

7万本盗版书,是“ChatGPT们”变聪明的秘密_tiknovel-最新最全的nft,web3,AI技术资讯技术社区
7万本盗版书,是“ChatGPT们”变聪明的秘密
「实锤」终于来了。
今年 7 月,OpenAI 和 Meta 被三位美国作家 Sarah Silverman、Christopher Golden 和 Richard Kadrey 起诉,称两家公司在未经作者同意的情况下,把他们的书用作素材训练大模型。
证据?
在 OpenAI 案件里,原告们输入提示词后,ChatGPT 能够总结出他们的书的内容。

演员、作者 Sarah Silverman 和她的自传,输入提示词后,OpenAI 可呈现该书总结,图片来自 Vulture
在 Meta 案件中,Meta 大模型 LLaMA 的论文里就写着,它训练数据包括一个由 EleutherAI 整理的、名为「ThePile」的素材。
「ThePile」中又包含了一个名为「Books3」的数据集,它的内容正是线上盗版图书资源库 Bibliotik 的数据。
当时,原告们提出的证据还相对「间接」。
直到现在,作家和程序员 Alex Reisner 正式揭露,Meta 的大模型背后到底都盗用了哪些作家的什么书籍。
让人意外的是,这些「证据」其实一直都放在明面,但却一直没有被揭开,这是为什么?
甚至,侵权素材的制造者,还一直坚持说这是一件「正义」的事。
17 万本盗版图书

图片来自 Interesting Engineering
Alex Reisner 的「大项目」缘起于好奇心:
作为一名作家和电脑程序员,我一直很好奇生成式 AI 系统是用什么类型书籍来训练的。
今年夏天,Reisner 开始在 GitHub 和 Hugging Face 等社区找寻答案,最终找上了我们在上文提起的开源数据集「ThePile」。
然而,下载到「ThePile」,并不意味着你就能知道「Books3」里都有什么书。
「ThePile」有 800G,大得一般文本编辑器根本没法看。
Reisner 写了一系列程序才能得以从中提取「Books3」的信息。

图片来自 Unsplash
没想到的是,提取出来的信息里,并没有任何带有「书名」「作者名」等标签的数据,一切都只是「文本」。
于是,Reisner 又另外写了一个程序去提取数据中的 ISBN 编号(国际标准书号),并将这些数据和其他线上图书数据库进行比对,以辨别出「Books3」中被收录的具体书籍。
最后,这一步找出了 19 万个 ISBN 编码,识别出 17 万个对应书名,另外 2 万个编码则无法找到对应书名。

图片来自 Medium
这些书里,大约有 1/3 是虚构作品,2/3 是非虚构作品,来自于大大小小不同的出版社。
是的,在这些被识别出的书里,也包括了文章开篇提到对 OpenAI 和 Meta 提出诉讼的三位作家的书籍。
因此,这可以说是 Meta 的 LLaMA 以盗版书作为训练素材非常直接的证据的了。
此外,我们还能在其中看到《我的天才女友》作者埃莱娜·费兰特、《女仆的故事》作者玛格丽特·阿特伍德、史蒂芬 · 金、村上春树、著名饮食类作家迈克尔·波伦、惊悚小说作家詹姆斯·帕特森等人的众多作品。

玛格丽特·阿特伍德等八千多名作家也写了联名信,要求 AI 公司需要获得作家授权才可将书籍用作训练材料,图片来自《独立报》
除了著名作家的书籍以外,Reisner 还在「Books3」里找到了「科学教」创始人罗恩·哈伯德的 102 本低俗小说、90 本信奉「年轻地球创造论」的牧师约翰·F·迈克阿瑟的书,以及「外星人创造论」支持者埃里希·冯·丹尼肯的多部作品。
Reisner 在《大西洋月刊》的文章中指出,虽然「Books3」数据集在 AI 社区以外认知度不高,但在圈里挺受欢迎的,「可以下载,但要找到有点难度,想要浏览和分析也同样具有挑战性」。
像 Reisner 这样大费周章写程序来分析比对,还精心撰文在大众媒体上发布,还是首次。
与此同时,AI 圈对「Books3」也有心照不宣的维护。
用「Books3」创造者的话来说 —— 它是确保生成式 AI 发展不会被大公司垄断的重要资源。
「盗火者」还是「盗贼」?

