

使用 Kafka 分区扩展 Spring Batch 处理_tiknovel-最新最全的nft,web3,AI技术资讯技术社区
使用 Kafka 分区扩展 Spring Batch 处理
到目前为止,我还没有真正涵盖批处理作业的主题,碰巧我最近需要使用它们,并基于 Spring Batch 设计一个非常复杂的批处理作业设置,并使用 Kafka 进行分区。
显然,我不会描述确切的系统,而只会描述 Spring Batch 提供的一些概念以及工作示例。
问题陈述
让我们谈谈问题陈述。我不会大体上详细介绍批处理作业,而是关注一个更具体的问题——扩展批处理作业。
想象一个您需要定期运行的流程,例如一天结束 (EOD)。假设这个过程需要处理的数据量在不断增加。
在一个天真的世界里,你可以做一个非常简单的 Spring 调度(或者 Quartz 或者你有什么),它只执行一个方法,一次加载所有数据,处理所有数据并将结果写回数据库。
伪代码类似于:
这有什么问题?在您读取的数据量保持不变并且一次读取全部满足需求之前,什么都没有。
现在假设我们读取的行数(例如从数据库中)是 10 000 行。工作得很好,但如果突然有 10 000 000 行怎么办?执行可能会失败,因为
或者需要永恒的时间才能完成。
那么,我们如何才能使其具有可扩展性,并确保从长远来看,不断增长的数据量也不会成为问题呢?
远程分区
好吧,远程分区的概念很简单。
您获取初始数据集,例如,如果我们从数据库中读取事务(或任何域对象),我们只获取事务 ID。将它们划分为分区(不是块;块在 Spring Batch 世界中具有不同的含义)并将分区发送给可以处理它们并执行实际业务逻辑的工作人员。
我刚刚描述的内容也可能适用于常规分区。常规分区和远程分区之间的主要区别在于工作人员所在的位置。在常规分区的情况下,充当工作者的进程是与分区数据的进程相同的 JVM 中的本地线程。
但是,在远程分区的情况下,worker 不是在同一个 JVM 中运行,而是完全不同的 JVM。当有一些工作需要处理时,会通过消息系统通知各个工作人员。
下图说明了这个想法:
