

免费还能干翻GPT-4,Meta打了所有闭源大厂的脸_tiknovel-最新最全的nft,web3,AI技术资讯技术社区
免费还能干翻GPT-4,Meta打了所有闭源大厂的脸
不知道李彦宏现在心情如何。
就在他公开表示 “ 开源模型会越来越落后 ” 的 3 天后,活菩萨小扎慢悠悠地登场了。
丝毫不给面子,以一己之力掀翻了桌子。

就在今天凌晨, Meta 正式发布了全新的 Llama 3 模型,还一次上新了 8B 和 70B 两个参数版本。

它的训练数据集比 Llama 2 整整大了 7 倍,达到了 15T ,容量也是上一代的两倍,支持 8K 上下文长度。
目前,它们已经接入了 Meta 最新发布的智能助手 Meta AI 中, 所有人都可以免费使用。
这两个模型同样全面开源,开发者可以免费下载,并且用于商用。 ( 不过要注意的是,如果 MAU 超过 7 亿,你得申请特殊商业许可 )
小扎这 是誓死要在开源这条路上 , 一条道走到黑了。
当然更炸裂的是 Llama 3 的实力除了稳居开源大模型榜首外,甚至还能在一定程度上,薄纱 Gemini Pro 1.5 、 Claude 3 Sonnet 等处于第一梯队的闭源大模型。
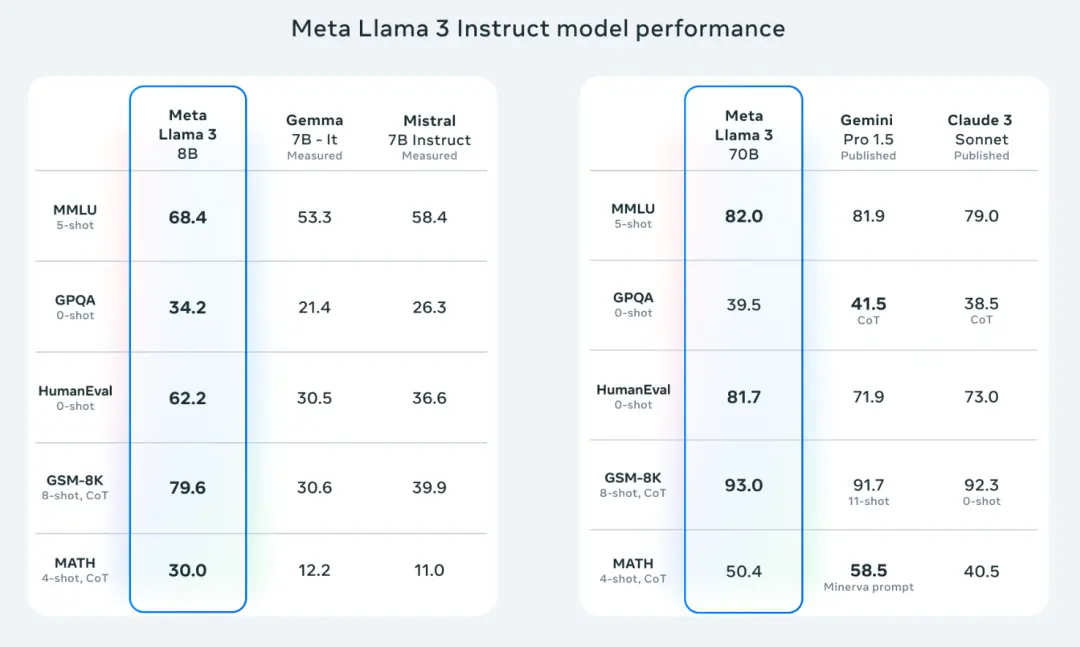

