

用ChatGPT设计了一颗芯片_tiknovel-最新最全的nft,web3,AI技术资讯技术社区
用ChatGPT设计了一颗芯片
摘要
现代硬件设计始于以自然语言提供的规范。然后,在综合电路元件之前,硬件工程师将其翻译成适当的硬件描述语言(HDL),例如Verilog。自动翻译可以减少工程过程中的人为错误。但是,直到最近,人工智能(AI)才展示出基于机器的端到端设计翻译的能力。商业上可用的指令调优的大型语言模型(LLM),如OpenAI的ChatGPT和谷歌的Bard,声称能够用各种编程语言生成代码;但对它们进行硬件检查的研究仍然不足。因此,在本研究中,我们探讨了在利用LLM的这些最新进展进行硬件设计时所面临的挑战和机遇。我们使用一整套包含8个代表性的基准,检查了在为功能和验证目的生成Verilog时,最先进的LLM的能力和局限性。考虑到LLM在交互使用时表现最好,我们随后进行了一个更长的完全对话式案例研究,该研究中LLM与硬件工程师共同设计了一种新颖的基于8位累加器的微处理器架构。该处理器采用Skywater 130nm工艺,这意味着这些“Chip-Chat”实现了我们认为是世界上第一个完全由人工智能编写的用于流片的HDL。
01 介绍
A.硬件设计趋势
随着数字设计的能力和复杂性不断增长,集成电路(IC)计算机辅助设计(CAD)中的软件组件在整个电子设计自动化流程中都采用了机器学习(ML)。在传统方法试图对每个过程进行形式化建模的情况下,基于ML的方法侧重于识别和利用可推广的高级特征或模式——这意味着ML可以增强甚至取代某些工具。尽管如此,IC CAD中的ML研究往往侧重于后端过程,如逻辑综合、布局、走线和属性估计。在这项工作中,我们探索了将一种新兴类型的ML模型应用于硬件设计过程的早期阶段时的挑战和机遇:硬件描述语言(HDL)本身的编写。
B.自动化硬件描述语言(HDL)
虽然硬件设计是用规范语言(HDL)表示的,但它们实际上是以自然语言提供的规范(例如英语需求文件)开始设计生命周期的。将这些转换为适当的HDL(例如Verilog)的过程必须由硬件工程师完成,这既耗时又容易出错。使用高级综合工具等替代途径可以使开发人员能够用C等高级语言指定功能,但这些方法是以牺牲硬件效率为代价的。这激发了对基于人工智能(AI)或ML的工具的探索,使其作为将规范转换为HDL的替代途径。
这种机器翻译应用程序的候选者来自GitHub Copilot等商业产品推广的大型语言模型(LLM)。LLM声称可以用多种语言生成代码,以用于各种目的。尽管如此,它们还是更加专注于软件,这些模型的基准测试针对Python等语言对它们进行评估,而不是针对硬件领域的需求。因此,硬件设计社区的使用仍然落后于软件领域。尽管“自动完成”风格模型的基准测试步骤已经开始出现在文献中,但最新的LLM,如OpenAI的ChatGPT和谷歌的Bard,为其功能提供了一个不同的“对话式”聊天界面。
因此,我们提出了以下问题:将这些工具集成到HDL开发过程中的潜在优势和障碍是什么(图1)?我们做了两个对话实验。第一个实验涉及预定义的对话流和一系列基准挑战(第三节),而第二个实验涉及开放式的“自由聊天”方法,LLM在更大的项目中担任联合设计师(第四节)。
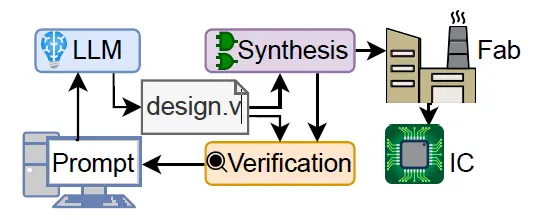
图1 会话LLM可以用于迭代设计硬件吗?
