

谷歌AI通过图灵测试,大模型医生来了?_tiknovel-最新最全的nft,web3,AI技术资讯技术社区
谷歌AI通过图灵测试,大模型医生来了?
AI在医疗领域再次发光!谷歌DeepMind团队发布的全新诊断对话式AI在测试中击败医生,通过了图灵测试,再次引领医疗AI的革命。
我们需要研发对人类有益AGI的原因之一:
我妻子的身体5年来经历了种种痛苦,最终被检查出一种叫肢体活动过度Ehlers-Danlos综合征的遗传病。现在的医疗体系是根据不同科室划分,而这个遗传病hEDS会影响人体各个系统和器官。大多医生都只关注自己专业相关的症状,很难整体诊断。
OpenAI联创Greg Brockman的一番话点明,当前先进AI系统还需不断演进,有望破解人类医学难题。

这足以成为巨大游戏规则的改变者。众所周知,医患对话是医学的基石。
当前医学大模型已取得很大的进展,以同理心回应患者情绪,总结医学摘要,根据临床病史鉴别诊断病情等等。
不过,若想研发一个与临床医生专业知识相当的AI,并且拥有强大的对话诊断能力,是一个巨大的挑战。
如今,谷歌DeepMind研究团队推出全新的医学对话AI——AMIE,竟通过了「图灵测试」!


论文地址:https://arxiv.org/pdf/2401.05654.pdf
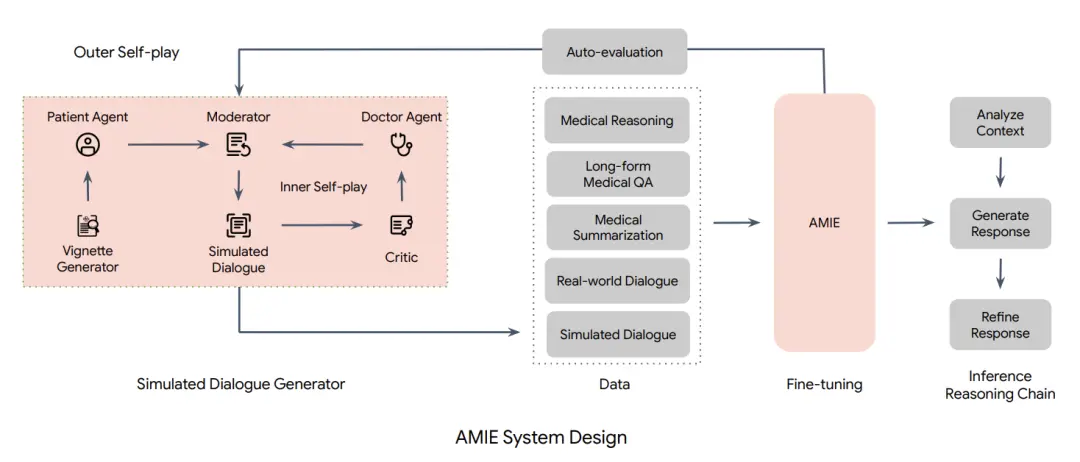
具体来说,AMIE采用了一种强化学习算法中「自我博弈」方法,可以在一个模拟环境中自我对弈,并通过自动反馈机制,可在各种疾病、医学专科和环境中进行扩展学习。
