

这几位前OpenAI员工,想打造“机器人界的ChatGPT”_tiknovel-最新最全的nft,web3,AI技术资讯技术社区
这几位前OpenAI员工,想打造“机器人界的ChatGPT”
能理解
才能想象
2021 年,因缺乏足够的训练数据,OpenAI 低调地终止了内部的机器人研究项目。
现在,我们却有机会看到 OpenAI 那未被实现的愿景。
2017 年,三位 OpenAI 早期研究成员创立了 Covariant,用直接投入行业去解决那个让 OpenAI 止步不前的数据难题 —— 没有数据,那就「创造」数据。

Covariant 的三位联合创始人都曾是 OpenAI 员工:Rocky Duan,CTO;Pieter Abbeel 总裁兼首席科学家;Peter Chen,CEO。
来到 2023 年,专注于打造软件平台的 Covariant 发布了机器人基础模型「RFM-1」。
在这个基础模型的支持上,人们印象冷冰冰的工厂机械臂,不仅能直接和用户对话,甚至还懂得「想象」与「求助」。
为何要让机械臂能「对话」,会「想象」?

我刚意识到我是这个台上唯一一个不是 CTO 的人。
在上周的英伟达 GTC 活动中,Covariant CEO Peter Chen 在其中一个论坛中说道。
从某个角度来看,这也正好体现了 Covariant 产品的一个重要差异性 —— 关于技术的对话,可以更友好。
一般来说,如果想让机械臂完成流水线上的某项工作,譬如说给机器拧上特定一颗螺丝,工程师必须为此进行专门的编程,让机械臂完成,且只能完成这项工作。
如果要换个任务,那又是另一番的编程工作。
就如 ChatGPT 打破了普通人和 AI 对话的门槛,Covariant 的 RFM-1 也打破了普通人和机械臂对话的障碍。
有了这个底层大模型,用户可以直接像和 ChatGPT 聊天一样和机械臂实时对话:
—— 框里有水果吗?
—— 有的。我看到了苹果和香蕉。
—— 拿起所有的红苹果。
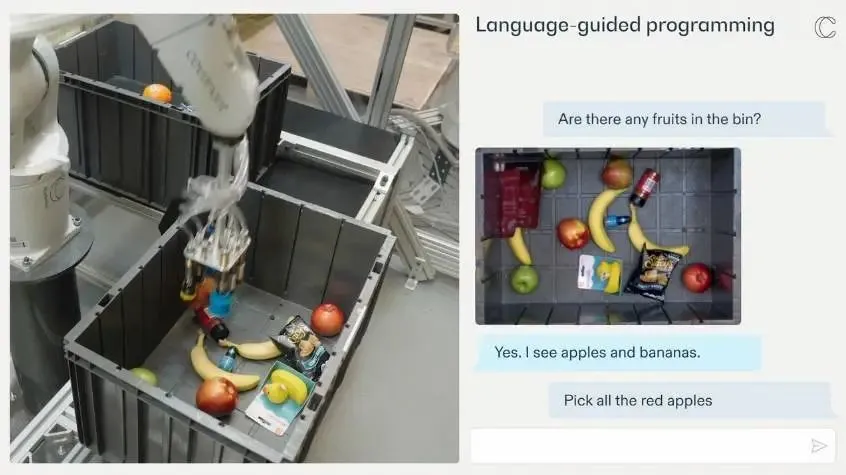
有了这样的灵活性,工厂、仓库里的机械臂能敏捷地适应不同需求。
让我印象更深刻的是,和聊天机器人爱「信口张来」的习惯相比,RFM-1 支持的机械臂在遇到难题时显得更谨慎,甚至会主动「求助」人类。
在演示视频中,机械臂在被要求拿起一筒筒的网球时遇到了困难:
—— 我没法抓住。
—— 你有什么建议吗?
—— 移到物件高处两厘米旁,轻轻地把它推倒。

来自机械臂的「求助」
试过这个建议后,机械臂能把学到的应用到下一个动作中。
从这些自然语言的交互也能看出,RFM-1 也和我们更熟悉的大语言模型一样,在训练时学习了大量的文本、图像、视频等素材。
在这基础上,让它真正区别于其他同类模型的,是大批量真实的机械臂操作视频。
还记得最开始说 OpenAI 是因为缺乏可用训练数据才放弃机器人项目的吗?
Covariant 也不是一开始就拥有了这样宝贵的数据,而是一步步自己「做」出来的。

当 Covariant 于 2017 年成立时,它就开始为真正的商户提供机械臂系统服务。
这些如今分布已遍布全球十多个国家的机械臂日复一日地工作,同时也在「生产」高质量的多模态视频数据。

在现实中,不同物品在容器中的堆叠方式都多种多样,这也只是现实情况多样性的一个小方面
和其他演示类视频数据相比,Covariant 机械臂的「打工视频」不仅涵盖了不同的「工种」,接触了多元商品,也记录了很多真实「意外」:可能是不小心卡在传送带上无止境翻滚的商品,也可能是商品外包装突然坏了。

