

男朋友和ChatGPT的加密聊天,被我破解了_tiknovel-最新最全的nft,web3,AI技术资讯技术社区
男朋友和ChatGPT的加密聊天,被我破解了
随着AI技术大爆炸,各种与AI相关的产品也开始进入了我们的生活。
你可能用妙鸭相机的AI生图画过头像、用月之暗面的Kimi总结过论文,让ChatGPT写过应付领导的文件。
但是,这些朋友们得注意了,现在你们与AI的对话可能已经不再安全。

以色列本·古里安大学进攻性人工智能实验室的研究人员发现了一种攻击AI的方法,如果有心之人拿它入侵你的通信系统,那么你与AI的谈话内容,就会出现在别人的电脑屏幕上。你的隐私、他人的隐私、商业机密等都将暴露无遗。

正如有些国家的警方会根据住户不正常的用电量,去推测他是否在种植违禁药品,本·古里安大学的这种方法也不是直接破译密码,而是所谓的测信道攻击,也就是利用时间、电磁、声音、电源甚至风扇的转速这些,表面上看起来跟个人隐私毫无关系的信息,来推测敏感信息,非常的神奇。

以ChatGPT为代表的一众AI聊天助手面对这种进攻完全没有招架之力,只有一个例外,那就是谷歌的Gemini。
所以这种攻击AI的方法到底是怎么回事?为啥谷歌能独善其身呢?
且容我细细道来。
01
你发现你对象最近有些神神秘秘的,经常用ChatGPT,但不愿意给你看到底聊了什么。
莫非ta有什么不可告人的秘密?

你有没有办法可以获得ta的聊天记录呢?
是有的,而且只需要三步。

第一步,拦截数据。
从哪里拦截呢?
理论上来说,数据从ChatGPT的服务器中传输到电脑之间的任何节点都可以拦截,也就是途中经过的任何路由器。但最方便的截击点,显然是家里的路由器。
现在我们控制了路由器,任何一台家里设备上网的数据,你都一清二楚。

这就好像我想要知道你有多少快递,最好的办法就是盘下你家附近的快递网点。
你本就知道账号密码,所以很轻松地启动了家里路由器的管理权限,查看所有经过路由器的数据。
只要等ta跟ChatGPT聊天的时候截获数据就行。
你蹲守在厕所里启动电脑,经过短时间的等待,好的,ta开始跟ChatGPT聊天了。
但是这里遇到了一个问题,ChatGPT跟ta之间的通话是加密过的(废话)。
OpenAI对所有存储的数据用AES-256算法加密,对所有传输中的数据用TLS数据加密,介于你手头暂时没有量子计算机,根本破解不了啊!

那怎么办?
不要慌,有办法。
现在我们需要进入第二步。
第二步:虽然我们无法破解数据包的内容,但我们可以先把数据包的长度记下来。
数据包的长度跟我们想破解的信息有什么关系呢?
你也许听说过一个叫Token的概念。
类似ChatGPT这样的大语言模型的运行机制,本质上就是单词接龙。更准确地说,就是用它那几千亿的参数,去预测下一个最小的语义单元应该接什么,如此重复,从而接出一段完整的话。这个最小的语义单元,就是一个token。
比如:

或这样:
这些用色块隔出来的东西,就是一个一个的token。
可以发现,token跟单词基本上是一一对应的,这也就意味着:
token的长度与单词长度是基本一致的。
如此一来,只要依次记录下每个数据包的长度,我们就知道了ChatGPT发给ta的话,是由多长的词语依次组成的。
比如上面那句话,就是:2、2、1、1、1、5、2、4、4、1、3、8、4、5、1。
也就是说,我们知道了ta这句话的节奏。
是不是有点意思啦?