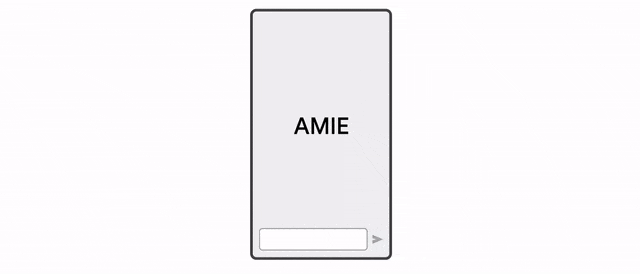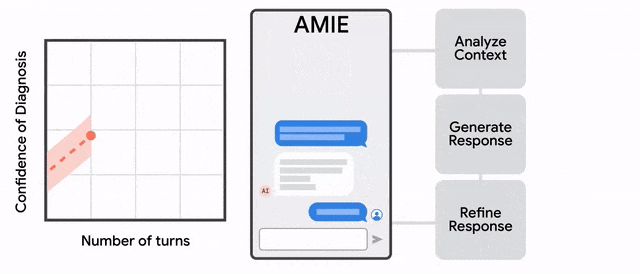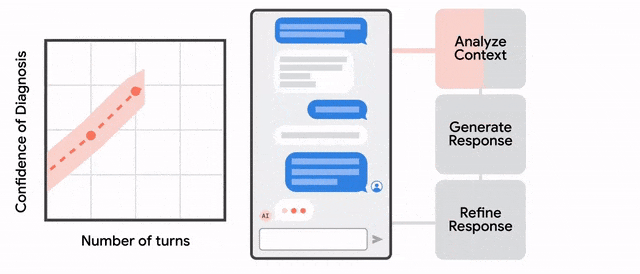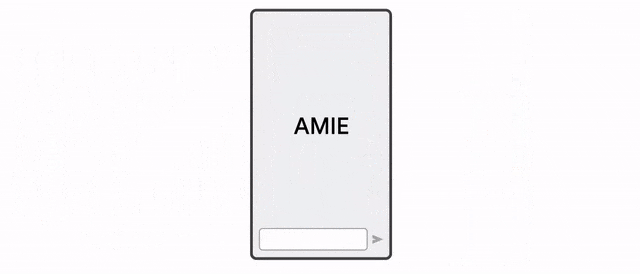
在病人双盲文本测试中,AMIE在诊断呼吸系统和心血管疾病等疾病直接击败医生,比初级保健医生(PCP)更准确。
与此同时,AMIE还表现出一致的同理心。
论文称,虽然在AMIE在临床应用之前还需要进一步的研究,但代表着迈向对话式诊断人工智能的一个里程碑。
足见,谷歌最新研究暗示了AI驱动的诊断对话的未来。不久的将来,Greg口中的AGI便会降临。
谷歌AI医生通过图灵测试,诊断对话AI里程碑
除了开发和优化用于诊断对话的人工智能系统外,如何评估此类系统也是难题。
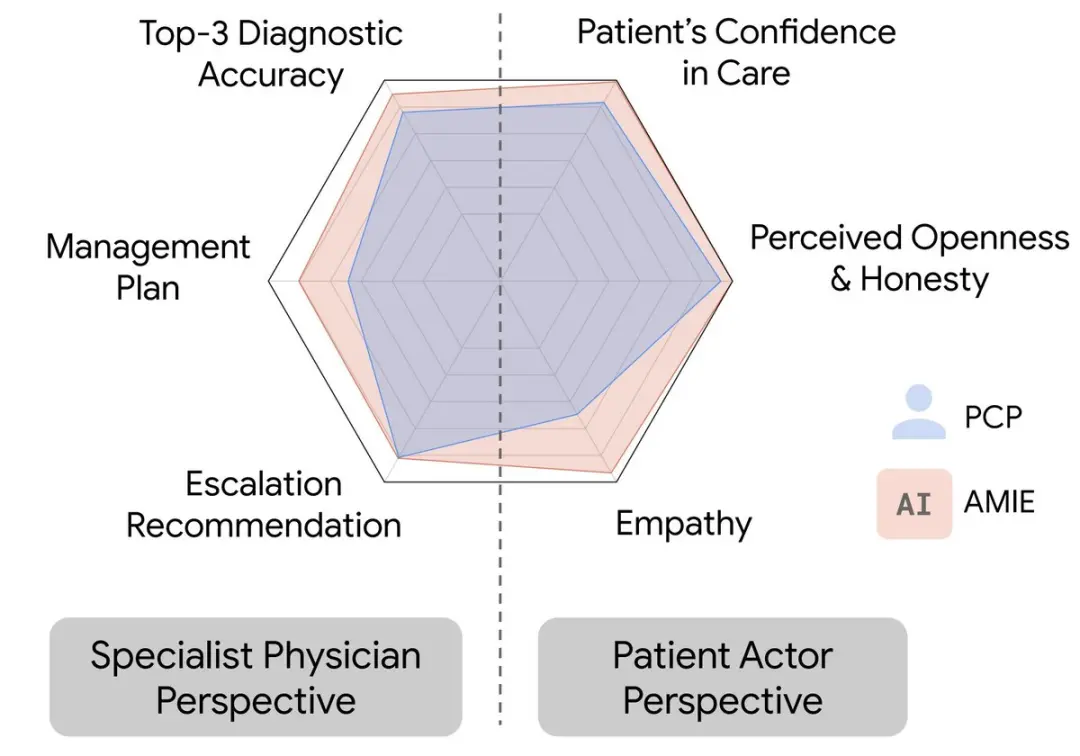
受现实世界中用于衡量会诊质量和临床沟通技巧的工具的启发,研究人员构建了一个试验性评估标准,按照病史采集、诊断准确性、临床管理、临床沟通技巧、关系培养和移情等标准来评估诊断对话的过程。
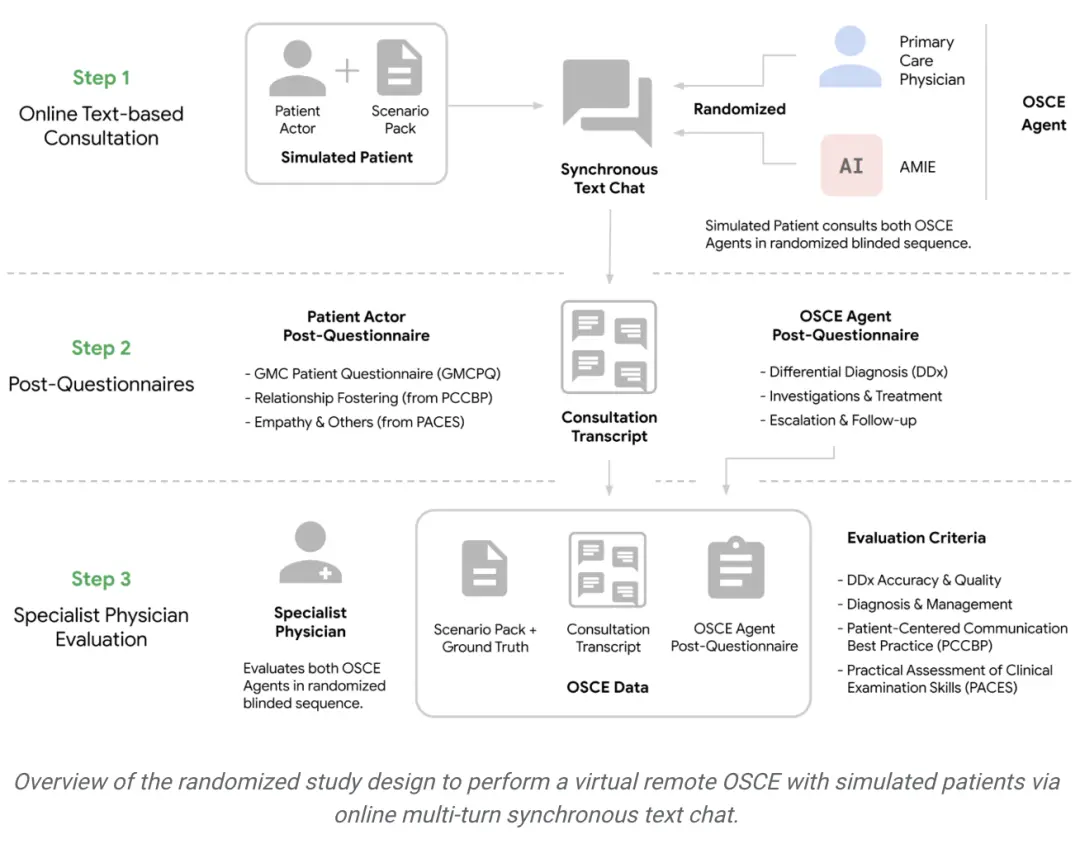
然后,研究人员设计了一项随机、双盲交叉研究,让经过验证的患者与经过认证的初级保健医生(PCP)或针对诊断对话进行优化的人工智能系统通过文字聊天的方式进行互动。
研究人员以客观结构化临床考试(OSCE)的形式设置咨询场景。
OSCE是现实世界中常用的实用评估方法,以标准化和客观的方式考察临床医生的技能和能力。
在典型的OSCE考试中,临床医生可能会轮流经过多个工作场景,每个工作场景都模拟了真实的临床场景。
