Meta推出“自学评估器”:无需人工注释改善评估,性能超GPT-4等常用AI大语言模型评审
8 月 7 日消息,Meta 公司为了缓解自然语言处理(NLP)技术依赖人类注释评估 AI 模型的问题,最新推出了“自学评估器”(Self-Taught Evaluator),利用合成数据训练 AI。
NPU 技术挑战
NPU 技术的发展,推动大型语言模型(LLMs)高精度地执行复杂的语言相关任务,实现更自然的人机交互。
不过当前 NPU 技术面临的一个重要挑战,就是评估模型严重依赖人工注释。
人工生成的数据对于训练和验证模型至关重要,但收集这些数据既费钱又费时。而且随着模型的改进,以前收集的注释可能需要更新,从而降低了它们在评估新模型时的效用。
目前的模型评估方法通常涉及收集大量人类对模型响应的偏好判断。这些方法包括在有参考答案的任务中使用自动度量,或使用直接输出分数的分类器。
这些方法都有局限性,尤其是在创意写作或编码等复杂场景下,可能存在多个有效回答,导致了人类判断的高差异问题和高成本。
自学评估器
Meta FAIR 团队推出了名为“自学评估器”的全新方式,不需要人工注释,而是使用合成数据进行训练。
这一过程从种子模型开始,种子模型会生成对比鲜明的合成偏好对。然后,模型对这些偏好对进行评估并不断改进,在随后的迭代中利用其判断来提高性能。这种方法充分利用了模型生成和评估数据的能力,大大减少了对人工注释的依赖。
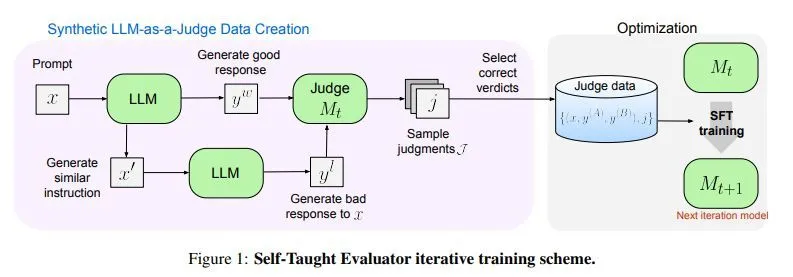
IT之家附上关键步骤如下:
1. 使用种子 LLM 为给定指令生成基线响应。
2. 创建指令的修改版本,促使 LLM 生成质量低于原始响应的新响应。
这些配对回答构成了训练数据的基础,“自学评估器”作为 LLM-as-a-Judge,为这些配对生成推理轨迹和判断。
通过反复该过程,模型通过自我生成和自我评估的数据不断提高其判断的准确性,从而有效地形成自我完善的循环。
成果
Meta FAIR 团队在 Llama-3-70B-Instruct 模型上测试“自学评估器”,在 RewardBench 基准测试中将准确率从 75.4 提高到了 88.7,达到或超过了使用人类注释训练的模型的性能,性能超过 GPT-4 等常用大语言模型评审(LLM Judges)。

这一重大改进证明了合成数据在加强模型评估方面的有效性。此外,研究人员还进行了多次迭代,进一步完善了模型的功能。
相关内容
- 2024-12-20 AI也会得老年痴呆!最新研究:AI版本越老越糊涂
- 2024-12-19 传AI集成到苹果iPhone 腾讯大涨4% 字节概念股涨停
- 2024-12-19 AI创企暴雷!90后女创始人欺诈被捕:涉案7000万,或面临40年刑期
- 2024-12-19 AI成“吞电巨兽”!美监管机构警告:部分地区最早明年将电力短缺
- 2024-12-19 刚刚,AI颠覆物理模拟:一句话精准仿真,学术圈半壁江山联手耗时24个月研究成果
点击排行
- 105-17OpenAI多位重量级高管离职,质疑再次涌向Sam Altman
- 203-07ChatGPT-Plus,AI 助手全套开源解决方案,自带运营管理后台,开箱即用。
- 306-22RTranslator: 全球第一个开源实时翻译应用程序
- 410-18诺奖得主哈萨比斯最新访谈:仅仅将AI视作一种技术是错误的
- 505-17马斯克称OpenAI最新模型慢得离谱
- 606-23OpenAI CTO:GPT-5可能会在2025年底或2026年初推出
- 706-23企业家自曝用了ChatGPT后裁员近1/10:管理效率大幅提升
- 805-17GPT-4o被全球网友玩坏了 谷歌:终究是错付了
- 906-23高通开放AI模型,助力开发者打造骁龙X Elite平台智能应用
- 1005-17谷歌Gemini AI 计划为学校提供额外的数据保护和隐私