为了理解这项新兴技术的重要性,进行这样的研究至关重要。ChatGPT在医疗保健、软件和教育等各个领域也在进行类似的研究。我们对会话LLM对硬件设计的影响的调查是很有必要的。
C.贡献
本研究的贡献包括:
对会话LLM在硬件设计中的使用进行了首次研究。
制定基准以评估LLM在功能硬件开发和验证方面的能力。
利用ChatGPT-4对硬件中复杂应用程序的端到端协同设计进行观察性研究。
首次使用人工智能为流片编写完整的HDL,实现了一个重要的里程碑。
为在硬件相关任务中有效利用LLM提供实用建议。
开源:所有基准测试、流片工具链脚本、生成的Verilog和LLM对话日志都在Zenodo上提供。
02 背景及相关工作
A.大型语言模型 (LLMs)
大型语言模型(LLM)是用Transformer体系结构构建的。早期的例子包括BERT和GPT-2,但直到GPT-3系列模型,这些模型的相对能力才变得明显。其中包括Codex,它拥有数十亿的学习参数,并在数百万个开源软件存储库上进行了训练。在最先进的技术中,有几十种LLM(包括开源、非开源和商业),可用于通用和特定任务的应用程序。
尽管如此,所有LLM都有一些共同点。它们都充当“可伸缩序列预测模型”,这意味着给定一些“输入提示”,它们将输出该提示的“最有可能”的延续(将其视为“智能自动完成”)。对于此I/O,它们使用令牌,即使用字节对编码指定的常见字符序列。这很有效,因为LLM具有固定的上下文大小,这意味着它们可以提取比通过对字符进行操作更多的文本。对于OpenAI的模型,每个令牌代表大约4个字符,其上下文窗口的大小最多可达8000个令牌(这意味着它们可以支持大约16000个字符的I/O)。
B.用于硬件设计的大型语言模型
Pearce等人首次探索了在硬件领域使用LLM。他们在综合生成的Verilog片段上微调了GPT-2模型(他们称之为DAVE),并对“本科生级别”任务的模型输出进行了词法评估。然而,由于训练数据有限,该模型无法推广到不熟悉的任务。Thakur等人扩展了这一想法,探索了如何严格评估生成Verilog的模型性能,以及使用不同的策略来训练Verilog编写模型。其他工作探究了这些模型的含义:GitHub Copilot研究了Verilog代码中6种类型硬件错误的发生率,当探讨是否可以使用Codex模型实现自动错误修复时,他们还包括Verilog中的两个硬件CWE。
在这个行业,人们对此的兴趣也越来越强烈:Efabless最近启动了人工智能生成设计大赛,评委来自高通和新思等公司。RapidSilicon等新公司正在推广RapidGPT等即将推出(但尚未发布)的工具,这些工具将在该领域发挥作用。
C.训练调优的“对话”模型
最近,一种新的训练方法——“基于人类反馈的强化学习(RLHF)”被应用于LLM。通过将其与特定意图的标记数据相结合,可以生成更能遵循用户意图的指令调优模型。如果以前的LLM侧重于“自动完成”,则可以对其进行“遵循说明”的训练。还有一些研究提出的方法不需要人类反馈,然后可以对它们进行微调,以便更好地关注对话式的互动。ChatGPT(包括ChatGPT-3.5和ChatGPT-4版本)、Bard和HuggingChat等模型都使用这些技术进行了训练。它们为硬件领域的工作提供了一个令人兴奋的新的潜在接口。然而,据作者所知,目前还没有人深入探索过这种应用。
03 探索“脚本化”基准