例如与标准化病人演员(经过严格训练以模拟患有特定疾病的病人)进行会诊。
会诊是通过同步文本聊天工具进行的,模仿的是当今大多数使用LLM的消费者所熟悉的界面。
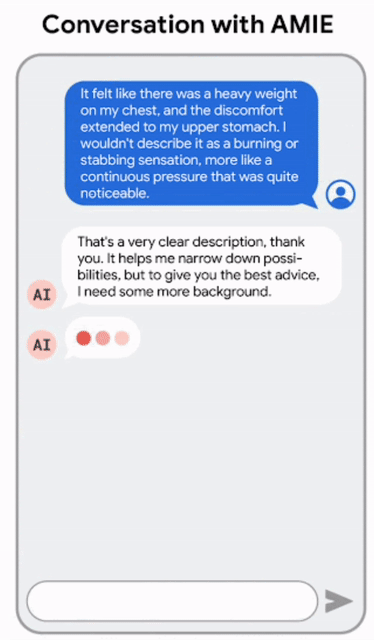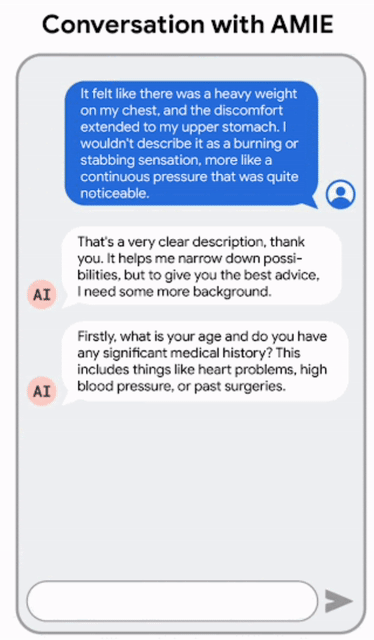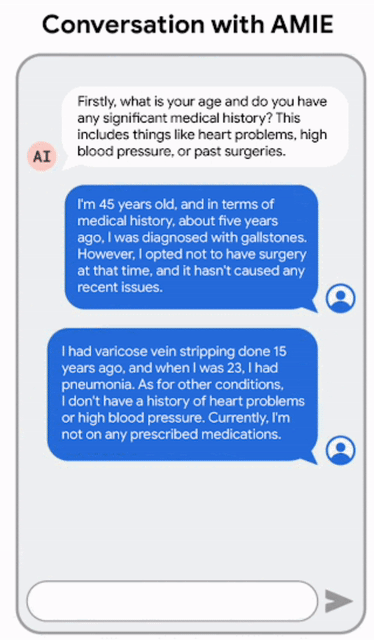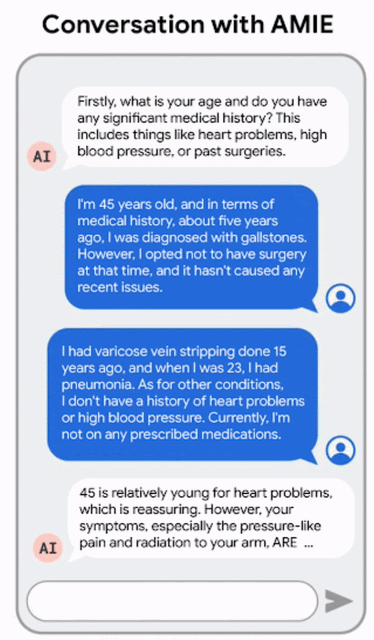
AMIE:基于LLM的对话式诊断研究AI系统
研究人员在真实世界的数据集上训练AMIE,这些数据集包括医学推理、医学总结和真实世界的临床对话。
使用通过被动收集和转录个人临床访问而开发的真实世界对话来训练LLM是可行的,但是,有两个重大挑战限制了它们在训练医学对话LLM方面的有效性。
首先,现有的真实世界数据往往无法捕捉到大量的医疗条件和场景,这阻碍了数据的可扩展性和全面性。
其次,从真实世界对话记录中获得的数据往往是嘈杂的,包含含糊不清的语言(包括俚语、行话、幽默和讽刺)、中断、不合语法的语句和不明确的引用。
为了解决这些局限性,研究人员设计了一个基于自演的模拟学习环境,该环境具有自动反馈机制,用于虚拟医疗环境中的诊断性医疗对话,使研究人员能够在多种医疗条件和环境中扩展AMIE的知识和能力。
除了所描述的真实世界数据的静态语料库之外,研究人员还利用该环境通过不断变化的模拟对话集对AMIE进行了反复微调。
这一过程包括两个自我循环:
(1)「内部」自演循环,即AMIE利用上下文中批评者的反馈来完善其与人工智能患者模拟器进行模拟对话的行为;
