

OpenAI科学家造出婴儿Llama2!GPT-4辅助写500行纯C代码揽1.6k星_tiknovel-最新最全的nft,web3,AI技术资讯技术社区
OpenAI科学家造出婴儿Llama2!GPT-4辅助写500行纯C代码揽1.6k星
OpenAI科学家Karpathy用了一个周末时间打造出明星项目Llama2.c。他借助GPT-4辅助,仅用500行C语言代码实现对Llama 2 baby模型的推理。
你有没有想过仅用C语言去推理一个Llama 2的baby模型?
没有?现在就能做到了!
就在刚刚过去的这个周末,OpenAI科学家Andrej Karpathy做了一个非常有趣的项目——llama2.c。
项目灵感正是来自于之前的明星项目——llama.cpp
首先,在PyTorch中训练一个较小的Llama 2模型。
然后,用500行代码在纯C环境下进行推理,并且无需任何依赖项。
最后得到的预训练模型(基于tinyStories),可以在MacBook Air M1 CPU上用fp32以每秒18个token的速度生成故事样本。

llama2.c一经发布,就在GitHub上速揽1.6k星,并且还在快速攀升中。

项目地址:https://github.com/karpathy/llama2.c
顺便,Karpathy还表示:「感谢GPT-4对我生疏的C语言提供帮助!」

英伟达科学家Jim Fan称,GPT-4帮助Karpathy用C语言「养」了一只baby Llama!太了不起了!

网友也表示,使用GPT-4构建llama2.c,堪称是终极跨界。

纯C语言推理Llama 2
可能Karpathy没想到,这个llama2.c项目的潜力是如此巨大。
令人惊讶的是,你可以在单线程的CPU上以fp32的交互速率对这些较小(O(~10MB))的模型进行推理。
不过,我还没尝试过使用最小的Meta LLama2检查点(7B),预计速度会很慢。


Karpathy表示,在较窄的领域(比如,故事)中,人们可以使用更小的Transformer来做有趣的事情。
因此,这个简单的纯C语言实现还是很实用的,尤其是它还可以进行移植。

紧接着,他又使用-O3编译,将MacBook Air M1上的每秒处理token数tok/s从18增加到了98。
对于使用这样简单的方法,并能够以较高的交互速率运行相当大小的模型(几千万参数),Karpathy表示非常幸兴奋——
「看来,我现在必须训练一个更大的模型了。」