有网友更新了一份现有大模型的能力和参数对应表,能看到 Llama 3 的两个模型的表现都相当亮眼。
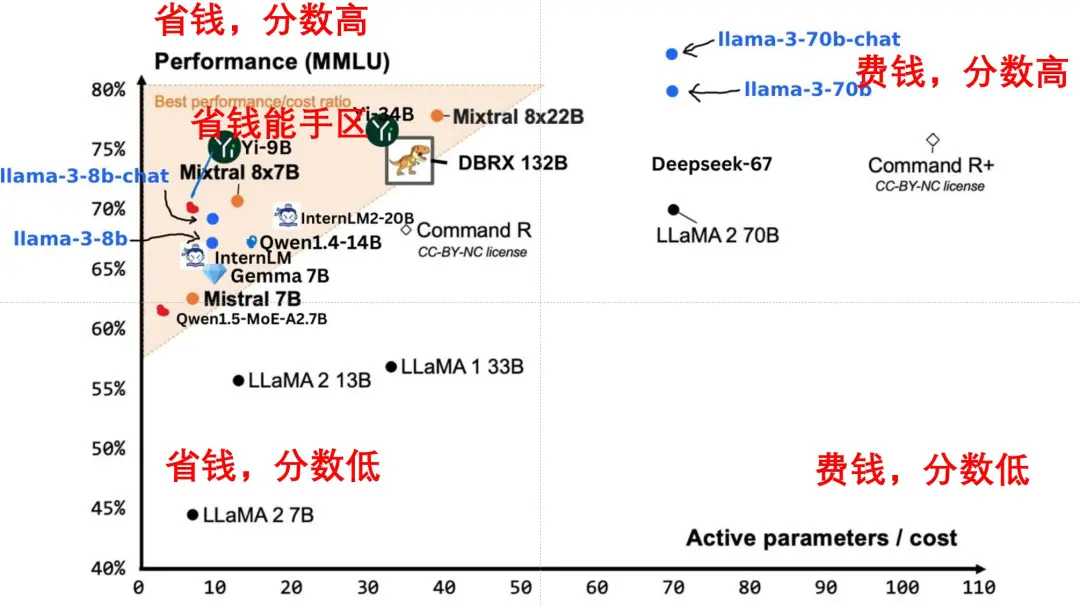
这,可以说是给大模型的开源派大涨了一波士气。
反正消息一出炉,开源社区立马就沸腾了,各种梗图满天飞, 感谢着小扎又带兄弟们冲了一次。
不过,世超觉得既然模型已经上线了,看再多的技术细节和跑分数据,都不如咱们亲自上手试试。