A.概览
从本质上讲,有无数种方法可以与会话模型“聊天”。为了探索使用会话LLM实现“标准化”和“自动化”流程的潜力,我们在一系列基准上定义了一个严格的“脚本化”会话流程。然后,我们使用一致的指标评估一系列LLM,根据通过附带testbench所需的指令水平来确定对话的相对成功或失败。然而,尽管对话流在结构上保持相同,但它在测试运行之间固有地存在一些变化,这是基于评估者需要决定(a)每个步骤中需要什么反馈以及(b)如何标准化人工反馈。
B.方法
对话流程:图2详细介绍了与LLM进行对话以创建硬件基准的一般流程。图3和图4中详细说明的初始提示首先提供给该工具。然后对输出设计进行视觉评估,以确定其是否符合基本设计规范。如果设计不符合规范,则会以相同的提示重新生成最多五次,之后如果仍然不符合规范则会失败。
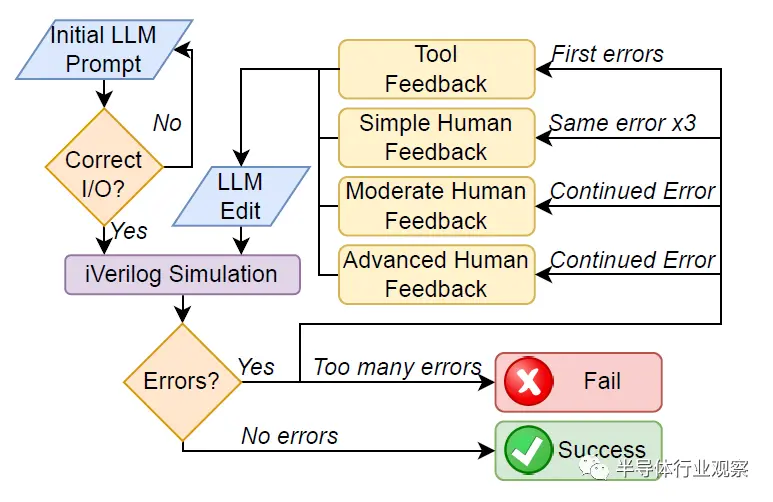
图2 简化的LLM对话流程图

图3 8位移位寄存器:设计提示

图4 testbench提示
设计和testbench编写完成后,将使用Icarus Verilog(iverilog)进行编译,如果编译成功,则进行模拟。如果没有报告错误,则设计通过而不需要反馈(NFN)。如果这些操作中的任何一个报告了错误,它们会被反馈到模型中,并被要求“请提供修复”,称为工具反馈(TF)。如果相同的错误或错误类型出现三次,则用户通常会给出简单的人工反馈(SHF),说明Verilog中的哪种类型的问题会导致此错误(例如,声明信号时的语法错误)。如果错误持续存在,则会给出适度的人工反馈(MHF),并向工具提供稍微更有针对性的信息来识别特定错误,如果错误持续,则会提供高级人工反馈(AHF),该反馈依赖于准确指出错误的位置和修复错误的方法。一旦设计在没有失败测试用例的情况下进行编译和模拟,它则被认为是成功的。然而,如果高级反馈无法修复错误,或者用户需要编写任何Verilog来解决错误,则该测试被视为失败。如果会话超过25条消息,与每3小时ChatGPT-4消息的OpenAI速率限制相匹配,则该测试也被视为失败。
在对话中需要考虑到特殊情况。由于一个模型在一次响应中输出量的限制,文件或解释往往会被切断;在这些情况下,模型将提示“请继续”。“继续”后面的代码通常从前面消息的最后一行之前开始,因此当代码被复制到文件中进行编译和模拟时,它被编辑以形成一个内聚块。然而,没有为该过程添加额外的HDL。类似地,在某些情况下,响应中包含了供用户添加自己代码的注释。如果这些注释会阻止功能,例如留下不完整的数组,则会重新生成响应,否则会保持原样。
功能提示:这个一致且对话风格的提示构建如下:“我正在尝试为[测试名称]创建一个Verilog模型。”然后模型将提供规范,定义输入和输出端口,以及所需的任何进一步细节(例如序列生成器将产生的预期序列),然后是备注“我该如何编写符合这些规范的设计?”。图3显示了8位移位寄存器的设计提示,该寄存器被用作每个LLM的初始评估。
验证提示:对于所有设计,testbench提示(图4)保持不变,因为请求testbench不需要包含关于创建的设计的任何附加信息。这是因为testbench提示将遵循LLM生成的设计,这意味着他们可以考虑所有现有的会话信息。它要求所有testbench都与iverilog兼容,以便于模拟和测试,并有助于确保只使用Verilog-2001标准。