现实工作中出现的「意外」也是重要学习素材
模型这样大量的数据基础让机械臂不仅可「理解」,甚至能「想象」。
用户可以让机械臂拿起特定物件,也可以让机械臂生成一个视频,以鸟瞰视角呈现它将如何拿起这样物件。

模型自己生成的「想象」
在这个生成的视频中,模型不仅生成了拿起的动作,同时也会生成物件被拿起后置物容器发生的改变。
虽然说这个功能暂时在仓库里无实际用途,但却可展示机械臂对人物和场景的理解:
如果它能预测到视频下一帧画面,那它就可以确定要遵循的正确策略。
Covariant 联合创始人兼首席科学家Pieter Abbeel 解释道。

最右边图片是模型生成的图像,预测拿起特定物品后框里情况是怎样
当然,现在的 RFM-1 仍存在局限性。「MIT Technology Review」记者在体验演示时就遇上了机械臂表现不佳的情况。
当时,记者通过对话框要求机械臂把香蕉放到二号托特包里,结果机械臂先是拿起了海绵、然后是个苹果,接着还试拿了其他一系列东西,最后才拿起来了香蕉放好,完成任务。
它没有理解那个新概念。但这也是一个很好的例子 —— 在训练数据还不是非常充分的领域,它的运行暂时未必很好。
Covariant CEO Peter Chen 在旁解释说。
接下来,RFM-1 当然会在更多的真实操作视频数据中继续优化,但在未来,Covariant 最终计划将模型自己生成的视频用作模型训练数据的一部分:
用(生成数据)它来训练将成为现实。如果我们在半年后再聊,那就会成为我们谈论的主题。
AI 时代的机器人,要换种方式学习

Covariant 那用模型生成视频来当训练素材的计划,虽然会引来一些质疑 —— 万一模型生成的数据本来就有错那怎么办?—— 但在大语言模型训练领域似乎已经成为一种新主张。
据《大西洋月刊》报道,在过去的几个月里,Google DeepMind、微软、亚马逊、苹果、OpenAI 和其他学术研究实验室都曾发表了用 AI 模型来训练另一个/同一个 AI 模型的论文,并表示模型获得了很大进步。
DeepMind 联合创始人 Demis Hassabis、Anthropic 联合创始人 Dario Amodei 和计算机专家 Yann LeCun 等人都支持这种自训练模式。
来到机器人领域,在「虚拟」中学习似乎也有可能成为新常态。
在上周的英伟达 GTC 主题演讲中,黄仁勋揭晓了英伟达为人形机器人打造的通用基础模型 GR00T,搭配的还有为人形机器人设计的新型计算平台 Jetson Thor。
有了这搭配的机器人,不仅能理解自然语言,还可以在 Isaac Sim 的模拟世界中进行不间断的学习 —— 不必受限于人力物力和空间限制。

据黄仁勋介绍,在舞台上吸睛无数的迪士尼机器人,就是在 Isaac Sim 中学会走路的。
在此前迪士尼发布的视频中,迪士尼研究实验室副总监 Moritz Bacher 表示,这些机器人在虚拟环境中学习不同动作和表达的效率非常高:
在几个小时内就能完成相当于在现实世界中要花费数年才能完成的学习。


长久以来,人形机器人发展一大瓶颈在于「学习」只能依赖「动作编排」。就和机械臂一样,人形机器人的动作学习也常「一板一眼」,用一套动作就得编一次。
有了「学习」能力时,学习用的数据局限又成了另一个门槛。随着模拟数据的完善,这个情况有机会大幅度改善。原本兼顾步行平衡和完成任务的艰难,在大量的训练中也更有可能获得突破。
有了这个可能性,人们自然把目标放在了「圣杯」一般的通用人形机器人。正如黄仁勋所言:
人形机器人可以更有效率地部署在人类设计的工作站、制造和物流环节中。

现在于机械臂领域有更大优势的 Covariant 的未来目标也充满野心:
我们相信,未来不会只有一种形态的机器人需求。
部分会是人形机器人形态,部分会是机械臂形态…… 但所有形态都需要理解同一个真实世界。
Covariant 建造的就是那个能驱动所有形态机器人的同一个大脑,能够去理解这个真实的世界。
正如纽约大学通用机器人和人工智能实验室负责人 Lerrel Pinto 所言:
那些能训练出好模型的团体,要不就是要有能力获得大量现存机器人数据,要不就得有能力去生成那些数据。
Prev Chapter:AI接连翻车的Google ,还能翻盘吗?
Next Chapter:开源电子书《动手实战人工智能 AI By Doing》
评论区
- 这篇文章还没有收到评论,赶紧来抢沙发吧~
【随机内容】