稍微有些可惜的是,目前发出的这两个版本,还没有办法支持中文输出。

也暂时只有文字对话和画图这两个简单的功能。在各家多模态打磨得出神入化的现在,多少有点 OUT 了。

不过好在这次 Meta 的图片输出,有一个挺新奇的功能。我们在聊天框里输入文字,不需要发送, Llama 3 就会实时根据内容生成图像。
比如我分几次在对话框输入了【 一只猫在睡觉、跳舞和跳跃 】,就能看到屏幕上生成的图片内容在跟着实时变化。
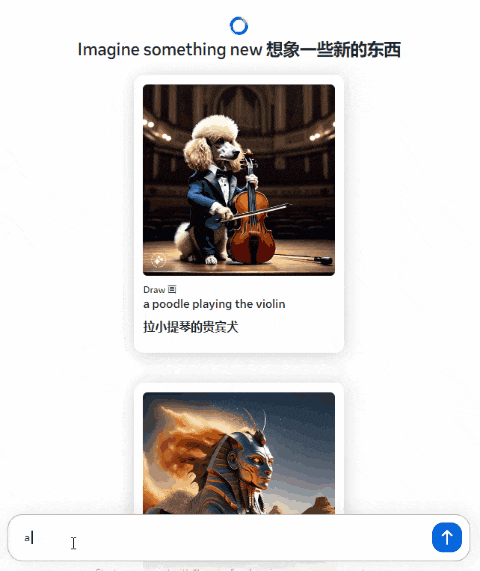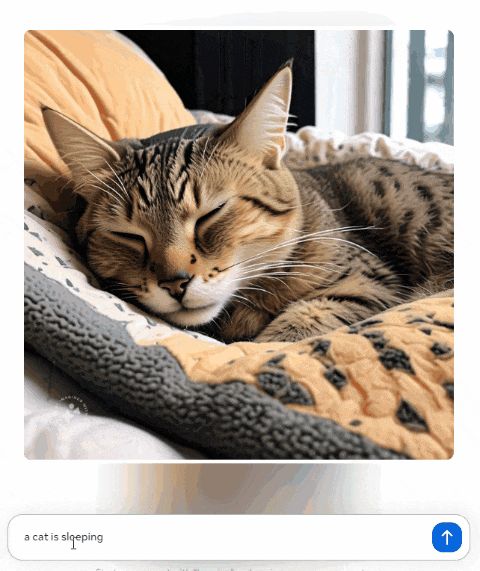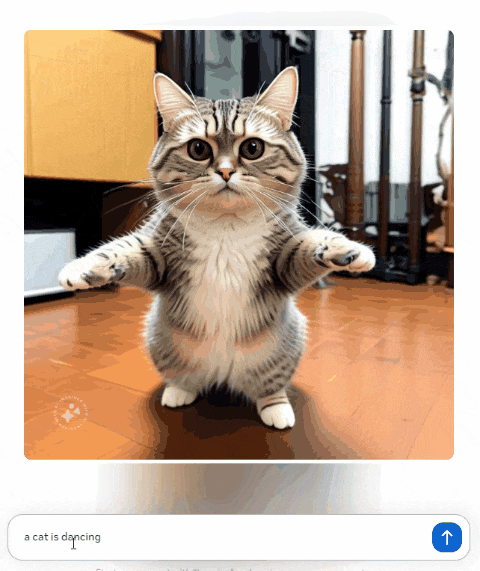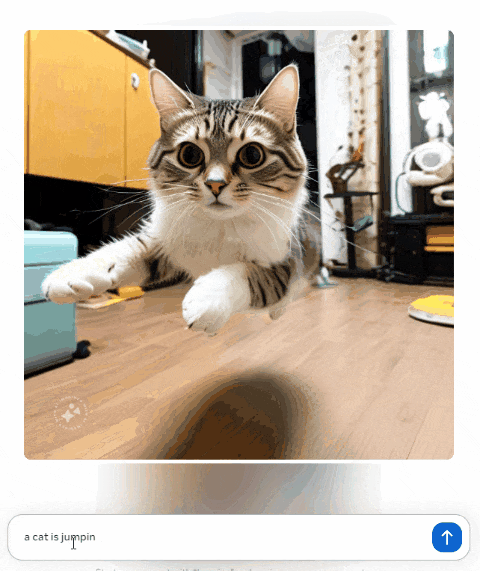
到了文字输出这边,惊喜度就不高了。

既然它在测试中,说自己在编程、多选题等等方面,都赶超 Claude 3 的中型版本,咱也着重测了测这方面的虚实。
世超测了很多题,这里就只放出两边有差别的地方。
比如简单的逻辑推理:我今天有 3 个苹果,昨天吃了一个,今天还剩几个?
Llama 3 完全没有压力,轻松驾驭。