图片来自《大西洋月刊》
如果我们不需要像 Books3 这样的东西的确会更好。
但情况是,如果没有 Books3,只有 OpenAI 可以做到他们正在做的事情。
「Books3」的创造者,独立开发者 Shawn Presser 对 Reisner 说道。
Presser 一开始做 Books3,就是为了给所有开发者「OpenAI 级别的训练数据」。
2020 年,Presser 下载了一份 Bibliotik 的副本,再改写了黑客 Aaron Swartz 十多年前写下的程序,将所有 ePub 格式的图书转换成纯文本 —— 一种更合适大模型使用的格式。

至于数据集中部分书的版权信息出现缺失,Presser 称那是转换造成的意外结果,并非自己刻意为之。
而「Books3」这个名字,也是呼应了 OpenAI 之前提及的「Books1」和「Books2」。
在 2020 年的时候,OpenAI 的论文指出,GPT-3 的训练数据中包括两个基于互联网的书籍数据合集。
人们从其体积推测,OpenAI 的「Books1」数据来自于「古登堡计划(Project Gutenberg)」—— 专门收集版权已过期的图书资源的项目。

「Books2」的内容是什么则一直无人知晓,有人从其体积猜是类似 Bibliotik 或 Libgen 的线上盗版图书库的数据。
当然,除了书籍的数据外,GPT-3 当时还用了其他数据,如维基百科和其他从网络上抓取下来的文字信息。
这也是为什么 EleutherAI 整合的「ThePile」里也同样包含了大量其他数据,如维基百科、YouTube 视频的字幕、欧洲议会的文件和速记等等。
即便如此,相比之下,书籍的高质量文本仍然显得很重要。
Meta 曾表示,最开始的 LlaMA-65B 大模型表现没有其他好,主要是因为它「所使用的书籍以及学术论文数量有限」。
MIT 和康奈尔大学合作的论文也指出,书籍在大模型训练数据中「对下游表现有最强正面效果的」。
所以我们会在 Meta 后来推出的 LlaMA 2 训练数据中看到「ThePile」和其中的「Books3」。

图片来自 CNN
这也是为什么,当 Books3 最近因丹麦反盗版组织 Rights Alliance 投诉侵权而被下架时,Presser 感到愤慨不平。
在他看来,所有牟利的大公司在私底下都把侵权内容拿来训练自己的大模型,但又因为他们不公开其训练数据,因此没人能告得了他们。
而 Books3 被下架,却正是因为他希望让大模型更开放和有更高透明度而主动公开数据来源。
Presser 强调,我们不能让财大气粗的大公司垄断这项在重塑我们文化的重要技术,而是要让所有人都有资源去建立自己的大模型:
我的目标要让所有人都能(建造这些大模型)。
除非书籍的作者有方法能把 ChatGPT 拉下线,或者告到他们关门,否则让你和我都能建造自己的 ChatGPT 是非常必要的。
正如在 90 年代的时候,去保证任何人都能设立自己的网站一样重要。
至于把 ChatGPT 告到下线,也不是完全没有可能。
人人都在告 AI 巨头

OpenAI 不再「Open」也不透明,图片来自 Politico
明星作家发起的官司也许引来更多关注,但拥有把 ChatGPT 告到「重造」的潜力的,却是传统新闻媒体。
上周,NPR 报道援引知情人士消息称《纽约时报》正在考虑起诉 OpenAI。
在过去几周里,《纽约时报》都在和 OpenAI 就授权协议谈判。然而,谈判进展似乎不太顺利,以至于《纽约时报》都开始考虑就侵权告 OpenAI 了。
报道称,联邦版权法规定,违法者每项「蓄意」侵权行为最高可罚 15 万美元,再结合《纽约时报》的文章数量,这个金额叠加起来「对于一家公司来说可能是致命的」。
除此以外,如果法官判定 OpenAI 的确非法拿了《纽约时报》的文章来训练大模型,法院也可以命令 OpenAI 销毁 ChatGPT 的数据集,强制它仅用已获得授权的作品来重新训练和创造 ChatGPT。