不是,你不要急嘛。
要把这个节奏跟具体的文本对应上,就必须进入第三步了。
第三步:用魔法打败魔法,用大语言模型去治大语言模型。
这群以色列的研究人员训练了一个大语言模型,专门根据一句话的节奏去预测这句话是啥。
长度序列(节奏)与具体的文本之间的能有什么关系呢?这对作为人类的你我来说可能有点难以想象。从一堆数据中找出规律正是AI所擅长的,研究人员就直接给大语言模型喂大量的长度序列,训练它们去预测对应的文字。再基于正确结果对于生成的答案进行排序,不断地卷,提升预测的准确度。
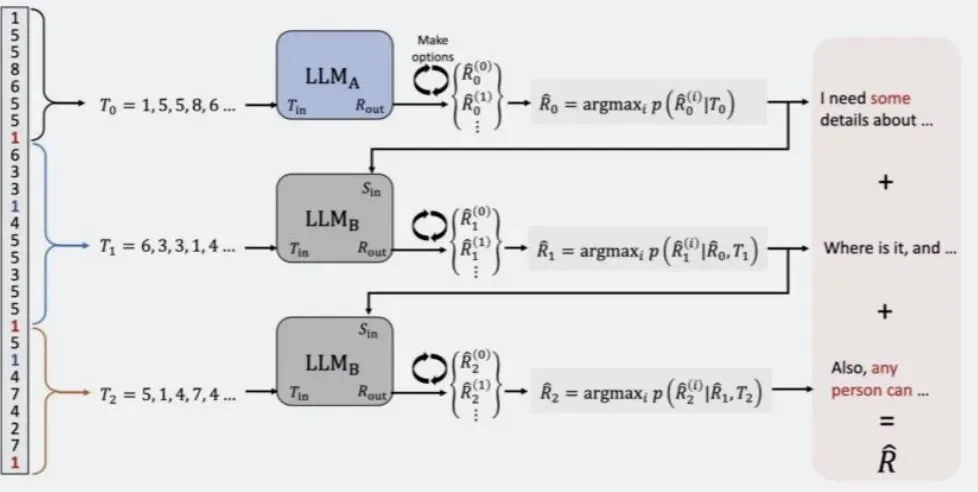
为了让预测的更准确,他们还做了进一步的fine-tuned。
由于AI生成的语句在第一句通常风格最明确,更容易预测。所以他们用一个大语言模型专门做第一句的预测,然后让再用另一个大语言模型根据第一句的结果预测后面的内容。
那么这样预测的结果如何呢?你能拿到朝思暮想的聊天记录吗?
02
在以色列研究人员的演示视频中,这两个大语言模型最终得到了50句不同的答案。
其中,通过侧信道攻击得到评分最高的答案是:Several recent advancements in machine learning and artificial intelligence that could be a game-changing tool.
翻译:一些机器学习和人工智能领域近期的研究成果,它们有可能是改变局势的工具。
而AI发来的原文本是:There are several recent developments in machine learning and artificial intelligence that could revolutionize the health industry.
翻译:这是一些机器学习和人工智能领域近期的研究成果,它们有可能改变整个健康产业。
这一说这个答案和原文本相当的吻合了。在关键信息上,侧信道攻击得到的句子包含了“机器学习和人工智能领域”,“研究成果”,唯独缺少了“健康产业”这一关键信息。
不过如果我们仔细看的话,那两个大语言模型给到的50个答案中有不少都提到了与“健康产业”接近的信息,比如排名第10的答案中提到了“healthcare institution”(医疗机构)和“hospital”(医院)。
总体来说,这种攻击方式有55%的情况下能达到高精确度(只有一两个词不同),29%的情况下能完美破解。
听起来好像不高啊,这不71%的情况都不能完美破解嘛?但在现实中,能完全破解当然好,但对发起进攻的人来说,他们需要的更多的是关键信息。
怎么理解呢?
假如,你对象跟ChatGPT探讨了半天两个人去成都有什么可玩的。而却从来没有告诉过你任何去成都的计划……
这TM就是关键信息了。
03
那么这种侧信道攻击有什么办法解决吗?
正如我们在开头所说,以ChatGPT为代表的绝大多数AI聊天助手都防不住这种攻击,只有Google的Gemini双子座可以。

为什么呢?
其实原因非常的扯淡。不是这个Gemini有什么特殊的架构或者特殊的加密算法,而是它回复用户的时候不像其他AI一样生成一个词就立马就发,而是等一段答案生成完了再发。
结果,攻击者截获到的token序列不再是1、2、5、6、1这种了,而是15。
这还怎么玩。
但是,从Gemini目前孤家寡人的境况你也能看出,这种方式是非常影响用户体验的。一个个往外蹦,我看到有不对的时候就马上开始准备新的问题了。而干等一分钟最后等来一个离谱的回答,容易导致高血压等心脑血管疾病的发生。

所以在即时发送的方式不变的情况下还有什么办法吗?
有一种“填充”的办法,向不同长度的数据包填充一些“空格”,使得发送的每个数据包长度相似。
但同样的,这也会影响用户体验,因为数据包中随即填充的这些“空格”,在打开数据包时也是需要时间去处理。所以延迟会比通常情况久不少。
以色列的这项研究发表后,在所有易受攻击的AI中,OpenAI在48小时内实施了“填充”措施,不过拒绝对其发表评论。微软则还没有采取措施,他们发表了一项声明,声明中称这种方式”不太可能预测像名字这样的具体细节”。
看来微软不是很在乎用户的隐私问题啊。

现实来讲,当一项技术处于爆发期的时候,忽略安全隐患是很多厂家的常规操作。因为很显然,安全是拦在效率前面的绊脚石,在AI界疯狂内卷的今天,把安全放在效率前面有时候是很难活下去的。
但安全问题可以被忽视,但并不会消失。当它再被提起时候,往往就是酿成大祸,舆论哗然的时候了。
不过除了具体的技术问题,我觉得侧信道攻击这件事背后的逻辑更有意思。
如果没有AI大模型,谁又能想到,原来只需要知道一句话的节奏,就能推断出这句话的内容呢??
这有点像一种名为海龟汤的游戏。在游戏中玩家只被根据非常有限的信息(汤面)去推测整个故事(汤底)。
比如给你一个汤面:“6岁时外婆告诉我不要吃黄苹果。13岁时,外婆告诉我不要吃青苹果。18岁时外婆告诉我不要吃红苹果。20岁时外婆去世了,我向外婆祈愿:以后所有的苹果都可以吃了。”
那么,外婆和苹果到底是有什么关系呢?

这个关系就类似于隐藏在表象下的规律,人类需要构建一整个故事去理解,因为人是线性思维,必须依赖因果关系去理解。而像数据包的长度和内容之间的规律,你是无法通过编故事去理解的。但这部分缺失的能力,现在AI替我们补上了。
Prev Chapter:OpenAI官方公布Sora第一波试用反馈
Next Chapter:超越GPT-4,Claude 3超大杯成新王
评论区
- 这篇文章还没有收到评论,赶紧来抢沙发吧~
【随机内容】