但同样的题抛给 Claude 3 ,却被完全绕进去了。

不过,后面世超后面简单测了几道代码能力,反而 Claude 3 的表现更让人惊艳。
世超要求 Llama 3 给我做两个简单的 html 小游戏。

结果,做出的贪吃蛇和打砖块游戏,都没有办法正常运行。游戏还没有开始,就显示 Game Over 了。
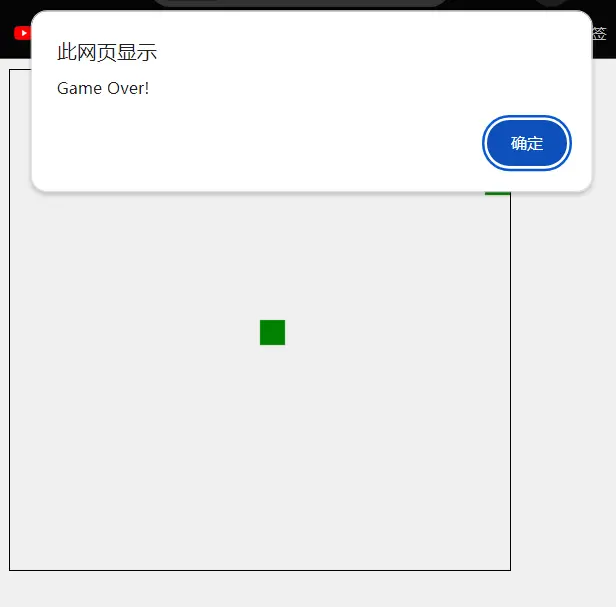
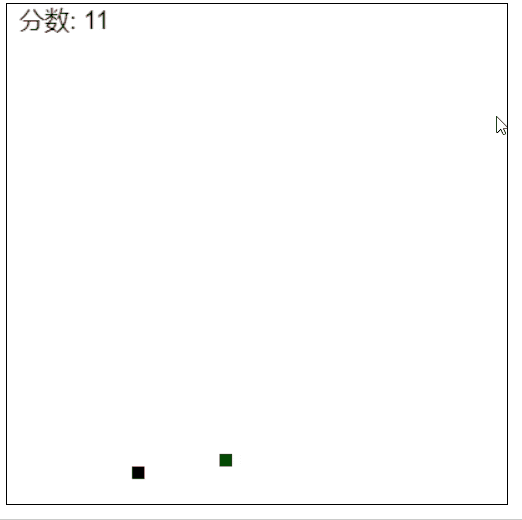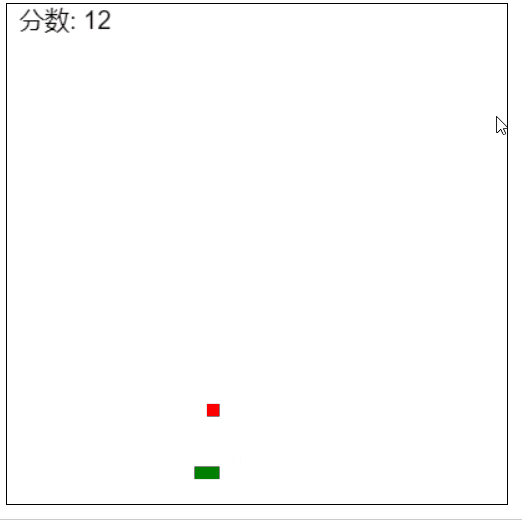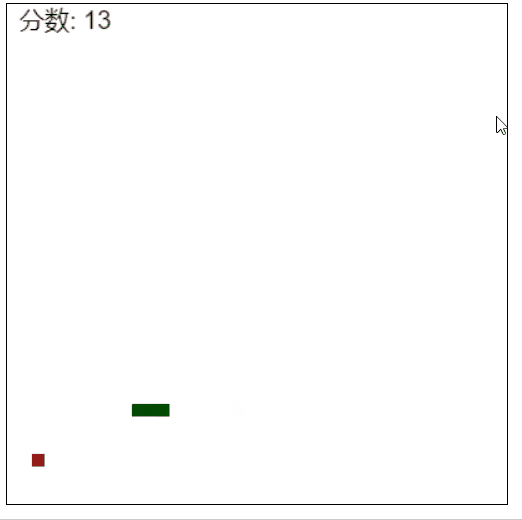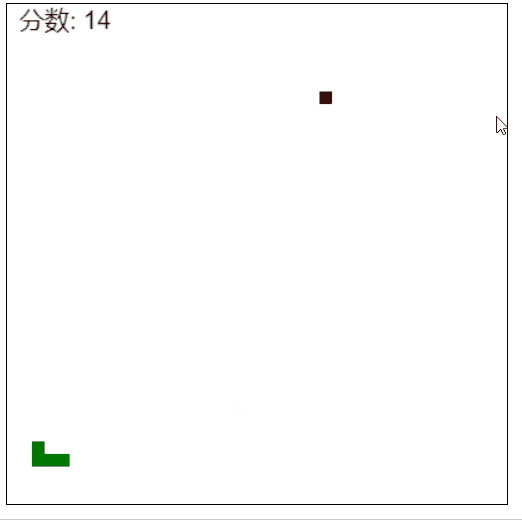
但 Claude 3 这边做的,虽说有点小瑕疵,游戏重新开始之后,分数不会刷新。但除此之外都很完美,游戏能有正常运行。
而且生成速度巨快,几秒钟就做出来。上一次见到这个速度的,还是 GPT-4 。
而在后面的开放题, Llama 3 则又马上扳回了一城。
世超给了一个开放性的问题:类人机器人的未来会是什么样子?
几个字的小问题, Llama 3 按照短期、中期和远期,三个阶段来分点构思了一下可能性。
由于篇幅限制,这里只截取了短期

