

清华系又造大模型标杆!2B规模干翻Mistral-7B,超低成本为AI Agent护航_tiknovel-最新最全的nft,web3,AI技术资讯技术社区
清华系又造大模型标杆!2B规模干翻Mistral-7B,超低成本为AI Agent护航
本周四,国内最早从事“大模型+Agent”的创企面壁智能开年放大招——发布迄今最强旗舰端侧大模型面壁MiniCPM。
这是一款“2B性能小钢炮”,仅用24亿参数,却能对打百亿级大模型。
此前爆火的欧洲生成式AI独角兽Mistral AI,正是凭借大胆路线,用70亿参数大模型Mistral-7B成功挑战Llama 2,成为证明数十亿参数模型足以做到高性能的标杆之作。
如今,“中国版Mistral”以黑马之姿全面开挂,在多项主流评测榜单性能超越Mistral-7B,而且首次有效实现端侧部署多模态并给出实测样例,能聊天能写代码,还能理解图像信息并给出准确的回答。
做出这些战绩的团队,既年轻又资深,落脚在于中国大模型企业最密集的地区——北京五道口,创立只有一年,科研团队逾100人,清北含量达80%,平均年龄仅28岁。
发布会期间,智东西与面壁智能核心创始团队进行深入交流。据分享,面壁智能有三道大模型技术优势:1)算法优化,自创“模型沙盒”;2)省钱秘籍,支持在CPU上跑推理、在消费级显卡上做高效训练与微调;3)数据治理,形成从数据治理到多维评测的闭环,牵引模型快速迭代。
01.
智能终端“开卷”端侧大模型,
开年黑马为何致力于大模型小型化?
自去年下半年以来,智能硬件的圈子越来越热闹:华为、小米、OPPO、vivo、荣耀等大厂纷纷下场,给手机装上数十亿参数的端侧大模型;AI PC概念扎堆亮相国际消费电子盛会CES 2024;多家创企向AI硬件新形态发起挑战。
用更小模型做更强AI,已是大模型竞赛卷向千亿参数后的又一焦点方向。这反应了智能硬件产品集体面临的问题:云端跑大模型够强,但如果端侧不能独当一面,那么断网不能用、响应延迟慢等问题都会影响终端用户的使用体验。
将大模型落在端侧,关键要做到三点:一是体量够小,二是性能够用,三是成本够低。
由于智能硬件的内存容量和带宽受限,端侧模型越小,计算量和占用内存越少,计算成本、功耗、推理延迟越低,端侧AI应用响应才越快。

在规模飙升的技术竞赛中,成本已成为大模型隐形竞争力。成本代表了大模型的利润率,是智能终端企业关注的重点。端侧模型有全天候低成本的特点,能够通过云端协同弥补千亿级参数模型在大规模部署成本和门槛上的先天不足,减轻云端数据中心的算力负担。
作为一家初创公司,2022年8月才成立的面壁智能,此前专注于研发千亿级大模型和AI Agent,又不像手机大厂那样有足够量级硬件产品的天然优势加持,为何也选择进军端侧?
这要从团队使命说起,面壁智能的愿景“智周万物”、OpenBMB开源社区的愿景“让大模型飞入千家万户”,使其志在让尽可能多的人在尽可能多的地方和场景享受大模型的通用智能。
就像人的智能由脑干、小脑、大脑分管不同任务,未来不同尺寸的模型分工负责不同复杂程度的任务,这样的通用人工智能(AGI)实现路径更加高效。
所以,发力端侧,是面壁智能战略的重要一环。
2B规模的模型,能够应用于离用户更近、更便携的移动设备上,从而在更多地方发挥作用,解决大模型在实际落地中成本高、门槛高的问题。
从技术研判而言,2023年ChatGPT和GPT-4的推出表明大模型技术路线已基本确定,接下来就是要探索其科学机理,并极致优化效率。
清华大学计算机系长聘副教授、面壁智能联合创始人刘知远说,希望这个端侧模型能让更多人意识到,即便是2B尺寸的模型,能达到的能力上限仍远超想象。就像造船舶和飞机有流体力学的支持,其团队致力于将大模型研究科学化,这是真正让它实现商业化与可持续发展的重要动力。
同时,通过云端协同催化应用落地,端侧大模型能够更好地为面壁智能“大模型+Agent”双引擎战略服务。在端侧大模型的技术积累,与将云上大模型持续小型化的技术一脉相承,最终有助于加快迈向AGI。

“Agent能力如果用到端侧模型上,更好地服务于具体场景,创造出更多的价值,我认为在这两个方向上能够互相支撑,产生一些奇妙的化学反应。”面壁智能联合创始人、CTO曾国洋说。
02.
