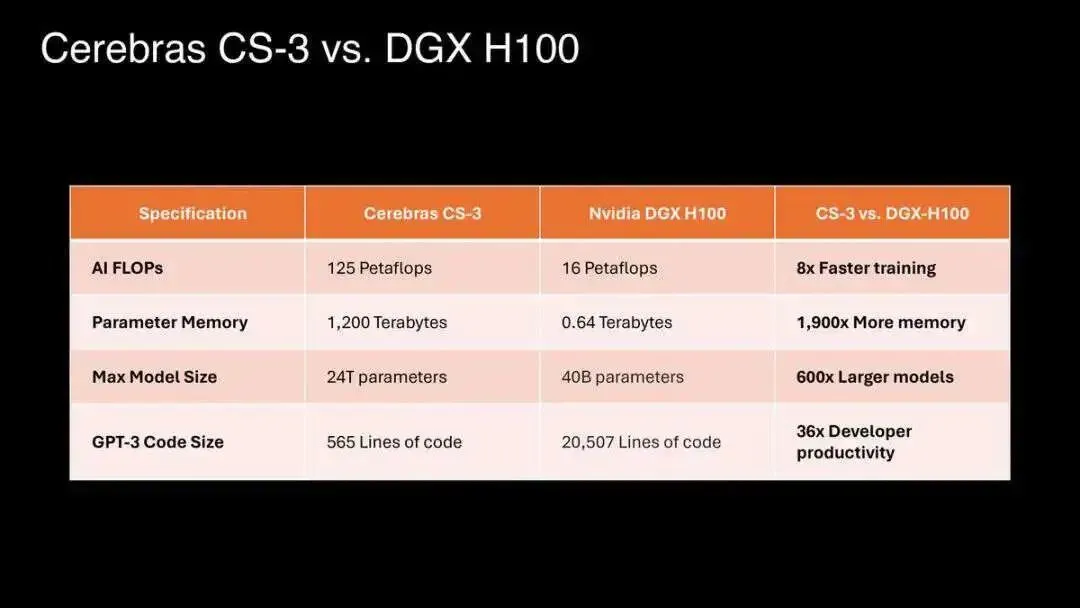
不止如此,该公司表示,Cerebras平台比NVIDIA的平台更易于使用。原因在于Cerebras存储权重和激活的方式,并且不必扩展到系统中的多个 GPU,然后扩展到集群中多个 GPU 服务器。
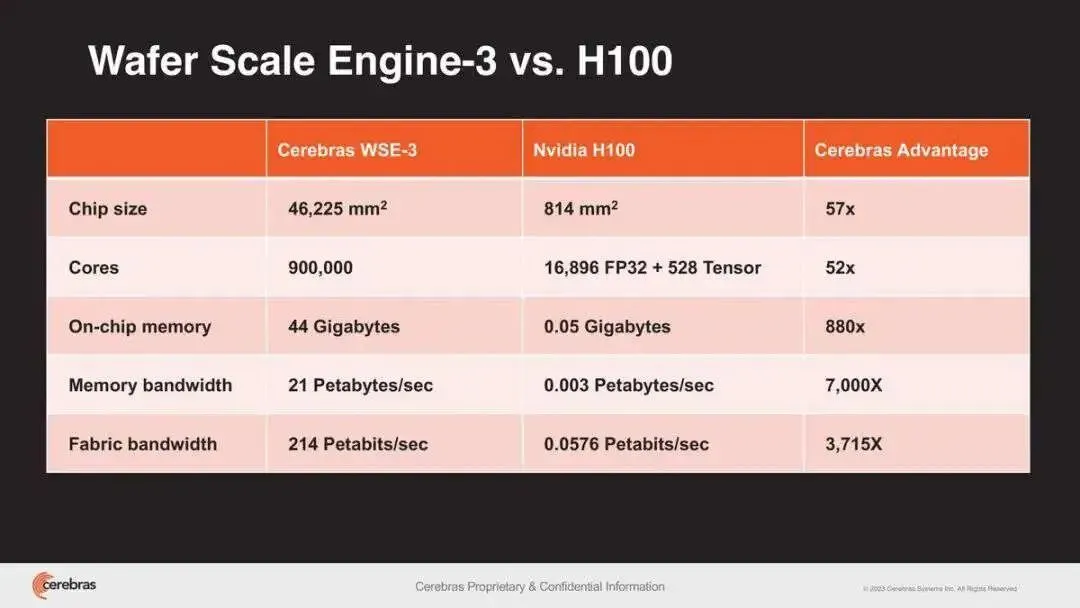
WSE-3的具体功耗、价格暂未公布,根据上代情况来看,应该在200多万美元。
阿联酋 G42 财团已表示将打造基于 Cerebras CS-3 的 Condor Galaxy 3 超算,包含 64 个系统,可提供 8 exaFLOP 的 AI 算力。
公开信息显示,Cerebras Systems是一家美国AI芯片独角兽公司,公司成立于2016年,主要致力改变芯片计算核心架构,提升芯片集成度,简化集群连接等相关领域的研究以及深度学习的芯片产品的研发。Cerebras Systems的最新一笔融资发生在2021年,由Alphawave Ventures和阿布扎比增长基金(ADG)领投,融资金额2.5亿美元。截至该轮融资,Cerebras融资总额7.2亿美元,公司估值超40亿美元。
同样值得关注的是,Cerebras Systems的投资团队可谓"大佬"云集,其中包括OpenAI创始人山姆·奥尔特曼(Sam Altman),AMD前CTO Fred Weber以及Benchmark、Coatue Management、Eclipse Ventures等多家明星投资机构。