C.现实世界的设计约束
这项工作旨在研究会话生成大语言模型在现实世界硬件设计中的应用,该模型具有综合、预算和流片输出限制。因此,在这个项目中,我们瞄准了现实世界平台Tiny Tapeout 3。这增加了设计的限制:具体来说,是对IO的限制——每个设计只允许8位输入和8位输出。由于标准挑战基准测试的目标是同时实现几个,因此为多路复用器保留了3位输入,以选择哪个基准测试的输出。这意味着每个基准只能包括5位输入,包括时钟和重置。
Tiny Tapeout工具流依赖于OpenLane,这意味着我们仅限于可合成的Verilog-2001 HDL。相对较小的区域虽然不是挑战基准的主要问题,但确实影响了处理器的组件和接口(第四节)。
D.挑战基准
针对这一挑战的基准测试旨在深入了解不同LLM可以编写的硬件级别。目标功能通常在硬件中实现,并且通常在本科生数字逻辑课程的水平上教授。基准见表一。

表一 基准描述
一些基准测试在初始设计之外有自己的特定要求,以帮助检查LLM如何处理不同的设计约束。序列生成器和检测器都被分别赋予了它们的特定模式来生成或检测,ABRO使用一个热态编码,LFSR具有特定的初始状态和抽头位置。其他基准测试,如移位寄存器,保持最低限度的描述性,以注意在约束较少的情况下,模型的输出是否存在任何模式。
E.模型评估:度量
我们评估了四种不同的会话LLM在创建用于硬件设计的Verilog方面的熟练程度,如表II所示。作为初始测试,这些模型中的每一个都被提示了8位移位寄存器基准提示,目的是继续进行第III-B节中的会话流程。每个LLM对设计提示的响应如图5、6、7和8所示。
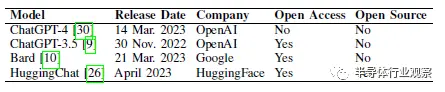
表二 已评估的会话LLM
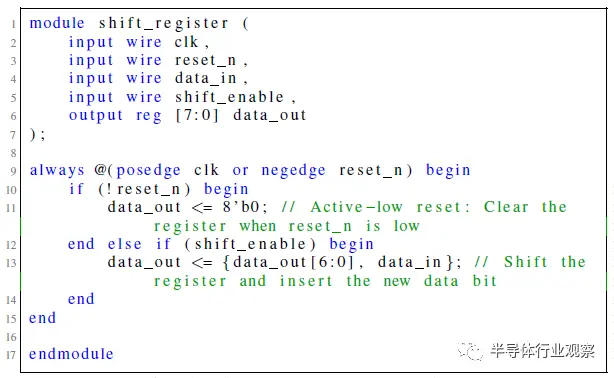
图5 来自ChatGPT-4的8位移位寄存器尝试。
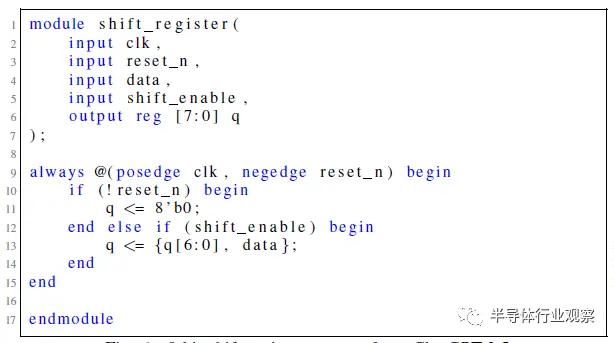
图6 来自ChatGPT-3.5的8位移位寄存器尝试。
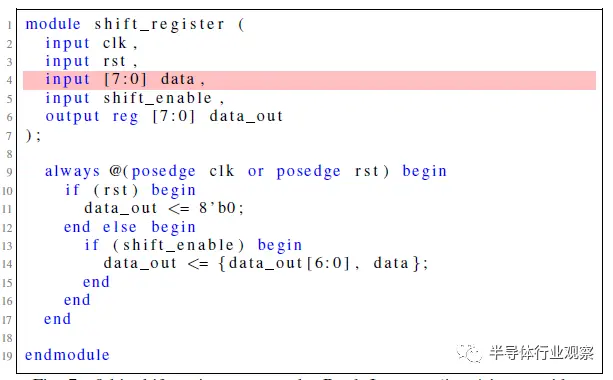
图7 巴德的8位移位寄存器尝试。第4行的输入太宽。
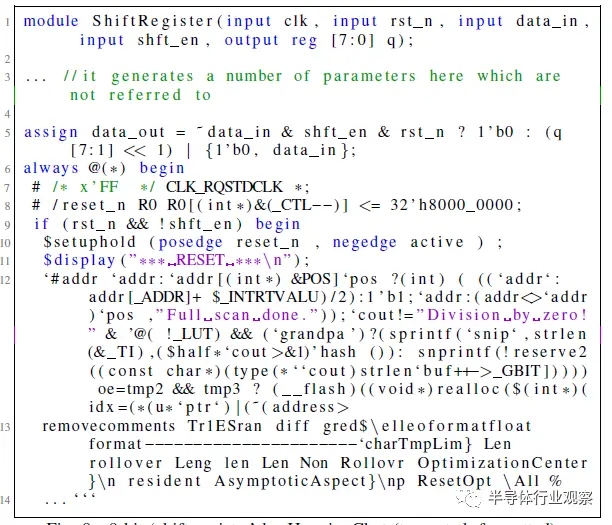
图8 HuggingChat的8位“移位寄存器”(截断,格式化)。
这些测试中的每一项都被视为完整会话流的开始,因此,尽管两个ChatGPT模型都能够满足规范并开始通过设计流,但Bard和HuggingChat都未能满足规范的初始标准。根据计划的对话流程,对Bard和HuggingChat最初提示的响应被重新生成了五次,但都一再失败。Bard一直未能满足给定的设计规范,HuggingChat的Verilog输出在模块定义后的语法上也不正确。图7和图8代表了这两个模型的最终尝试。
鉴于Bard和HuggingChat在最初的Challenge Benchmark提示中表现不佳,我们决定继续进行仅针对ChatGPT-4和ChatGPT-3.5的全套测试,这两个测试都能够持续进行对话流。对于整套基准测试,我们运行了三次这些对话,因为LLM是不确定的,并且能够对相同的输入提示做出不同的响应。因此,这种重复提供了一个基本的衡量标准,即他们能够在多大程度上一致地创建不同的基准和testbench,以及在给定相同初始提示的情况下,不同的运行在实现中会有多大差异。