2B参数、1T数据,性能超越Mistral-7B,率先将多模态落地手机
2023年,Mistral-7B横空出世,以7B参数打败了数百亿参数的开源大语言模型霸主Llama 2,成为大模型领域“以小搏大”的典范,意气风发地树立了开源领域的新标杆。
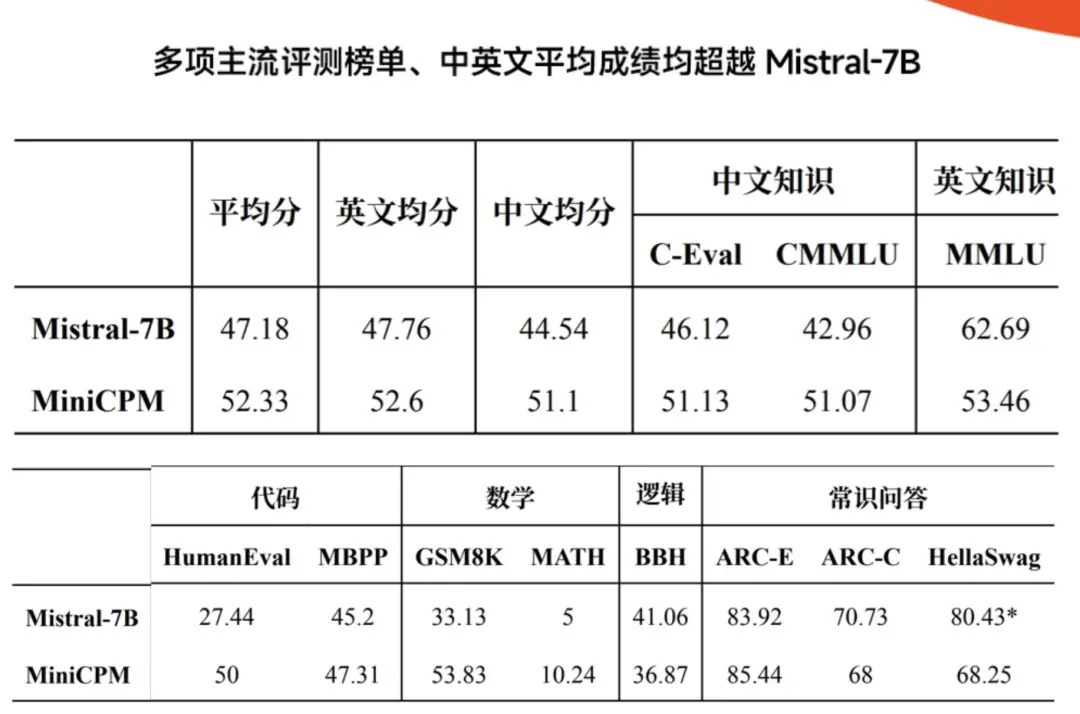
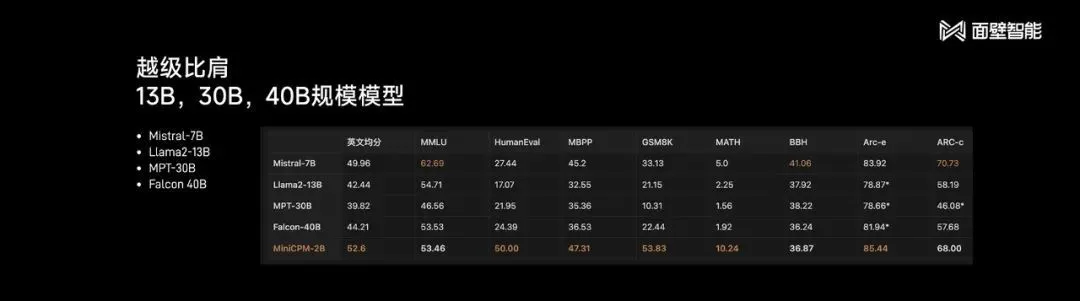
今年一开年,面壁智能接棒挑起“将大模型小型化”的重担:推出“性能新旗舰”面壁MiniCPM,用2B参数规模、1T Tokens精选数据,横扫多项主流评测榜单,中英文平均成绩均超越Mistral-7B,中文和通用能力战斗力超过微软明星模型Phi-2(蒸馏GPT-4)。

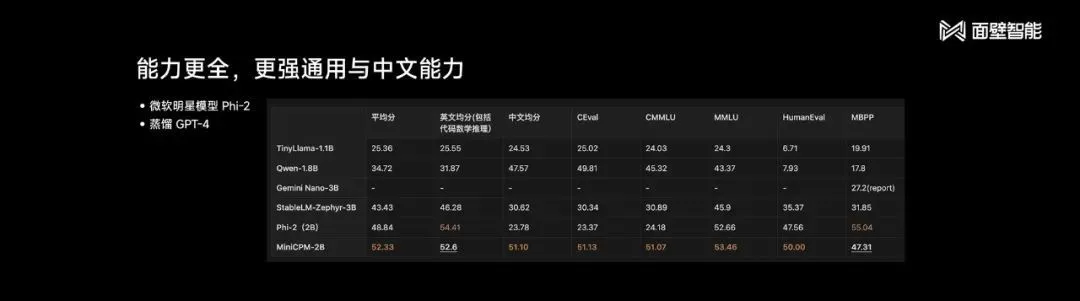
面对“山东省最高的山是哪座山,它比黄山高还是矮?差距多少?”这种混合型考题,MiniCPM不仅能给出准确海拔,还能计算差值,速度相较人工搜索与计算显著提升。
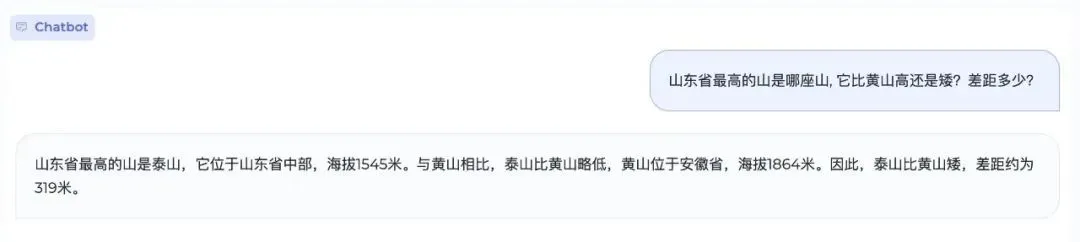
