Sora启示录:信仰、对抗与未来
随着OpenAI正式发布首个文生视频大模型Sora,过去几天里围绕Sora技术配方的猜测,对行业影响的讨论成为了科技圈的头条。一位AI创业者对Sora评价是:“没有想到文生视频的GPT时刻能来的这么快。”
从创业者和行业观察角度,文生视频一直被视为多模态AIGC「圣杯」,除了本身相较于文生图来说难度更高外,在数据质量、算力以及多融合技术的复杂性上都有诸多需要突破的关卡,这也是为什么即便是行业异常火热,从Runway等AI视频初创公司崛起,再到去年Pika爆火,业内人士也乐观地认为2024是AI行业的「视频大年」,但还是在时间上留了保守态度。比如,Pika联合创始人Chenlin Meng在去年接受采访预测:“目前视频生成处于类似GPT-2的时刻。”
但Sora所呈现的效果还是打破了业内人士的预期。
无论是同行们——马斯克「人类愿赌服输」,Runway联合创始人「game on」的感慨,还是技术层面,如前阿里总裁贾扬清「非常牛」的评价,似乎让人们一夜之间又回到了一年多前令人恐惧和焦虑的GPT-3时刻。
在各类观点之外,Sora崛起究竟能给创业者乃至技术界带来哪些启示?目前国内外文生视频的发展进度又如何?

「硅基研究室」曾在《Pika爆火,但AI视频还没到「GPT时刻」》一文中系统梳理AI生成视频模型背后的技术路线,主要可分为三个阶段——
阶段一为基于GAN(生成式对抗网络游戏)和VAE模型(变分自编码器),可以自回归地形成视频帧,但该技术的局限性在于应用范围窄,生成视频分辨率低,且仅能生成静态、单一的画面;
阶段二为受GPT3和DALLE启发,行业开始采用Transformer架构,出现了谷歌的Phenaki、微软的NUWA等一系列的视频生成模型,巨头押注之中,提升了视频模型的能力,例如可以捕捉上下文,实现颗粒度更细的语义控制等,却缺点也更明显了——计算量太大了,对配对数据集的要求也更大。
阶段三也则是受stable diffusion等文生图应用扩散模型的启发(diffusion models),从图像到视频领域,采用扩散架构成为了主流,Meta的Make-a-video、英伟达的Video LDM,初创公司Runway的Runway-Gen1、Runway-Gen2、字节的MagicVideo等也都是采用了扩散架构。
但扩散模型这一技术路线在算法、数据上存在难点,比如如何改善计算成本和提升数据集质量这一老问题,以及在生成效果与质量上,例如画面的一致性、分辨率、生成长度上也有不少的问题。
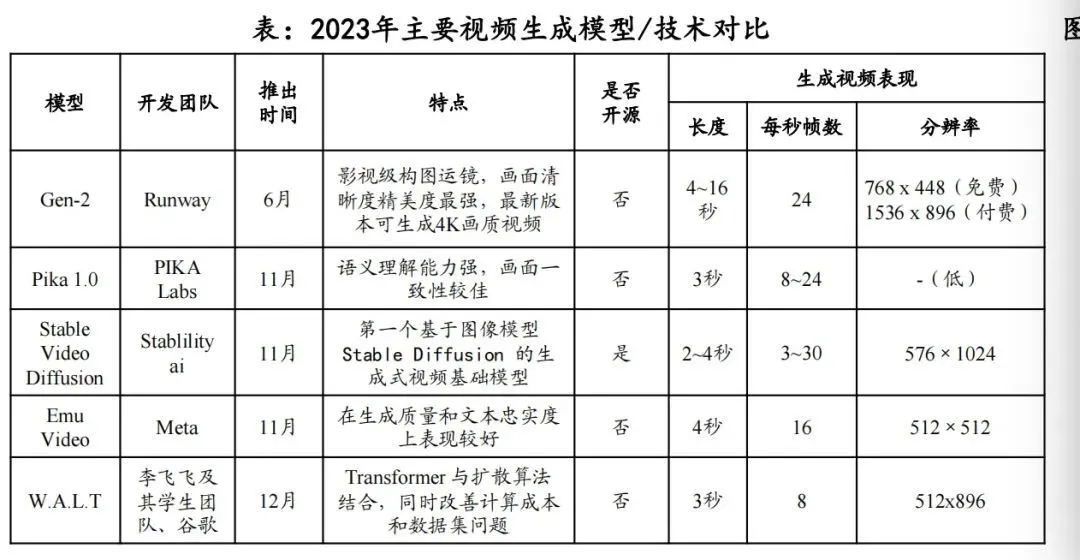
而Sora所呈现出的效果,如生成风格的多样性、画面的一致性等优势恰好弥补了过去视频生成模型的劣势。而复盘Sora之所以能加速视频模型进程,综合官方的技术文档和专家的猜测观点,核心逻辑依旧是OpenAI技术路线的又一次验证,这套路线的特点是:大力出奇迹、足够简洁和坚守技术信仰。
一是大力出奇迹,Sora遵循了OpenAI推崇的Scaling Law。在Scaling Law的指导下,OpenAI擅长以更大规模的算力和数据提升模型性能表现。思谋科技创始人贾佳亚评价Sora:“Sora是大力出奇迹,在学术界连VIT的256*256的分辨率都没法改的情况下,Sora直接用上了高清以及更大的分辨率,这没几千上万张 H100都不敢想象如何开始这个项目。”
二是简洁性。根据技术文档和专家猜测,Sora是使用了混合模型架构——是Transformer架构的Diffusion扩散模型,据纽约大学数据科学中心的助理教授谢赛宁的猜测(注:他也是Sora技术文档中所引用的一篇关键论文的作者之一),Sora应该是建立在一种混合模型DiT之上(DiT是一个带有Transformer主干的扩散模型,它= [VAE编码器+ViT+DDPM+VAE解码器])。
同时,Sora参考了文生文模型中的Token原理。在文生文模型中,文本被同意转化为token的数字表示形式,用以模型训练。而OpenAI提出了一种用patch(视觉补丁)统一图像与视频的方法。

