

AI“源神”启动!影响多大?_tiknovel-最新最全的nft,web3,AI技术资讯技术社区
AI“源神”启动!影响多大?
今年年初,埃隆·马斯克在对OpenAI及其CEO萨姆·奥特曼提起诉讼时,就对OpenAI逐渐不公开其模型研究相关细节的行为大加谴责。“时至今日,OpenAI公司网站还宣称,它的宗旨是确保通用人工智能造福全人类。然而,在现实中,OpenAI已经转变为科技巨头微软事实上的闭源子公司。”这位曾经的OpenAI联合创始人如此表示。
OpenAI不够“Open”,Meta却“Open”了自己最新的开源人工智能模型。
4月18日,Meta 发布了其最新版本的开源大模型 Llama 3,引起开源AI社区的一阵欢呼。巧合的是,Llama 3发布当天正好是AI领域顶尖学者、AI开源倡导者吴恩达的生日。“(Llama 3是)至今为止最好的礼物,谢感谢Meta!”他说。
行至2024,开闭源之争日渐白热化。闭源阵营以目前最强的OpenAI为代表,开源阵营Meta的LLaMa、Mistral和Google等也在不断迭代。闭源阵营坚持对Scaling Law的信仰,押注在更强通用模型的打造上;开源阵营模型能力不断提升,并且强调以更垂直的性能、更灵活的配置来推动大模型商业化落地。
关于应该选择模型开源还是闭源讨论经久不息。
对于局内人,这一选择这不仅决定了他们将如何点亮AI“科技树”,更将影响他们的商业路线选择。换言之,这很有可能是这个残酷竞争市场下的生存问题。
两个版本,多重惊喜
Meta此次发布的Llame 3包括8B和70B的预训练和指令微调版本。
据Meta官网信息,Llama 3 模型将数据和规模提升到新的高度。它在两个定制24K GPU集群上基于超过 15T 的数据进行了训练——训练数据集是Llame 2使用量的7倍有余。它支持 8K 上下文长度,是 Llama 2 容量的两倍。
除了 Llama 3,Meta 还发布了新的信任和安全工具,包括Llama Guard 2、Code Shield和 CyberSec Eval 2。
据悉,Llama 3 即将在AWS(Amazon web service)、Databricks、Google Cloud、Hugging Face、Kaggle、IBM WatsonX、 Microsoft Azure等主要云提供商、模型 API 提供商平台上线,Llama还得到AMD、AWS、戴尔、英特尔、NVIDIA和高通提供的硬件平台的支持。
在官网上,Meta还放出了Llama3两个版本与谷歌Gemma、谷歌Gemini、Mistral、Anthropic的Claude 3等竞争对手的参数对比。据Meta官网,Llame3在MMLU(学科知识理解)、GPQA(一般问题)、HumanEval(代码能力)、GSM—8K(数学能力)、MATH(比较难的数学问题)5个评测集上均表现良好。
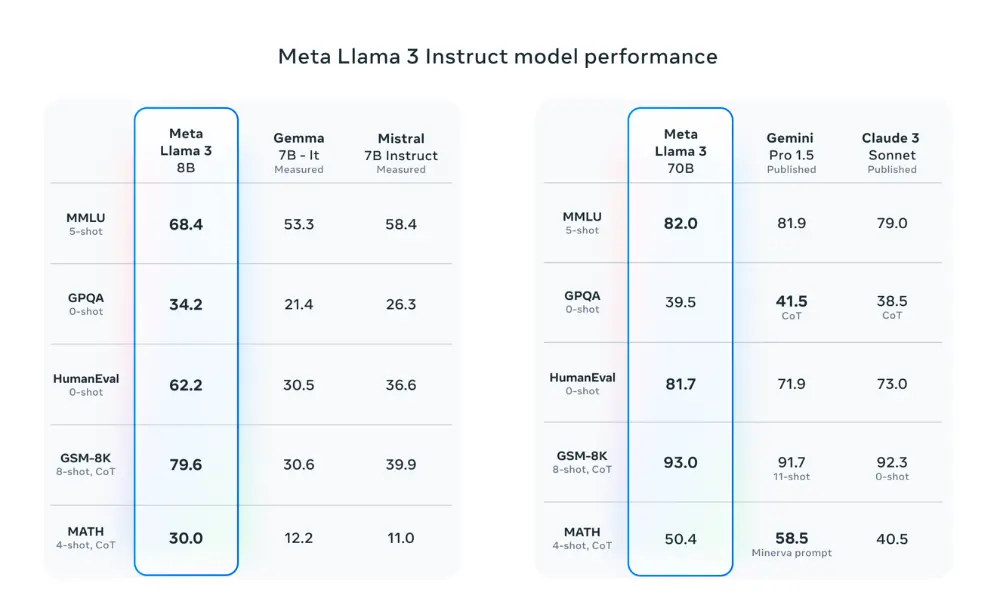