“大芯片”,中国也在造
不光是国外,国内同样关注大芯片。
今年1月,中国科学院计算所科研团队开发了一种用于全新的计算处理器“大芯片”,相关论文被发表在《基础研究》杂志。
这是一款基于RISC-V架构的 256 核多芯片,并计划将该设计扩展到 1600 核,以创造整个晶圆大小的芯片,以作为一个计算设备,该芯片名为“浙江大芯片”。
据介绍,该芯片设计由 16 个小芯片组成,每个小芯片包含 16 个 RISC-V 内核,并使用片上网络以传统的对称多处理器 (SMP) 方式相互连接,以便小芯片可以共享内存。每个小芯片都有多个芯片到芯片接口,可通过 2.5D 中介层连接到相邻的小芯片,研究人员表示,该设计可扩展到 100 个小芯片,或 1600 个内核。
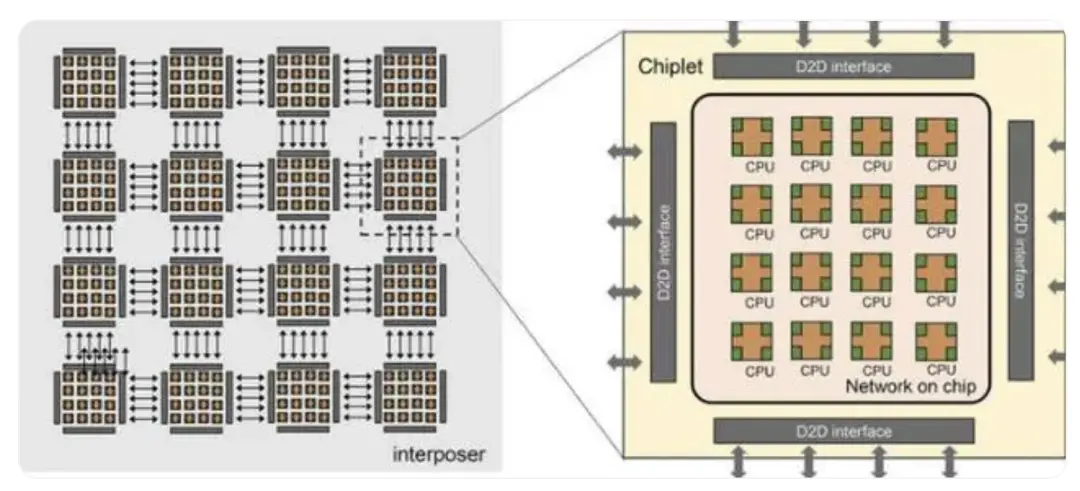
“浙江大芯片”基于Chiplet架构设计,采用 22 纳米级工艺技术制造,目前还不确定使用中介层互连并在 22 纳米生产节点上制造的 1,600 个核心组件会消耗多少功率。不过,由于延迟的减少,这将极大地优化其功耗和性能。
对于大芯片,研究团队提出了一系列愿景,例如光电计算、近内存计算以及3D堆栈式缓存和主内存,不过中科院并未明确指出他们正在研究的具体方向和交付的时间表。
Prev Chapter:开源版OpenAI机器人2.5万打造!斯坦福李飞飞团队祭出“灵巧手”,泡茶剪纸炫技
Next Chapter:电子书《Transformers 快速入门》
评论区
- 这篇文章还没有收到评论,赶紧来抢沙发吧~
【随机内容】