Claude 3 这边就有些中规中矩了,跟上面分时间、分点罗列的优等生比,逊色不少。

整体测试下来,Llama 3 和闭源的 Claude 3 基本打得有来有回,甚至一些方面小胜。
但如果只能做到这个程度, Meta 这次更新根本没法在圈子里掀起这么大风浪。

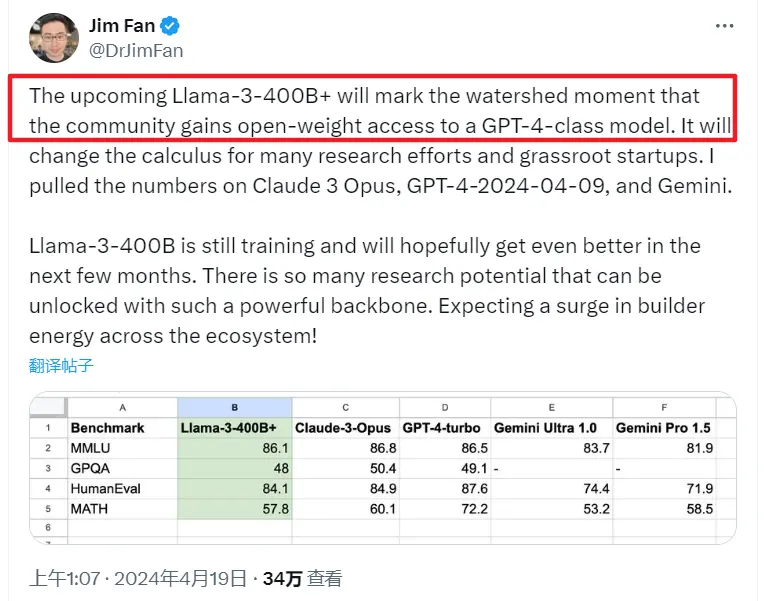
这俩模型并不是重头戏,真正牛叉的地方,是官网里提到的一个信息: 400B+ 参数级的 Llama 3 正在训练准备中了。
从纸面的各项数据上看,它各方面都强得可怕。

Llama 的产品副总裁 Ragavan Srinivasan 在一次采访中说,这个版本可以媲美同类的一流专业模型。
不仅做到媲美,很多功能表现,还要强过 Claude 3 的超大杯版本和 GPT-4 。
虽说 Meta 认为还要评估一下安全性,再决定开不开源,但消息一出,业内早已经开始狂欢了。
因为开源社区的人, 或许不用等着 OpenAI 重拾初心,就能到调教、魔改上 GPT-4 级别的模型 了 。
英伟达科学家直接就发文说,小扎这个 400B+ 的模型,将会是 行业的一个分水岭,会改变很多公司和研究的未来。