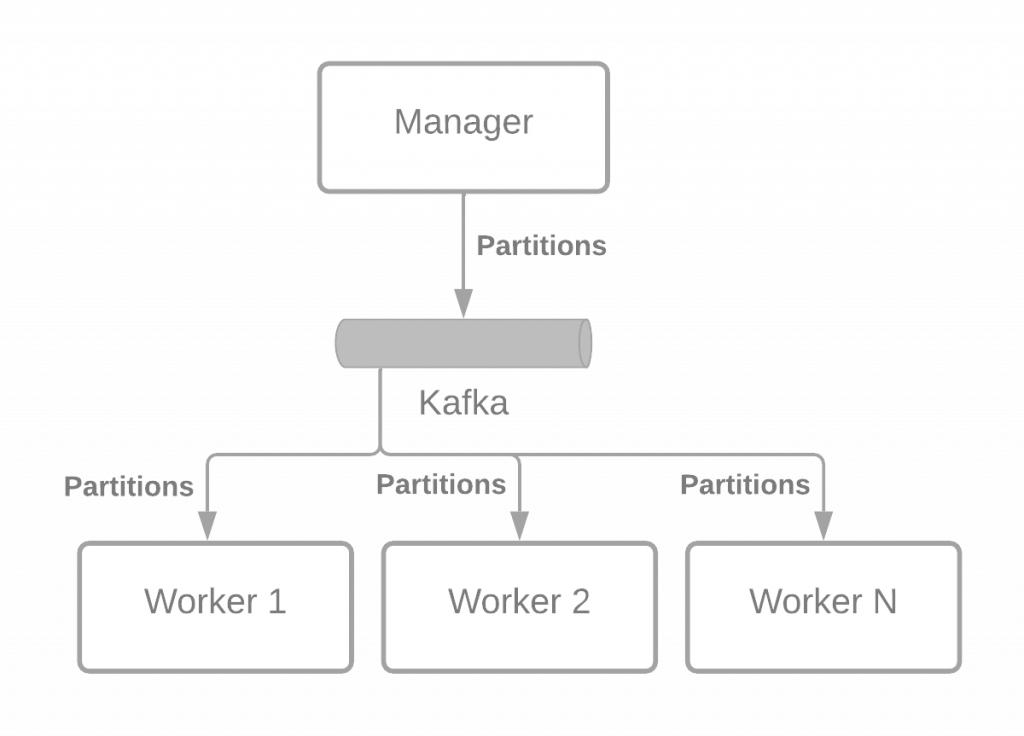
每种环境中的消息传递中间件可能不同,但为了本文的篇幅,我将选择 Kafka(可能稍后我也会写一篇关于 AWS SQS 的文章)。
限制
Kafka 基于主题进行操作。主题可以有分区。您可以拥有的消费者数量(对于同一消费者组)取决于您为主题拥有的分区数量。这意味着您的分区批处理作业的并发因素与主题分区的数量直接相关。
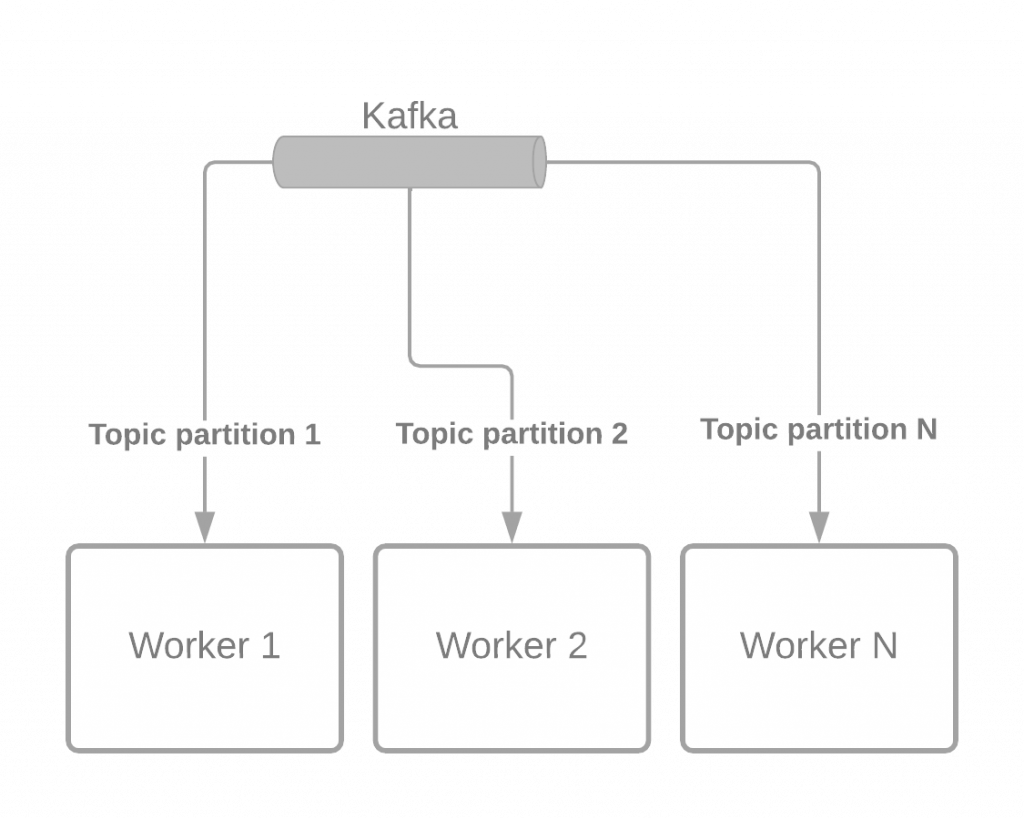
用于主题的分区数量应在创建主题时设置。稍后,可以更改现有主题的分区数量,但是您必须注意某些副作用。
这意味着开箱即用的 Kafka 无法根据数据量动态扩展工作人员的数量。动态我的意思是有时您需要 10 个工作人员,但假设数据量在圣诞节期间大幅增加,您需要 50 个。这就是您需要一些自定义脚本的事情。
毕竟,我认为一个好的经验法则——在 Kafka 的情况下——是加大主题分区的数量。假设您在非高峰期需要 10 个消费者,而在高峰期需要 20 个,我会说您可以选择两倍/三倍,以确保您有增长空间而不会感到头疼。所以我会说 60 可能是一个很好的分区号,最多支持 60 个同时消费者。当然,这取决于您的数据量增长的速度,但您明白了。
规模化行动
现在是编码时间,让我们看看这一切的实际效果。
传送门:
https://arnoldgalovics.com/spring-batch-remote-partitioning-kafka/?utm_source=reddit&utm_medium=post&utm_campaign=spring-batch-remote-partitioning-kafka&continueFlag=095e56c3e42ca0e7c92e666cb86ec3a9
Prev Chapter:使用 Python 实际学习区块链概念
Next Chapter:《机器学习100天》 100-Days-Of-ML-Code中文版
评论区
- 这篇文章还没有收到评论,赶紧来抢沙发吧~
【随机内容】