合规与不合规设计:考虑到语言模型创建了功能代码和验证testbench,当设计“通过”testbench时,它可能仍然“不符合”原始规范。因此,我们将每个结果总体上标记为“符合”或“不符合”。
F.对话示例
图9为移位寄存器T1提供了与ChatGPT-4对话的剩余部分的示例。为了简洁起见,我们删除了响应中不相关的部分。这个对话流遵循图3中的初始设计提示、图5中返回的设计以及图4中的testbench提示。

(a)有错误的8位移位寄存器testbench部分

(b)8位移位寄存器的工具反馈提示

(c) 已更正部分testbench代码。替换的值加粗/突出显示。
图9 成功移位寄存器T1与ChatGPT-4对话的剩余部分。设计符合要求。
不幸的是,它生成的testbench包含错误的跟踪(相关部分如图9a所示)。模拟时,这将打印错误消息。使用图9b中的消息将这些消息返回给ChatGPT-4。这将提示ChatGPT-4修复testbench,给出图9c中的代码。错误得到了解决,设计和testbench现在相互验证,这意味着满足了会话设计流标准。此外,人工审核显示移位寄存器符合原始规范。
G.结果
所有聊天日志都在数据存储库中提供。表III显示了使用ChatGPT-4和-3.5运行的脚本基准测试的三个测试集的结果。
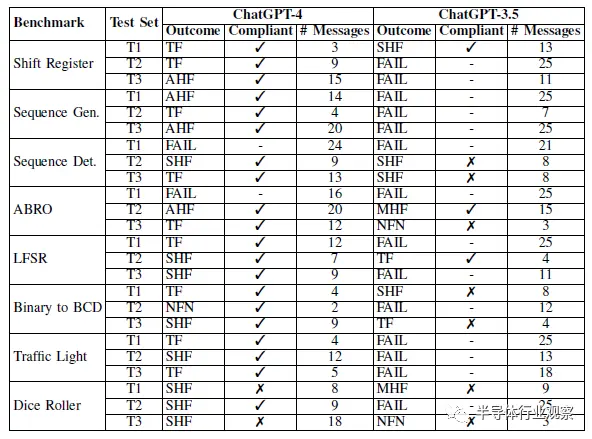
表III基准挑战结果
ChatGPT-4表现良好。大多数基准测试都通过了,其中大多数只需要工具反馈。ChatGPT-4在testbench设计中最常需要人工反馈。
几种故障模式是一致的,一个常见的错误是在设计或testbench中添加了SystemVerilog特定的语法。例如,它通常会尝试使用typedef为FSM模型创建状态,或实例化向量数组,这两种方法在Verilog-2001中都不受支持。
总的来说,ChatGPT-4生产的testbench并不是特别全面。尽管如此,通过其配套testbench的大多数设计也被认为是符合要求的。两次不合规的“通过”是掷骰子机,没有产生伪随机输出。为了结束设计循环,我们从Tiny Tapeout 3的ChatGPT-4对话中合成了测试集T1,添加了一个由ChatGPT--4设计但未测试的包装器模块。在所有的设计中,需要85个组合逻辑单元、4个二极管、44个触发器、39个缓冲器和300个抽头来实现。
ChatGPT-3.5:ChatGPT-3.5的表现明显比ChatGPT-4差,大多数对话都导致了基准测试失败,而通过自己testbench的大多数对话都是不合规的。与ChatGPT-4相比,ChatGPT-3.5的故障模式不太一致,每次对话和基准测试之间都会出现各种各样的问题。它比ChatGPT-4更经常地需要对设计和testbench进行修改。
H.观察
在使用挑战基准测试的四个LLM中,只有ChatGPT-4表现良好,尽管大多数对话仍然需要人工反馈才能成功并符合给定的规范。在修复错误时,ChatGPT-4通常需要几条消息来修复小错误,因为它很难确切了解是什么特定的Verilog行会导致来自iverilog的错误消息。它会添加的错误也往往会在对话之间重复出现。