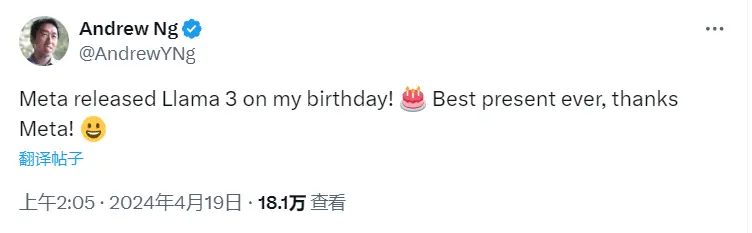
刚好今天过生日的前百度首席科学家、谷歌大脑之父吴恩达,也说 Meta 这次更新,是他 有史以来收到过最好的生日礼物。
可想而知, Llama 3 给行业带来的震撼。
目前,这个 400B+ 的终极版本预计将会在夏天发布。
OpenAI 再不发力, Llama 3 为代表的开源大模型,彻底超车闭源大模型的历史时刻,可能真的就要来临了。
而早在 Llama 3 发布之前,大模型是开源牛,还是闭源好的问题,其实早就吵得不可开交了。
两边阵营都不缺大佬,李彦宏所说的, “ 开源模型会越来越落后 ” ,世超觉得逻辑上是很自洽的。
因为闭源公司有成熟的商业模式,有更多的资金和人力砸进去搞研究,自己辛苦研发的成果,也可以得到保护。简而言之就是能赚钱,能赚钱才能聚集算力、聚集人才。

反观很多开源模型,不仅商业模式还在探索中,有的也都是零零散散的小规模产品。
月之暗面的杨植麟就曾发表过类似的观点,说是大部分基于开源大模型的应用,没有经过大算力的验证,它们在性能的稳定性、未来的可扩展性都不好说。

而支持开源的这一派,世超同样也觉得不无道理。朱啸虎曾经表达过一个看法, 闭源现在确实领先于开源,但开源模型最终会追上。
“OpenAI 就一两百个工程师,开源的全世界几百万、几千万工程师在用,怎么可能一直比非开源的落后? ”

开源社区用了一年时间,就超过了 GPT-3.5 ,现在已经来到 GPT-4 水平。而现在 Llama 3 等模型的大力赶超,正在不断验证这句话。

比尔盖茨早年间,曾经公开吐槽过 Linux 系统。觉得它从商业上来看根本不可行,既不能保护自己的知识产权,又没法赚取收入来搞研发, 最多就是个半吊子。
《 乔布斯传 》中也提到过,乔布斯也怒喷过隔壁安卓就是 shit ,认为它的开源给它带来各种麻烦。
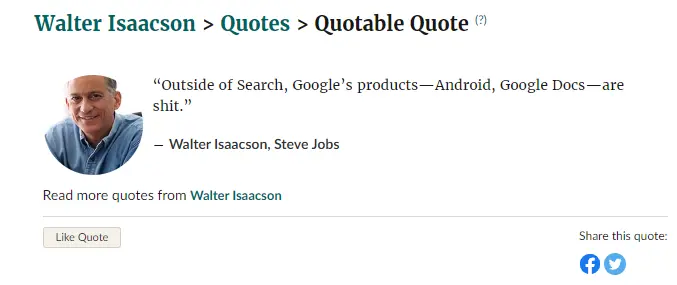

最后这俩超级大佬都被打脸了。。。甚至比尔盖茨后来公开承认微软在偷学 Linux ,安卓也丝毫不比 iOS 差。
而世超觉得,很可能大模型的开源闭源之间,根本就不是你死我活、不是谁强谁就一定弱。
就比如谷歌,基本就是两手抓,既有闭源的 Gemini ,也有开源的 Gemma 。曾靠开源出圈的 Mistral 在拿了微软投资之后,它的 Mistral Large 也不再对外开源。
所以开源和闭源很可能只是路线之别,哪有啥对错,只是有合适与否。
而唯一能确定就是,甭管你是开源还是闭源,烧钱都是逃不开的,无论是 OpenAI 背后的微软,还是 Llama 背后的 Meta ,亦或是国内的 BAT ,大模型的战场还是这帮顶级资本之间的斗争。
咱们就搬好小板凳,磕着瓜子继续吃瓜吧。
撰文:四大 编辑:江江&面线 封面:子曰
Prev Chapter:钉钉宣布正式上线 AI Agent Store
Next Chapter:都是AI的锅?越来越多海外用户抛弃谷歌,转向TikTok和Reddit搜索答案
评论区
- 这篇文章还没有收到评论,赶紧来抢沙发吧~
【随机内容】