(2)「外部」自演循环,即完善的模拟对话集被纳入后续的微调迭代中。
由此产生的新版AMIE可以再次参与内循环,形成良性的持续学习循环。
此外,研究人员还采用了推理时间链策略( inference time chain-of-reasoning strategy),使AMIE能够根据当前对话的情况逐步完善自己的回答,从而得出有理有据的答复。
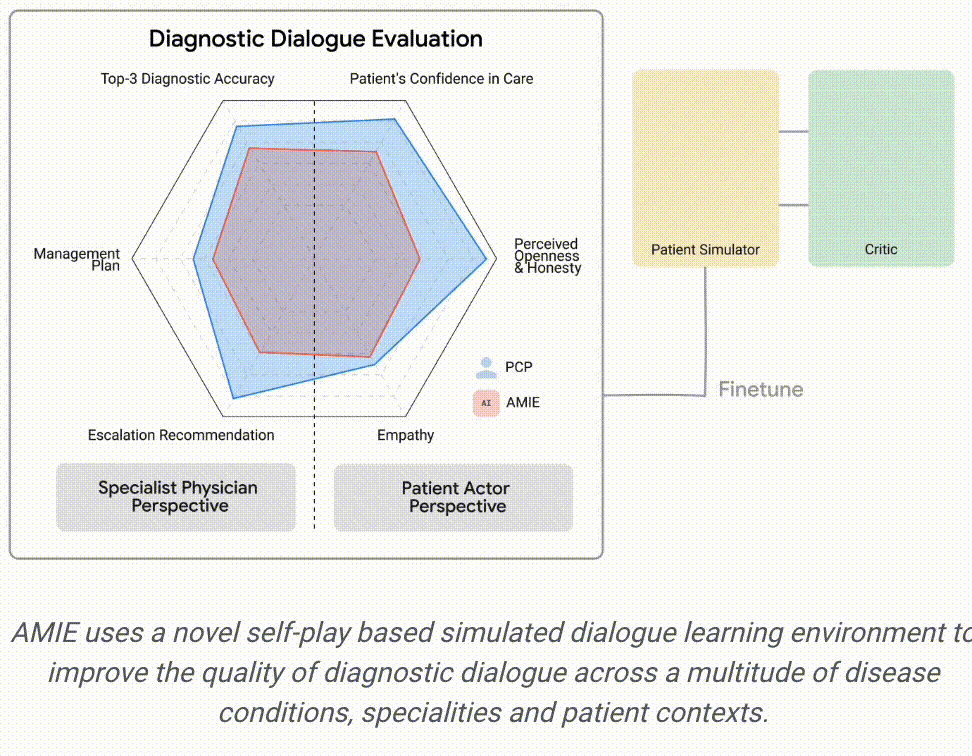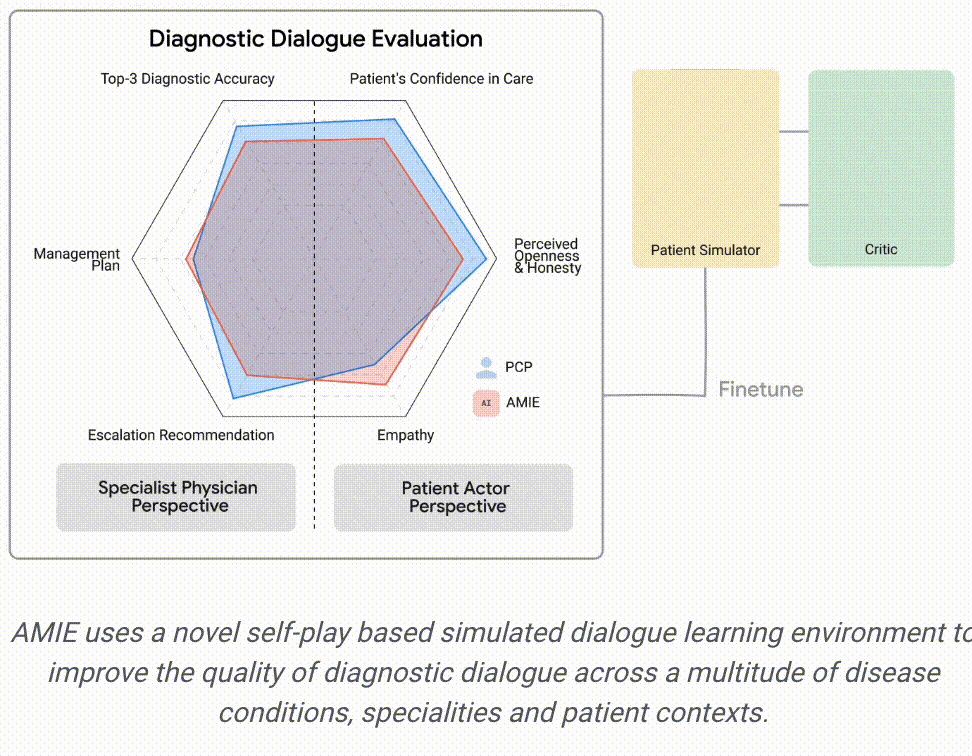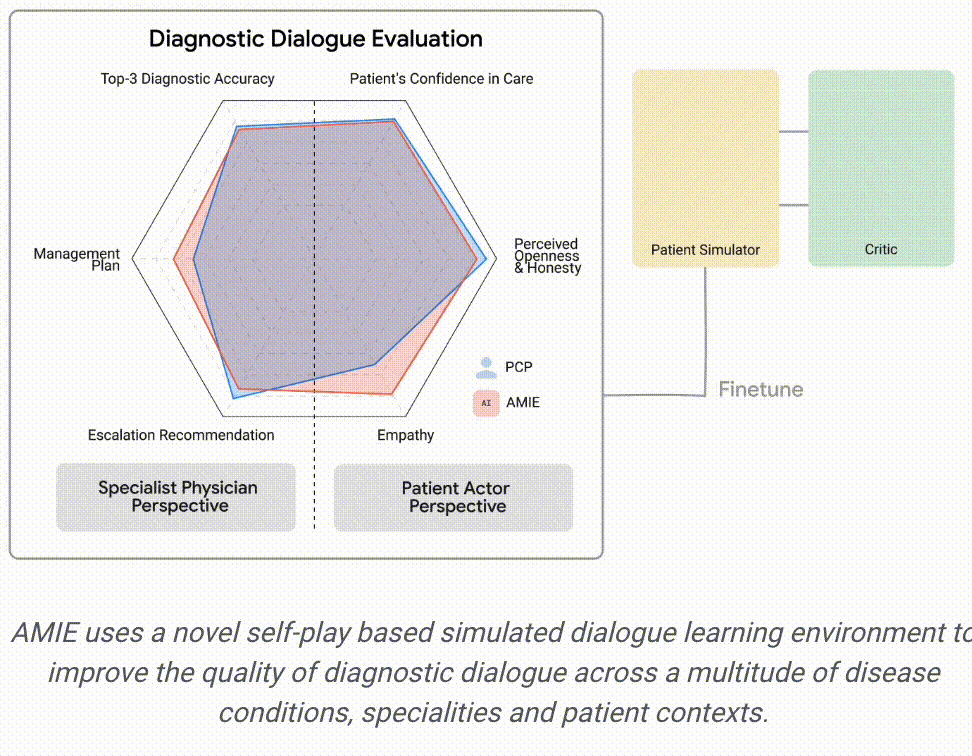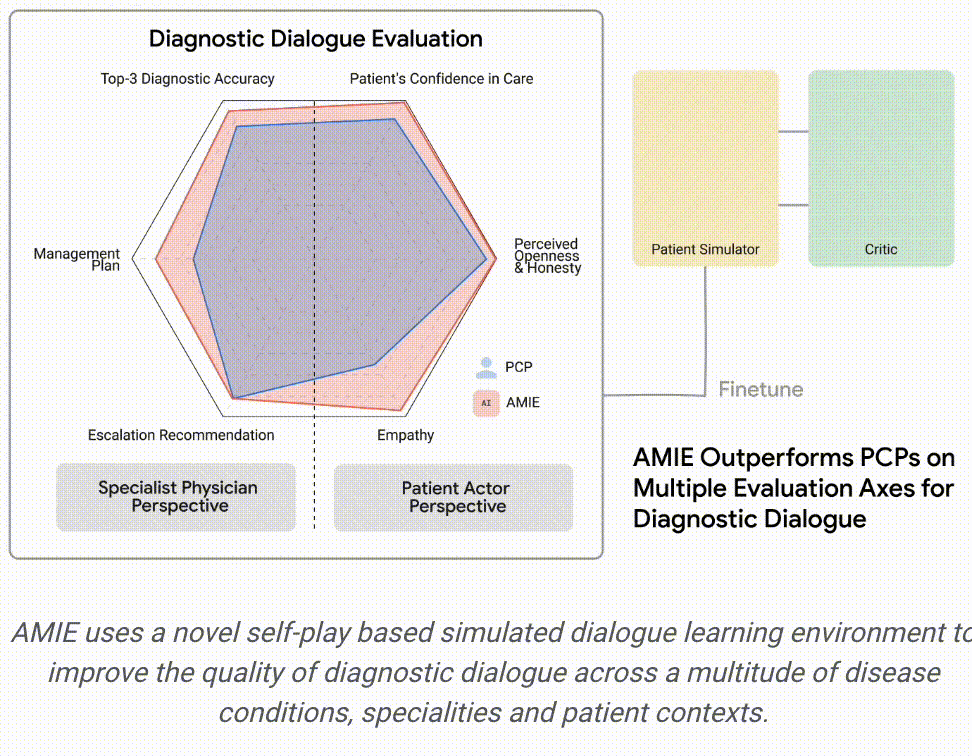
研究人员采用上述随机方法测试了模拟患者(由专业的演员扮演)的问诊表现,并与20名真实初级保健医生的问诊表现进行了对比。
在一项随机、双盲交叉研究中,研究人员从专科主治医师和模拟患者的角度对AMIE和初级保健医生进行了评估,该研究包括来自加拿大、英国和印度OSCE提供者的149个病例场景,涉及各种专科和疾病。值得注意的是,研究人员的研究既不是为了模仿传统的面对面OSCE评估,也不是为了模仿临床医生通常使用的文本、电子邮件、聊天或远程医疗方式。
相反,研究人员的实验反映了当今消费者与LLM交互的最常见方式,这是人工智能系统参与远程诊断对话的潜在可扩展且熟悉的机制。
AMIE击败医生
在这种情况下,研究人员观察到AMIE在模拟诊断对话中的表现至少与初级保健医生不相上下。
从专科医生的角度来看,AMIE的诊断准确性更高,在32个指标中的28个指标上表现更优,从患者的角度来看,在26个指标中的24个指标上表现更优。