事实证明,我原来的检查点用编译-O3在MacBook Air M1上运行_way_(100 tok/s)的速度比我预期的要快,所以我现在正在训练一个更大的44M模型,它应该仍然以交互方式运行。也许7B Llama模型触手可及。
代码开源
目前,llama2.c的代码已经开源。
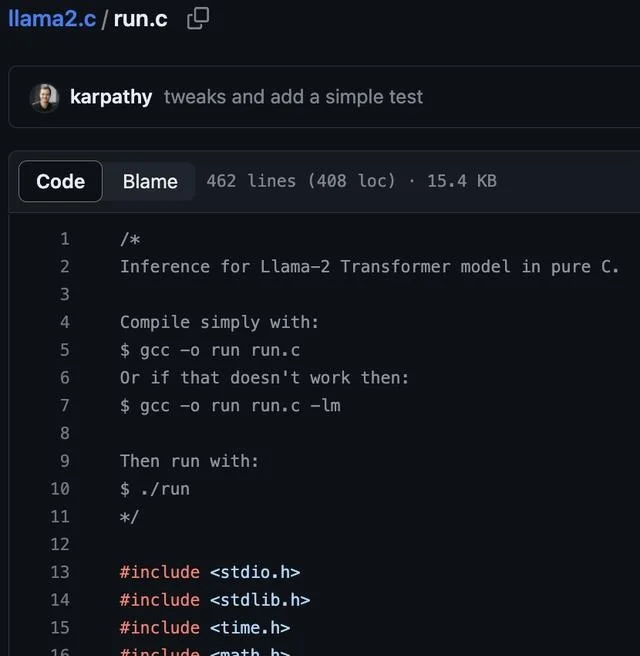
利用这段代码,你可以在PyTorch中从头开始训练Llama 2 LLM架构,然后将权重保存为原始二进制文件,并加载到一个约500行C文件(run. c)中。目前,该文件使用fp32对模型进行推理。
在云Linux开发环境中,Karpathy用一个维度为288、6层、6头的模型(约1500万参数)在fp32下以约100 tok/s的速度进行推理,而这也与M1 MacBook Air上的运行情况大致相同。
感受魔力
在C中运行一个baby Llama 2模型前,首先需要一个模型检查点。
对此,你可以下载在TinyStories数据集上训练的这个15M参数模型(约58MB),并将其放入默认检查点目录out:
wget https://karpathy.ai/llama2c/model.bin -P out
然后,编译并运行C代码:
gcc -O3 -o run run.c -lm./run out/model.bin
可以看到,这只是对原始token进行了流式处理。想要读取的话,就需要将其转换为文本。
遗憾的是,现在只能通过一个简单的Python函数装饰器来实现翻译(30行代码):
pip install sentencepiecepython run_wrap.py
在M1 MacBook Air上,它的运行速度约为每秒100个token,对于超级简单的fp32单线程C代码来说,效果还不错。
示例输出:
Once upon a time, there was a boy named Timmy. Timmy loved to play sports with his friends. He was very good at throwing and catching balls. One day, Timmy's mom gave him a new shirt to wear to a party. Timmy thought it was impressive and asked his mom to explain what a shirt could be for. "A shirt is like a special suit for a basketball game," his mom said. Timmy was happy to hear that and put on his new shirt. He felt like a soldier going to the army and shouting. From that day on, Timmy wore his new shirt every time he played sports with his friends at the party. Once upon a time, there was a little girl named Lily. She loved to play outside with her friends. One day, Lily and her friend Emma were playing with a ball. Emma threw the ball too hard and it hit Lily's face. Lily felt embarrassed and didn't want to play anymore. Emma asked Lily what was wrong, and Lily told her about her memory. Emma told Lily that she was embarrassed because she had thrown the ball too hard. Lily felt bad achieved tok/s: 98.746993347843922
从前,有一个叫Timmy的男孩。Timmy喜欢和他的朋友们一起运动。他非常擅长扔球和接球。一天,Timmy的妈妈给了他一件新衬衫,让他穿去参加一个聚会。Timmy觉得这件衬衫很棒,便问妈妈它有没有什么特别的用途。「衬衫就像篮球比赛时的特殊套装,」他妈妈说。Timmy听了很高兴,于是穿上了这件新衬衫。他感觉自己像个士兵要去参军一样,大声呐喊。从那天起,每次在聚会上和朋友们一起运动时,Timmy都会穿着这件新衬衫。从前,有一个叫Lily的小女孩。她喜欢和她的朋友在外面玩。一天,Lily和她的朋友Emma正在玩球。Emma把球扔得太用力了,结果打到了Lily的脸上。Lily觉得很尴尬,不想再玩了。Emma问Lily怎么了,Lily告诉她她的记忆。Emma告诉Lily,她很尴尬,因为她把球扔得太用力了。Lily觉得很糟糕。Tok/s:98.746993347843922
使用指南
理论上应该可以加载Meta发布的权重,但即使是最小的7B模型,使用这个简单的单线程C程序来进行推理,速度估计快不了。
所以在这个repo中,我们专注于更窄的应用领域,并从头开始训练相同的架构。
首先,下载并预分词一些源数据集,例如TinyStories:
python tinystories.py downloadpython tinystories.py pretokenize
然后,训练模型:
python train.py
更多特殊启动和超参数覆盖的信息,请查看train.py脚本。Karpathy预计简单的超参数探索应该可以得到更好的模型,因此并没有对其进行调整。
如果想跳过模型训练,只需下载Karpathy的预训练模型并将其保存到out目录中,就可以进行简单的演示了:
wget https://karpathy.ai/llama2c/model.bin -P out
一旦有了model.bin文件,就可以在C中进行推理。
首先,编译C代码:
gcc -O3 -o run run.c -lm
然后,运行:
./run out/model.bin
注意,这里输出的只是SentencePiece token。要将token解码为文本,还需利用一个简单的装饰器来运行这个脚本:
python run_wrap.py
此外,也可以运行PyTorch推理脚本进行比较(将model.ckpt添加到/out目录中):
python sample.py
这将得到相同的结果。更详细的测试将在test_all.py中进行,运行方式如下:
$ pytest
目前,你需要两个文件来进行测试或采样:model.bin文件和之前进行PyTorch训练的model.ckpt文件。
(论如何在不下载200MB数据的情况下运行测试。)
待办事项
- 为什么SentencePiece无法正确地迭代解码?
- 希望能够删除run_wrap.py文件,直接使用C代码转换为字符串
-是否支持多查询的功能?对于在CPU上运行的较小模型似乎用处不大?
- 计划支持超过max_seq_len步数的推理,必须考虑kv缓存的情况
- 为什么在我的A100 40GB GPU上进行训练时,MFU如此之低(只有约10%)?
- 使用DDP时出现了torch.compile和wandb的奇怪错误
- 增加更好的测试来减少yolo
网友热议
借着llama2.c热乎劲儿,网友将llama2编译成Emscripten,并在网页上运行。
他使用Emscripten进行了编译,并修改了代码,以在每次渲染时预测一个token。网页自动加载了50MB的模型数据。


此外,他还增添了去token化的支持。

还有网友表示,基于llama.cpp的成功,这个行业似乎正朝着为每个发布的模型提供单独源代码的方向发展,而不是像pytorch/tenorflow/onnxruntime这样的通用框架?

llama2.c的意义在何处?
网友举了一个生动的例子,创建一个关于一个有100人的小岛的电脑游戏,每个人都有意识,llama2. c是他们的大脑。然后你可以模拟一千年的历史,看看会发生什么。
Prev Chapter:开源,会是对手打败 ChatGPT 的绝招吗?
Next Chapter:微软将向日本政府提供ChatGPT技术 用于文书处理、统计数据
评论区
- 这篇文章还没有收到评论,赶紧来抢沙发吧~
【随机内容】