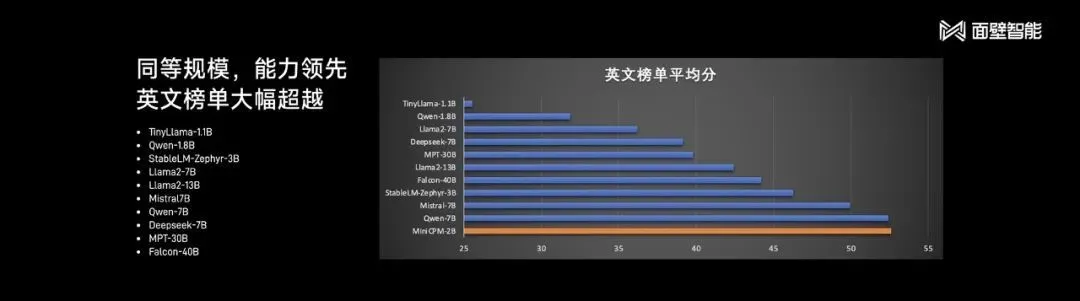
MiniCPM-2B不仅通用与中文能力更强,比拼英文时,同样具备跟数十亿乃至数百亿参数大模型掰手腕的能力。
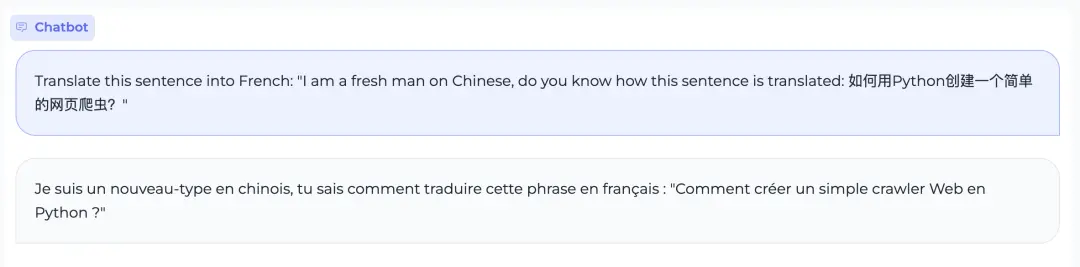
它能绕过多语言混合翻译的陷阱题,比如被要求用英文要求大模型将一段中英文混杂的句子翻译成法语,能理解意图,输出正确答案。
对于角色扮演,MiniCPM同样驾轻就熟:扮演李逵找宋江要钱,能惟妙惟肖地拿捏住说话语气与技巧;给妻子写情书,则自觉塞进一些能够表达爱意的emoji表情。因此可以基于它来驱动一些情感类聊天机器人端侧应用。
![]()
![]()
此外,MiniCPM编程能力超越Mistral-7B,能实现端侧运行写代码,有助于节省编程工作量。
![]()
跟百亿级大模型同场PK,MiniCPM-7B也能在多数评测中性能领先。
在最接近人评的测评集MTBench上,MiniCPM得到了很好的评价。