值得注意的是,Llama3的代码能力非常优秀。在AI领域公众号“数字生命卡兹克”主理人卡兹克分享的用户实测中,Llama3—8B能够给出国际象棋中经典皇后问题的解题代码。而其前代版本Llama2需要专门的代码模型才能实现。
市场的反应速度很快。18日当天,Meta股价逆势收涨1.54%。次日,百度智能云千帆大模型平台开放邀约测试,提供针对Llama 3的训练推理方案,帮助开发者训练专属大模型。
8B和70B 两个型号的模型,仅仅标志着 Llama 3 系列的开端,Meta AI首席科学家杨立昆在其社交媒体透露,在接下来的几个月,还会有更多版本陆续发布。
英伟达高级科学家Jim Fan认为之后可能会发布的Llama 3-400B以上的版本将成为某种“分水岭”,开源社区将能用上GPT-4级别的模型。
不下牌桌,各显神通
上一轮元宇宙竞争中被认为可能跌进坑里的Meta,在人工智能的牌桌上打出了Llama系列这把好牌。要讨论Llama3带来的行业震荡,首先要明白,什么是大模型领域的开源?
大模型领域的开源通常意味着模型的架构、训练代码和预训练权重等都被公开,允许研究人员和开发者自由地访问和使用。
不过,开源的程度因模型而异。“有些可能只提供有限的访问权限或部分代码。”郭涛指出,判断大模型是否真正开源的基准可能包括:代码和数据的可访问性、使用许可的宽松程度、社区支持的活跃度以及对改进和新应用的开放性。
放眼AI界,两条路径上都各有“头号玩家”分布。闭源自不必说,海外有OpenAI旗下的ChatGPT,国内是百度的文心一言以及风头正劲的月之暗面Kimi。
而开源方面,除了Llama系列,目前应用较广的开源大模型还包括非营利组织LAION推出的OpenFlamingo、Databricks的Dolly,以及MosaicML的MPT等。国内则包括,阿里巴巴的通义千问,智谱的ChatGLM-4、百川智能的baichuan-7B中英文大模型、北京智源悟道3.0大模型系列和面壁智能的CPM-Bee 10B中文基座大模型等。
形成这样的分化,很多时候是受技术进步和商业模式迭代等的多重影响。
天使投资人、资深人工智能专家郭涛认为,从技术角度来看,开源可以促进学术界的研究和创新,而闭源则有助于在一定时间内保持技术领先优势。
从商业角度来看,开源可以吸引开发者社区的贡献,促进技术的快速迭代和应用的广泛传播,但可能会影响到公司的盈利模式。闭源则可以保护知识产权,为公司创造直接的收入来源,但可能会限制技术的普及和生态的建设。
事实上,在Llama3发布之前,中文互联网刚刚经历了一轮开闭源论战。
据媒体报道,百度CEO李彦宏近日表态,认为大模型开源意义不大,闭源模型性能会不断提升。“有了文心大模型4.0,我们可以根据需要兼顾效果、响应速度、推理成本等各种考虑,裁剪出适合各种场景的更小尺寸模型,且支持精调和post pretrain。通过降维裁剪出的模型,比直接拿开源调出来的模型,同等尺寸下效果更好,同等效果下成本明显更低。”
李彦宏一直是闭源路线的忠实拥趸,理由包括但不限于认可闭源商业模式可以更好地聚集人力和财力等。
而其反对者——360创始人周鸿祎言简意赅,“一句话,今天没有开源就没有 Linux,没有 Linux 就没有互联网。”
“源神”启动,影响几何?