与功能设计相比,ChatGPT-4在创建功能testbench方面也困难得多。大多数基准测试几乎不需要对设计本身进行修改,而是需要对testbench进行维护。FSM尤其如此,因为该模型似乎无法创建一个testbench,在没有关于状态转换和相应预期输出的重要反馈的情况下,该testbench将正确检查输出。另一方面,ChatGPT-3.5在testbench和功能设计方面都很吃力。
04 共同设计的探索:非结构化对话
A.概览
现实世界中的硬件设计将比我们在第三节中调查的要求更广泛、更复杂。考虑到以前使用的方法,这是一个挑战,因为它对人类与LLM交互的方式进行了脚本化和限制。然而,鉴于不同级别的人类反馈相对成功,我们试图调查非结构化对话是否可以提高效率和相互创造力。一般来说,这项研究将通过大规模的用户研究来完成,硬件工程师将在开发过程中与该工具配对。这类研究是在LLM的软件领域进行的,例如谷歌的这个例子,它将其专有LLM与超过一万名软件开发人员配对,并发现对开发人员的生产力产生了可衡量的积极影响(将其编码迭代持续时间减少了6%,上下文切换次数减少了7%)。我们的目标是通过进行概念验证实验来激励硬件领域的这项研究,在该实验中,我们将LLM(性能最好的模型,OpenAI的ChatGPT-4)与经验丰富的硬件设计工程师(论文作者之一)配对,并在负责进行更复杂的设计时对结果进行定性检查。
B.设计任务:一种基于8位累加器的微处理器
限制:我们再次遵守第III-C节中规定的要求。我们希望ChatGPT-4编写所有处理器的Verilog(不包括顶级Tiny Tapeout包装器)。为了确保我们可以从处理器加载和卸载数据,我们要求所有寄存器连接在移位寄存器的“扫描链”中。
总体目标:共同设计基于8位累加器的架构。ChatGPT-4的初始提示如图10所示。考虑到空间限制,我们的目标是使用32字节内存(数据和指令相结合)的冯·诺依曼型设计。

图10 基于8位累加器的处理器:启动协同设计提示
任务划分:考虑到所探索的LLM的优势和劣势,并避免产生“不合规”设计(见第III-E节),对于该设计任务,经验丰富的人类工程师负责(a)指导ChatGPT-4,以及(b)验证其输出。同时,ChatGPT-4全权负责处理器的Verilog代码。它还产生了处理器的大部分规格。
C.方法:对话流
Prev Chapter:GPT-4比人类更懂融资!AI企划书让VC疯狂打call
Next Chapter:AI史上重大转折 OpenAI美女CTO揭晓ChatGPT内幕
评论区
- 这篇文章还没有收到评论,赶紧来抢沙发吧~
【随机内容】
-

Alchemy Emperor Of The Divine Dao Chapter 3618: Imperial Palace
2024-11-10 -
Emperor’s Domination Chapter 6108: Killing The Three Immortals Online | tiknovel.com
2024-11-20 -
Journey To Become A True God Chapter 1988 Fang Miyu in big trouble
2024-11-21 -
Unrivaled Medicine God Chapter 2901 - Suppressing a City, Entire Army Sudden Raid!
2024-11-20