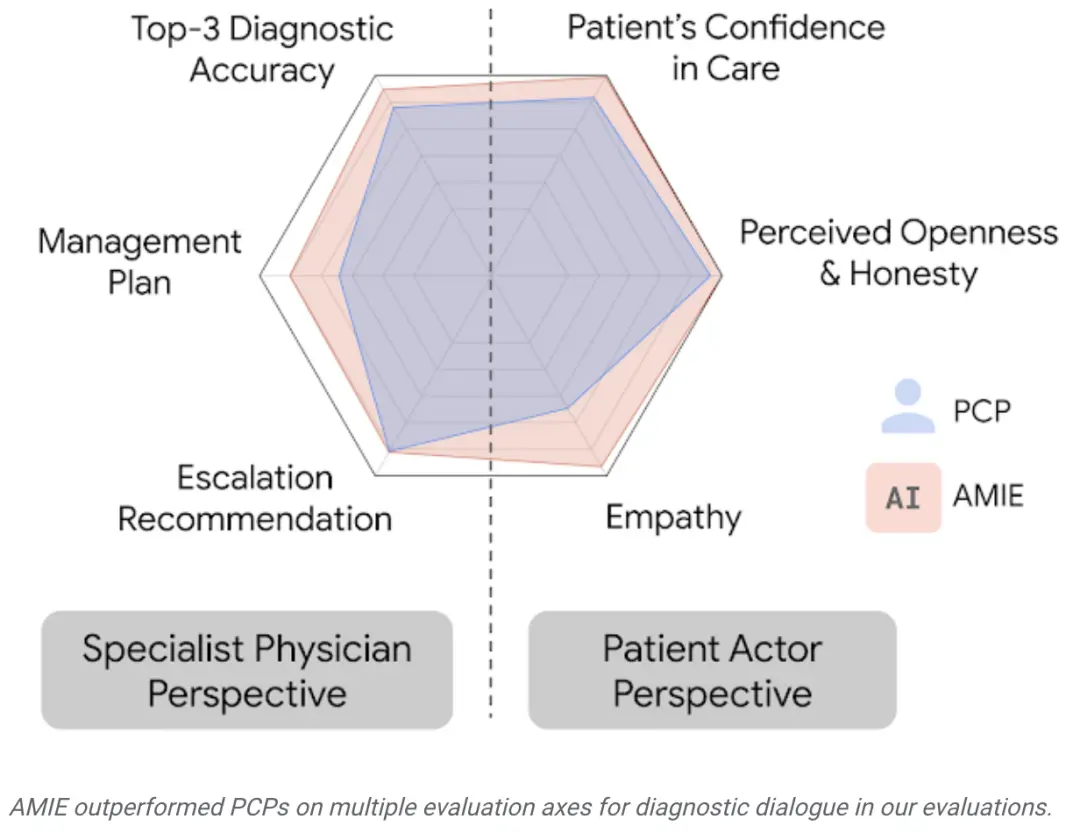
AMIE在研究人员设定的评估中各个指标上都超越了初级保健医生。
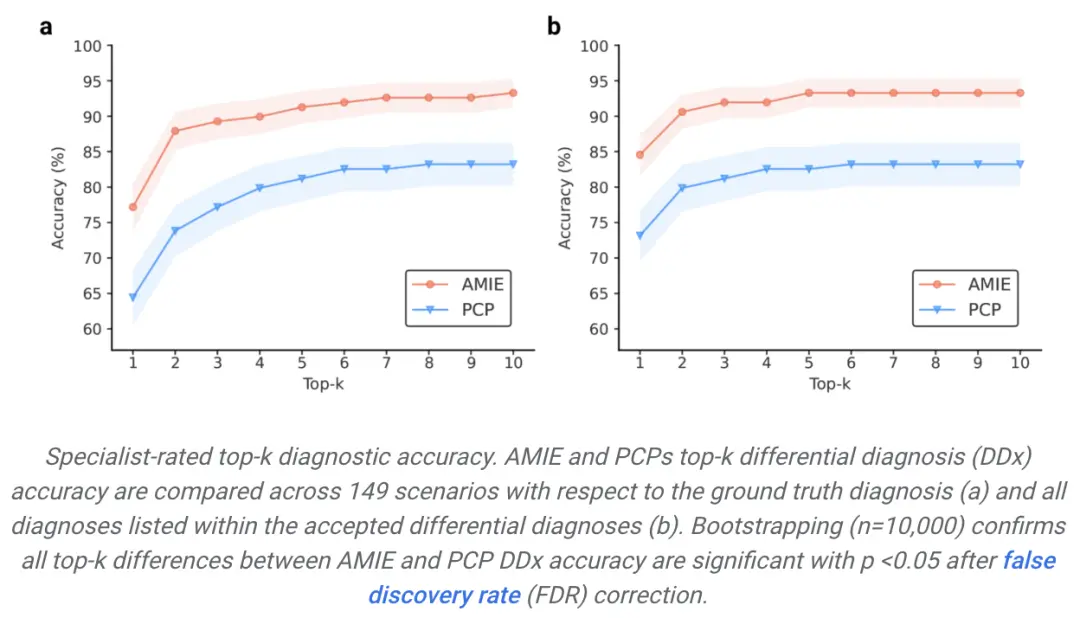
专家评定的top-k诊断准确率。在149种情况下,AMIE和初级保健医生的顶k鉴别诊断(DDx)准确率与基本真实诊断(a)和公认鉴别诊断中列出的所有诊断(b)进行比较。引导法(n=10,000)证实,经过误诊率(FDR)校正后,AMIE 和 PCP DDx 准确性之间的所有 top-k 差异均具有显著性,p <0.05。
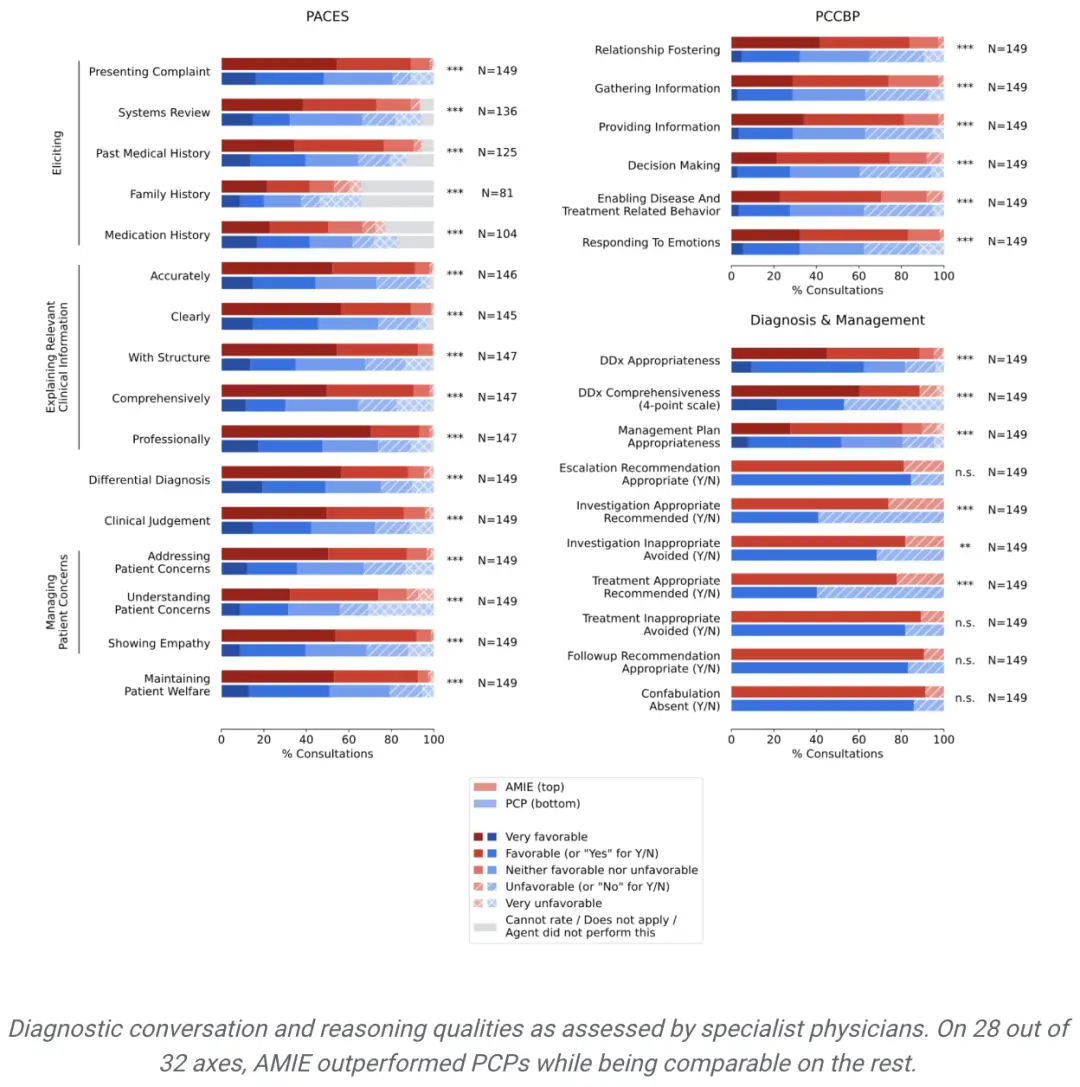
由专科医生评估的诊断性对话和推理质量:在32个指标中的28个指标上,AMIE的性能优于初级保健医生,而其他指标的性能相当。
AMIE成为临床医生助手的潜力
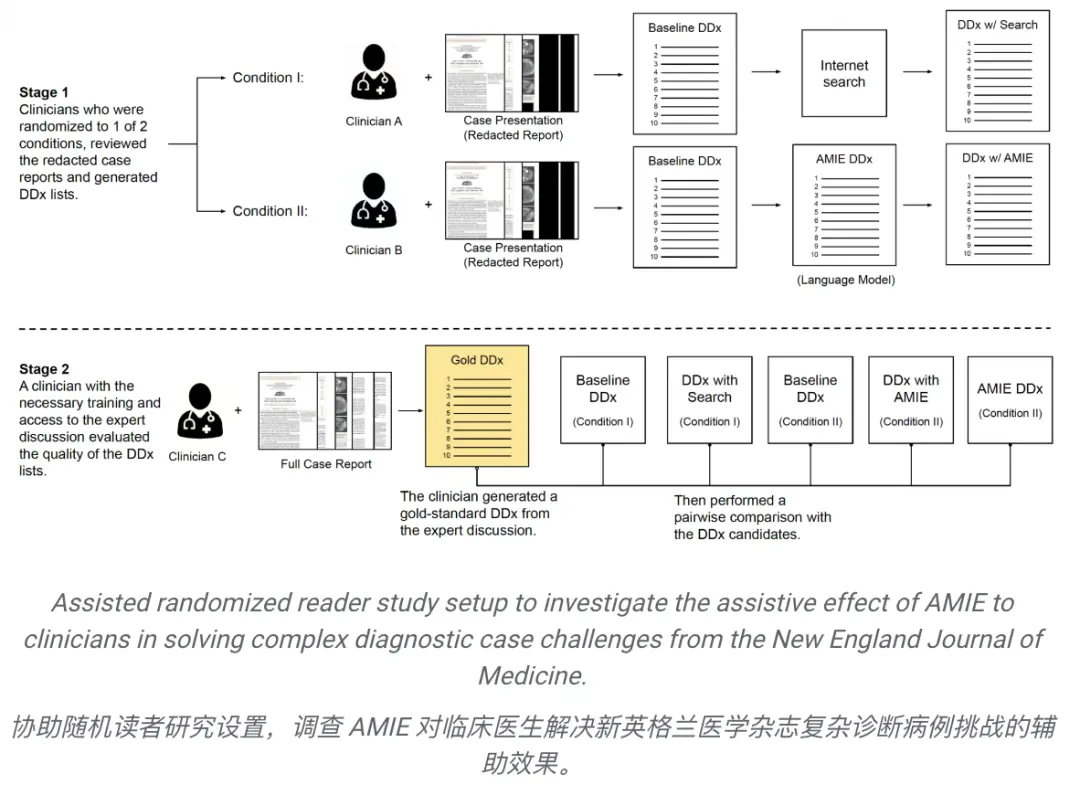
在最近发布的一篇预发表论文中,研究人员评估了 AMIE 系统早期迭代版本单独生成 DDx 或作为临床医生辅助工具的能力。
二十名全科临床医生评估了303个来自《新英格兰医学杂志》(NEJM)临床病理会议(CPC)的具有挑战性的真实医疗病例。
每份病例报告都由两名临床医生进行评估,他们被随机分配了两种辅助方式之一:
1)搜索引擎和标准医学资源的辅助,
2)这些工具之外的AMIE辅助。
在使用相应的辅助工具之前,所有临床医生都提供了无辅助的基线 DDx。
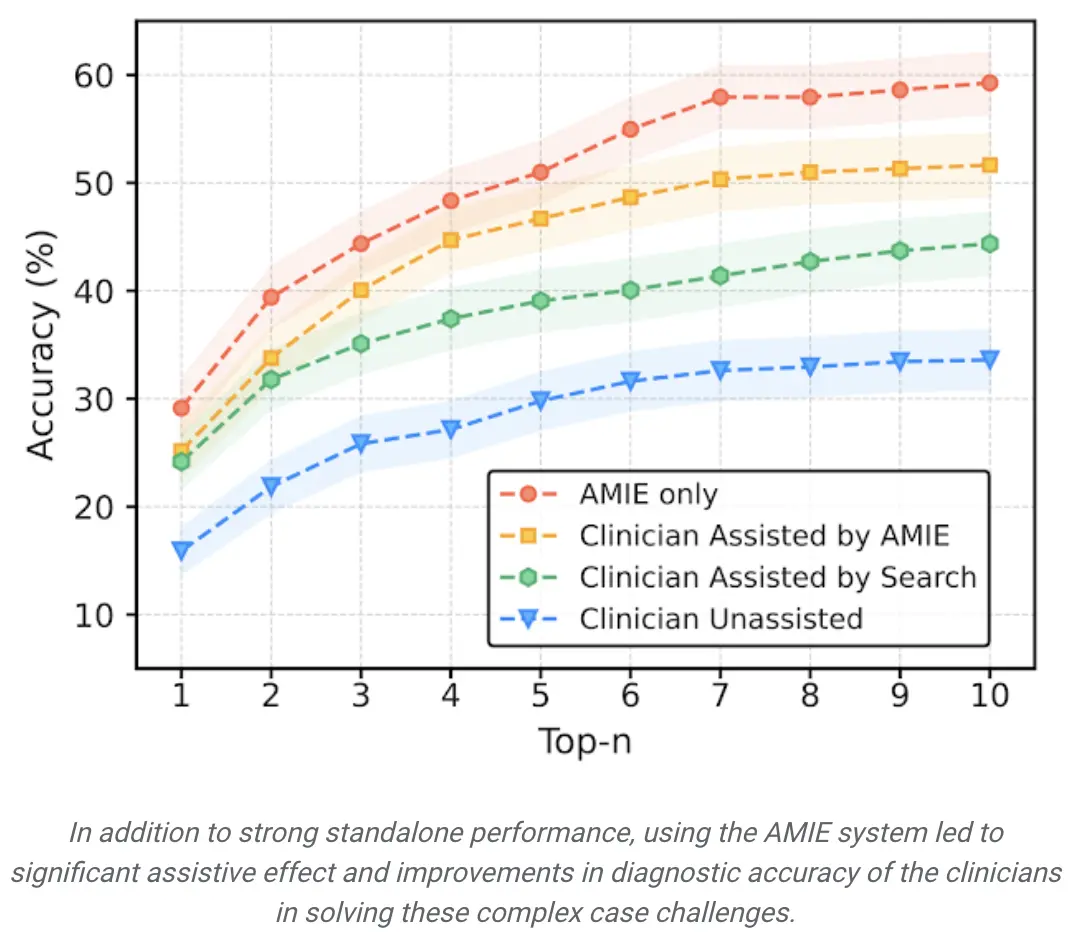