经过Int4量化后,MiniCPM可在手机上进行部署推理,流式输出速度略高于人类说话速度。
MiniCPM开源地址:
https://github.com/OpenBMB/MiniCPM
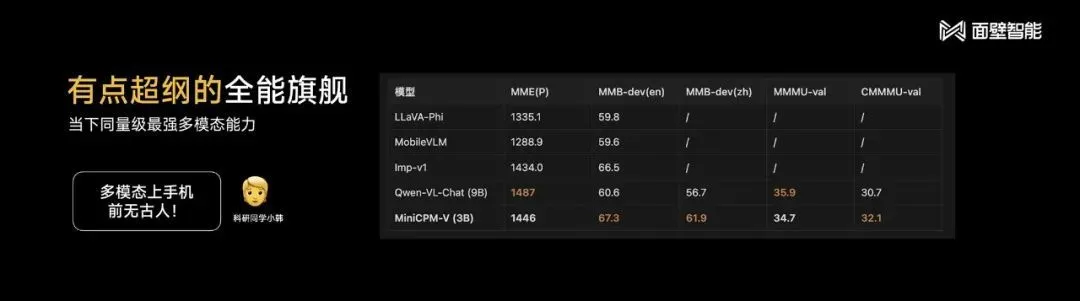
MiniCPM不仅能说,而且会看,首批跑通了多模态大模型在手机上的部署。MiniCPM-V评测性能超过其他同等规模多模态模型,在部分评测集上达到与9.6B Qwen-VL-Chat相当甚至更好的性能,能解读图像细节、理解抽象的梗图。
为什么要把多模态的能力落到终端?面壁智能联合创始人、CEO李大海举了个极限的例子,比如去野外露营,信号比较差时遇到一条蛇,怎么判断这是不是毒蛇?这时拍照发给端侧大模型,就能得到及时的响应。如果有紧急情况,也能在网络掉线的情况下,先求助于端侧大模型。
Prev Chapter:Adobe为苹果Vision Pro将推Firefly AI:文生图搬进虚拟空间
Next Chapter:AI NPC:实现通用人工智能的必由之路?
评论区
- 这篇文章还没有收到评论,赶紧来抢沙发吧~
【随机内容】