图片来自 BrookField
无论是原告是《纽约时报》还是书籍作家,这些官司(或潜在官司)能否胜诉,关键都在于 AI 巨头们是否能把这些信息的使用说成「合理使用」 —— 即在特定情况下,可允许不经许可去使用特定作品,譬如教学、评论、研究和报道等。
支持「合理使用」的人有两个论点:
生成式 AI 并不会重现它们用于训练的书籍本身,而是创造新内容;
那些新内容并不会损害原本作品的市场。
纽约大学科技法律与政策诊所的负责人 Jason Schultz 称,在图书被盗用方面,这个论据还挺有力的。
但《纽约时报》的律师则坚持,OpenAI 对报纸文章的使用并不合乎「合理使用」。
假如用户能通过 AI 聊天机器人,获取文章中提及的新闻事件描述,用户可能就不会再去找文章阅读了,因此有可能会成为新闻文章的替代品,影响了原有市场。
法律博主樊百乐指出,知识产权法并非一成不变,但其核心却很坚定 —— 繁荣创作市场。
如果连估值数百亿美元的 AI 公司,都可以不付一分版权费,免费把作家耗费数年心血创作的作品拿去牟利,甚至盗用这些书去训练出意图替代作家的工具,这对创作者而言无疑是致命打击。
Presser 谈论到的「数据不公平」问题,也不应是侵犯创作者权利的借口。
版权问题终究会是决定 AI 能走多远的其中一个关键因素。
范德堡大学知识产权项目联席主任 Daniel Gervais 认为:
版权法是一把悬在 AI 公司头上的利剑,除非它们想出如何协商解决方案,否则这把剑未来几年都会悬在它们头上。
这一切只是新阶段的开始。
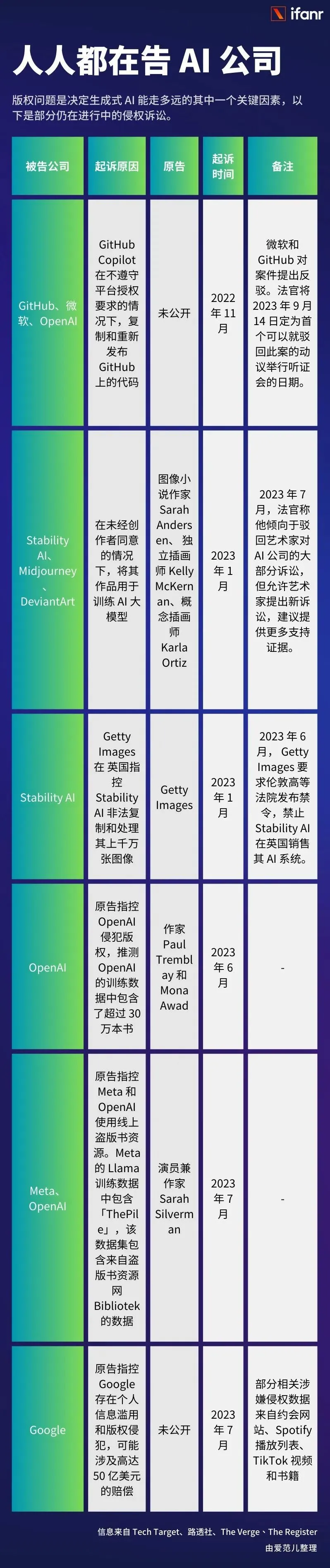
最后,我们整理了部分仍在进行中的 AI 公司侵权诉讼,以供参考。
Prev Chapter:OpenAI不藏着了,开放微调功能,不用其他工具就能搞一个你自己的ChatGPT
Next Chapter:ChatGPT给出的癌症治疗方案充满错误信息
评论区
- 这篇文章还没有收到评论,赶紧来抢沙发吧~
【随机内容】