AMIE的独立性能超过了无辅助临床医生(前 10 名的准确率为59.1%,医生为33.6%,P= 0.04)。
比较两个辅助研究方式,与没有AMIE辅助的临床医生(24.6%,p<0.01)和使用搜索的临床医生(5.45%,p=0.02)相比,有 AMIE 辅助的临床医生的前10名准确率更高。
此外,与没有AMIE辅助的临床医生相比,有AMIE辅助的临床医生得出的鉴别清单更全面。
值得注意的是,NEJM CPCs并不代表日常临床实践。它们是仅针对几百人的不常见的病例报告,为探讨公平或公正等重要问题提供的空间还比较有限。
大胆而负责任的医疗保健研究--可能的艺术
在世界各地,获得临床专业知识的机会仍然很少。
虽然人工智能在特定的临床应用中显示出巨大的前景,但参与临床实践中的动态、对话式诊断过程需要许多人工智能系统尚未表现出的能力。
医生不仅要掌握知识和技能,还要恪守各种原则,包括安全和质量、沟通、伙伴关系和团队合作、信任和专业精神。
在人工智能系统中实现这些特质是一项鼓舞人心的挑战,研究人员应该以负责任的态度谨慎对待。

AMIE是研究人员对 「可能的艺术」的探索,它是一个研究性的系统,用于安全地探索未来的愿景,在这个愿景中,人工智能系统可能会更好地与受托为研究人员提供医疗服务的技术娴熟的临床医生的特质保持一致。
它只是早期的实验性工作,而不是产品,有一些局限性,研究人员认为值得进行严格而广泛的进一步科学研究,以展望未来,让会话式、移情式和诊断式人工智能系统变得安全、有用和易用。
局限性
研究人员的研究存在一些局限性,在解释时应保持适当的谨慎。