“Llama 3的发布会带来市场格局的改变。”郭涛在接受21记者采访时指出,其优异表现可能吸引更多的用户和投资者,从而增加其市场份额。
官网显示,Llama 3将有条件地开源给商业使用(月活用户超过7亿需要单独申请)。“不过这基本等于完全免费商用了。”卡兹克表示。
此前,投资人朱啸虎曾经就人工智能市场相关话题接受腾讯新闻采访。当被问及2023年大模型发展的关键节点时,他给出的回答正是Llama上线。这让中国在应用层面创新有了基础,降低了商业化门槛。
当然,朱啸虎提到的变现是指开源生态内的用户。对于开源大模型发布者的能否盈利,或者能等来盈利机会,很多时候并没有确定的答案。
闭源大模型通常通过授权使用、订阅服务或者直接销售产品来盈利。其中的代表便是AI领域的领跑者OpenAI,虽然其一直有推进开源项目的动作,但其处在核心地位的ChatGPT却一直采取收取API许可费的方式向其他公司提供服务。在API服务过程,其他公司不会接触到ChatGPT模型的细节和源代码,仅仅通过API接口进行调用。
创业者服务平台GoDaddy对全美1003家小型企业的调查数据显示,ChatGPT以70%的应用率成为美国小型企业应用最多的生成式AI产品,这说明OpenAI选择的闭源模式的商业化之路在一定程度已经跑通。
开源模型如何寻求生存和发展的机会?
首先是以开放的生态吸引用户。国盛证券研报就指出,开源大模型借助更大标识符训练数据集、DeepSpeed、RLHF等方式,实现低训练成本和高性能,超大模型以下大模型的壁垒正在消失。
“在拥有用户后,开源大模型通常通过提供增值服务、定制开发、技术支持等方式来实现盈利”。郭涛指出,公司可以在开源模型的基础上提供专业的训练服务或者定制化的应用解决方案。
对于Meta甚至众多开源者而言,开源的野心不仅是短期的商业变现,其更想引领规则设计以及搭建生态。 有业内专家分析,开源后壁垒并没有那么容易破除,高质量、标注过的训练数据集尤其是专业模型的壁垒。
星纪魅族集团数据合规执行总监朱玲凤表示,目前有些开源AI由头部公司主导,“越多人使用,就越能强化网格效应,而且不是真正的开放,后续需要使用它们的配套工具、配套服务。头部公司还可能利用监管豁免的方式,获得寻租空间。”换言之,以开源为噱头的巨头游戏,可能会进一步强化大公司的垄断地位,反而不利于产业竞争。
据报道,去年4月,在扎克伯格与分析师的一次电话会议中,他就谈到,如果行业能够在Meta使用的基础工具上达成标准化,那么meta就能从其他人的改进中受益。同年5月,谷歌内部泄露的文件《我们没有护城河,OpenAI也没有》在SemiAnalysis网站上传播,其中的观点包括,比起开源社区需要谷歌,谷歌更需要开源社区等等。文章作者指出,不同开源模型所组成的生态系统永远是OpenAI的潜在竞争对手,与开源AI竞争的结果必然是失败。
Meta落子,战局生变。大模型的路线之争会不会迎来真正的胜利者?
“开源与闭源大模型之间不太可能分出绝对的输赢,因为它们各自适合不同的应用和场景。”郭涛认为,开源大模型更适合那些需要快速创新和大规模协作的项目,而闭源大模型可能更适合那些对性能和安全性有极高要求的商业应用。
Prev Chapter:谷歌全面整合AI力量背后:DeepMind浮沉史
Next Chapter:#英伟达黄仁勋称人型机器人将大众化#,其制造成本将会“远低于”人们的预期
评论区
- 这篇文章还没有收到评论,赶紧来抢沙发吧~
【随机内容】