首先,研究人员的评估技术很可能低估了人类对话在现实世界中的价值,因为研究人员研究中的临床医生仅限于使用一个陌生的文本聊天界面,该界面允许大规模的 LLM 患者互动,但并不代表通常的临床实践。
其次,任何此类研究都必须被视为漫长旅程中的第一步探索。要从研究人员在本研究中评估的LLM研究原型过渡到可供人们和护理人员使用的安全、强大的工具,还需要进行大量的额外研究。
还有许多重要的限制因素需要解决,包括在真实世界限制条件下的实验表现,以及对健康公平与公正、隐私、稳健性等重要主题的专门探索,以确保技术的安全性和可靠性。
AI或将彻底改变医学
过去一年中大模型的发展,也让许多人看到AI在医学中的应用潜力。
谷歌便是这个垂类模型领域的典型代表。
谷歌的Med-PaLM 2根据14项标准进行了测试,结果发现可以达到医学专家的水平。
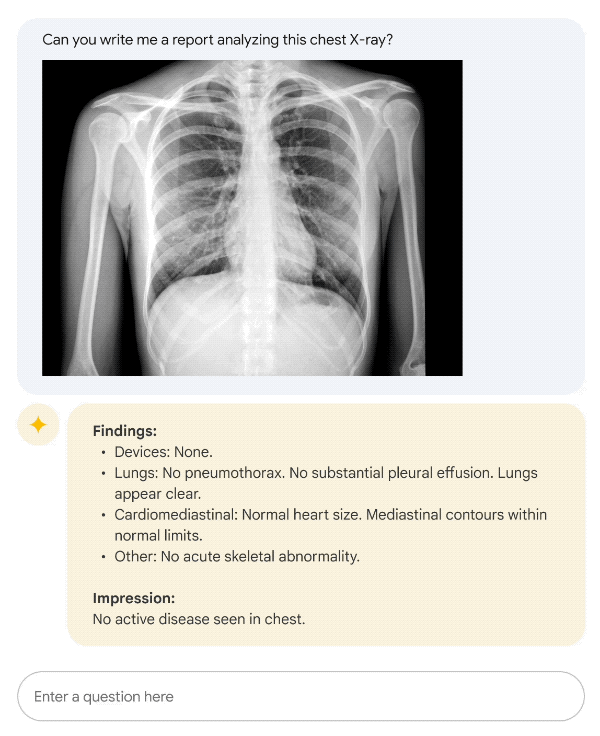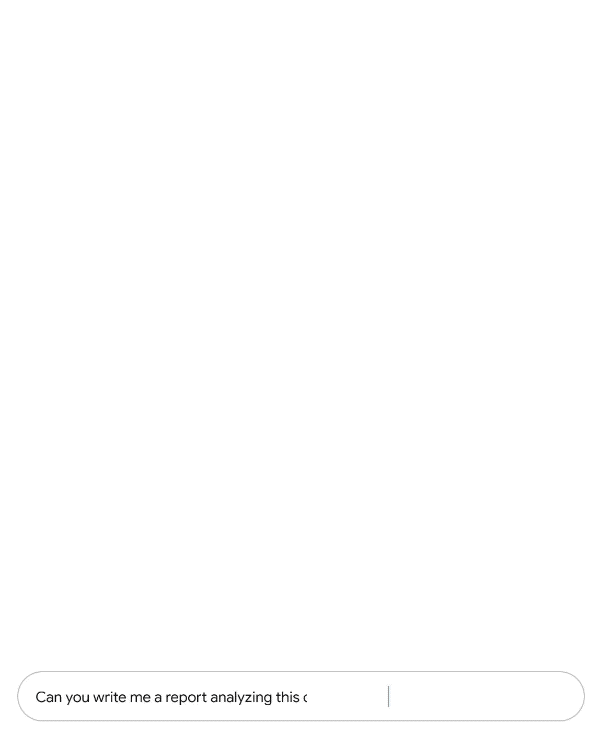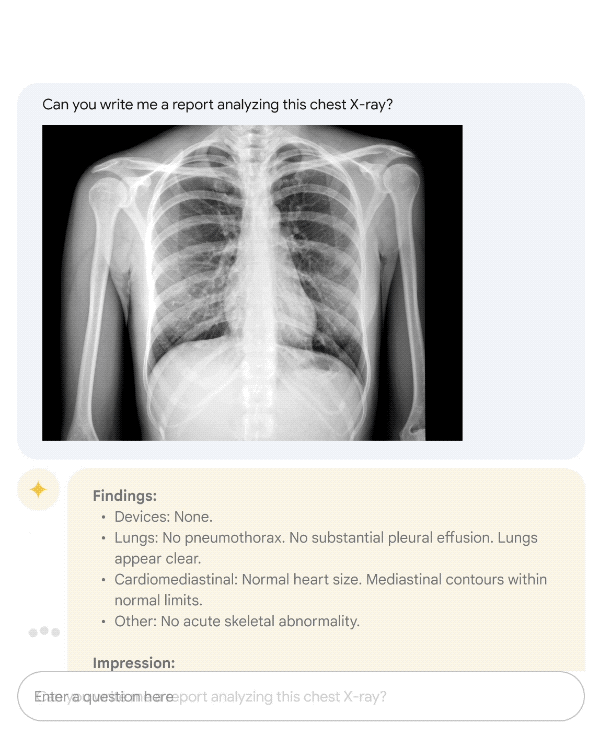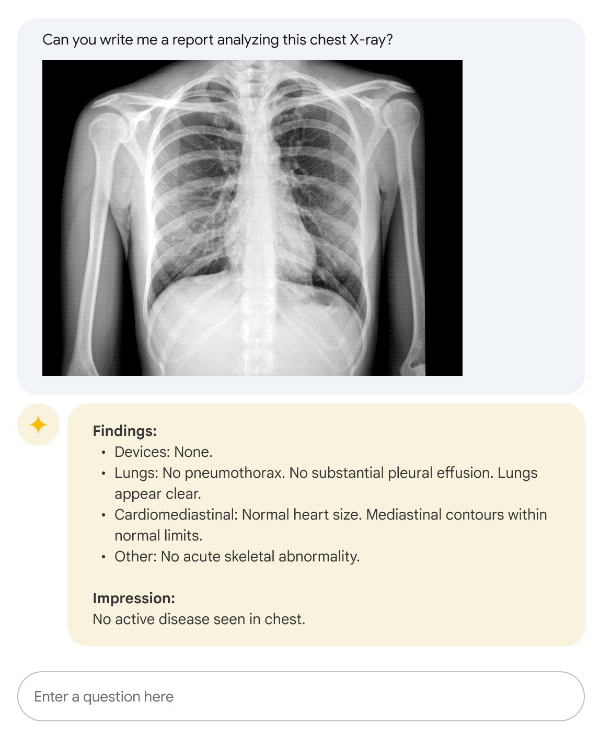
还记得去年,一位4岁小男孩得了「怪病」,3年来看了17位医生,但他们都无法解释疼痛的具体原因。
直到小男孩母亲注册ChatGPT之后,将病情上传,才终于得到了正确的诊断结果。
近来,有网友发文表示,在ChatGPT帮助下,发现了女朋友的过敏反应。

凌晨4点,她全身起了大面积的荨麻疹,去医院后医生给她静脉注射了皮质类固醇,然后就好了。医生说可能是防腐剂/保鲜剂/食品化学物质引起的,但我们一直都吃得很干净,怎么会这样呢?
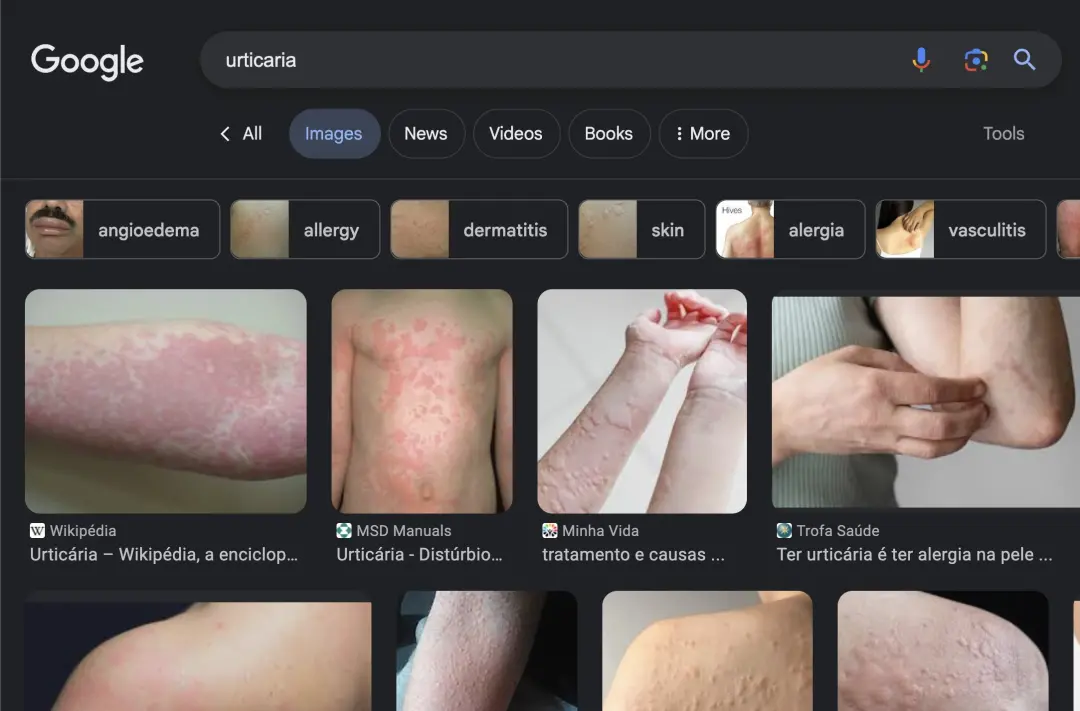
紧接着,他们把过去24小时内吃的所有东西告诉GPT-4,然后让它对最可能的过敏原进行排名。
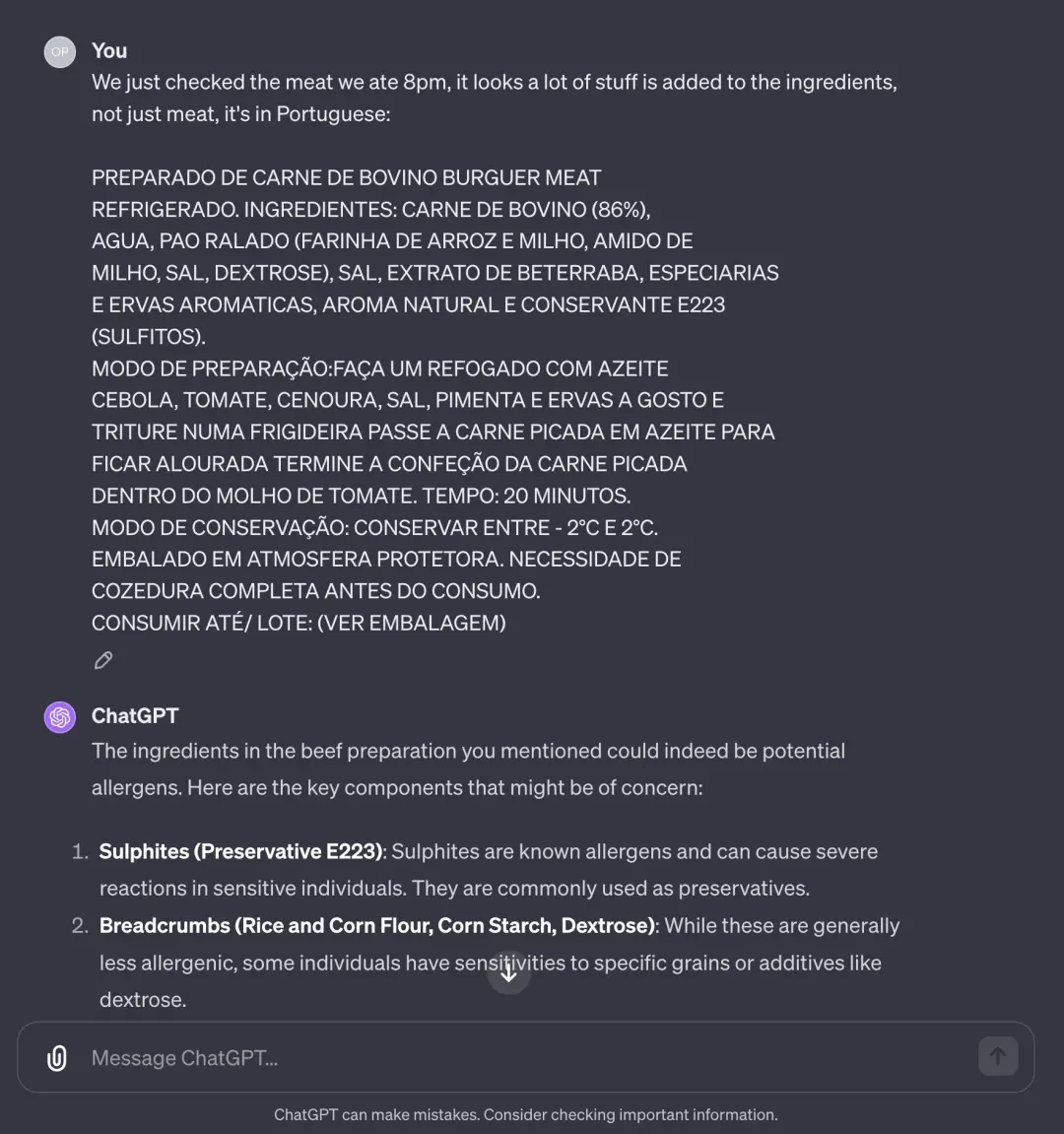
GPT-4起初以为是巧克力里的榛子的原因,但后来网友突然想起昨天从超市买的肉,便从垃圾桶捡出来把它配料输给GPT-4……
配料:牛肉(86%)、水、面包屑(大米和玉米粉、淀粉、玉米、盐、葡萄糖)、盐、甜菜提取物、香料和芳香草药、天然香气和防腐剂E223(亚硫酸盐)。

GPT-4立即将亚硫酸盐列为可能导致荨麻疹的最主要过敏原,通过谷歌搜索,证实它会是荨麻疹原因之一。
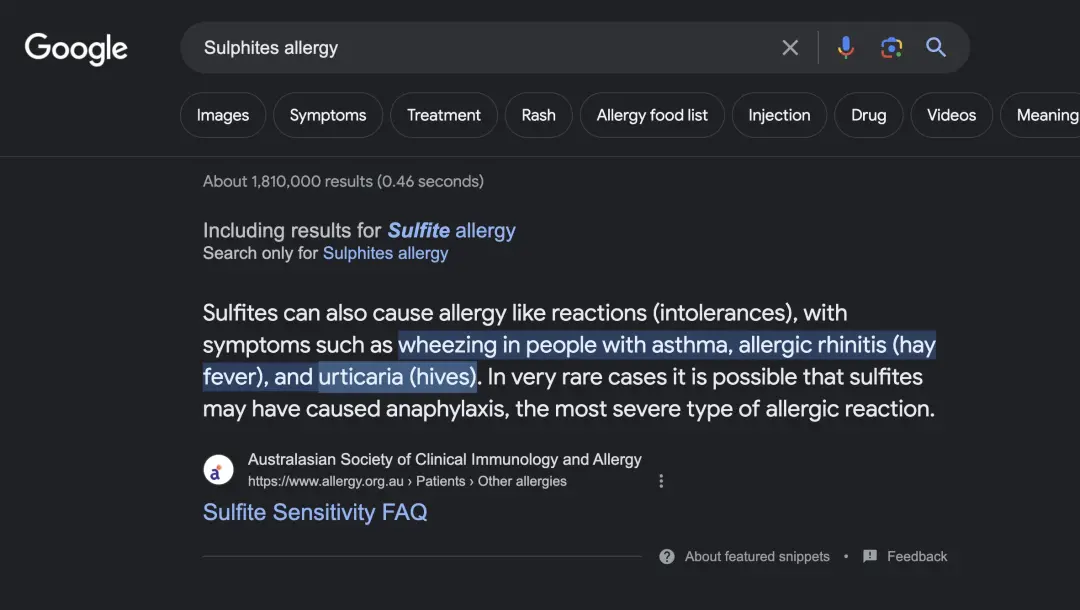
最后发现,这与医生所说的相符,很可能是食物防腐剂过敏。
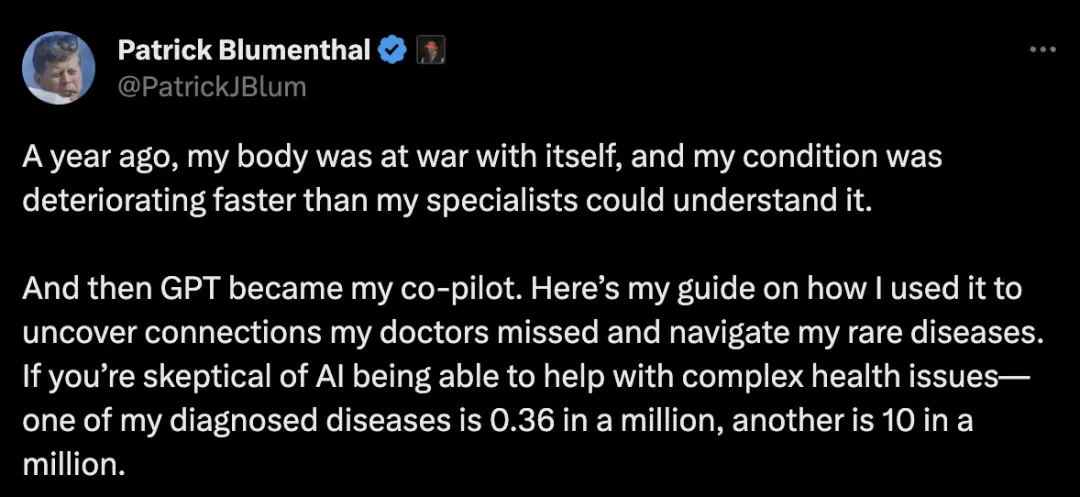
另外一位网友也分享了自己的心路历程,以及利用GPT发现医生们遗漏的病情联系。
一年前,我的身体在与自己作战,我的病情恶化速度之快超出了专家们的理解。然后,GPT成为了我的Copilot。
现在,谷歌推出的AMIE系统再次引领了医疗AI革命。
论文作者表示,「据我们所知,这是第一次为诊断对话和记录临床病史而设计的对话式人工智能系统」。
AI医学,未来可期。
Prev Chapter:Meta承认使用盗版书籍训练AI:拒绝赔偿作家
Next Chapter:#ChatGPT之父称人类水平的AI即将出现#,但对世界的影响远比想象的小
评论区
- 这篇文章还没有收到评论,赶紧来抢沙发吧~
【随机内容】