OpenAI官方公布的示例视频
谢赛宁就评价这些技术特点是「简单性和可扩展性」,没有专注于创新。“因为简单性意味着灵活性。”
三是不变的技术信仰。Sora的爆发并非是短期,而是源自业界(比如老大哥谷歌)的技术尝试以及OpenAI长期的技术积累,从文本、图像等诸多技术尝试中均可见一斑。
创新无法被计划,但所有的创新都可以成为颠覆式创新的垫脚石,这仍然是OpenAI给大公司留下的启示。

不可否认的是,在「太牛了」等感叹后,国内外的大模型企业也开始了新一轮的焦虑:从文本、图像再到视频模型,随着差距进一步拉大,「追赶」又成了新一轮的主题。
去年Pika爆火时,行业曾预测,未来在视频领域也会是一家公司领先一到两年,其他公司在追赶。但现在,竞争的时间窗口正因Sora而大大缩小。面对与OpenAI的竞争,Pika创始人郭文景回应:“我们觉得这是一个很振奋人心的消息,我们已经在筹备直接冲,将直接对标Sora。”
根据美国VC机构a16z的统计,2023年,文生视频领域发布相关工具与产品达到了21种,发布产品的多为初创企业。
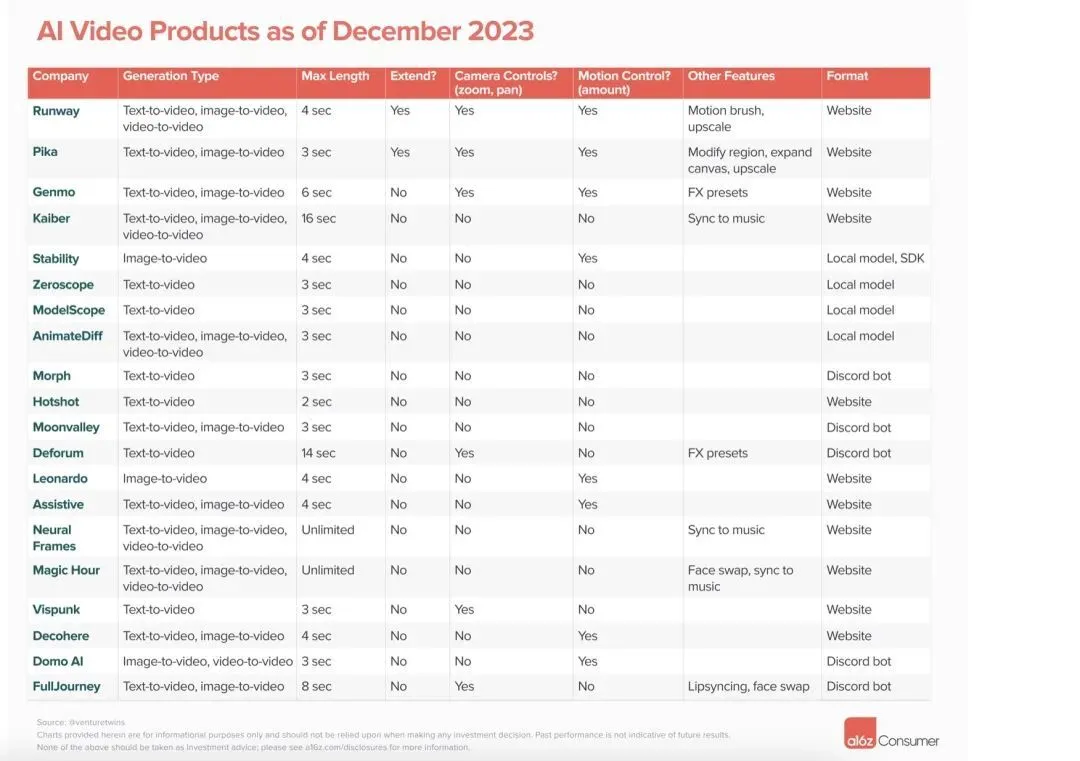
但当前,国内国外的文生视频领域呈现出不同的竞争态势。
在国外,一方面形成了「科技巨头+创业派+专业派」的组合,目前头部科技巨头基本都已入局,只是产品尚未全面公测。专业派则是如Adobe此类面向专业级用户的老牌软件巨头。而创业派则是包括了Runway、Pika等。另一方面,由于海外较为细分和垂直化的科技生态,也涌现出如HeyGen、Descript、Rephrase.ai等围绕轻量化视频制作的工具或平台型企业,这一部分初创企业目前也在通过收购或被收购,扩充生态。比如OpenAI参投了Descript,而Rephrase.ai则被Adobe收购。
反观国内,目前的路线和竞争格局还尚不清晰。「硅基研究室」梳理,大厂也在积极押注视频生成,如字节跳动的文生视频模型MagicVideo-V2、阿达摩院的Zeroscope等。不久前,张楠辞任抖音集团CEO,同时转向剪映发展,也被外界解读为字节对视频领域押注。
尽管技术水平不同,生态也不同,但摆在国内外企业面前的难点与挑战也是类似的。
首先在技术方面,由于是闭源模型,Sora并未公开更多的技术细节,路径依旧是模糊的。据魔搭社区开发者的讨论,一些可能的技术难点如下:Sora究竟是如何保证视频特征被更好地保留的?Sora的数据集组成如何?如何保证海量高质量的数据(数据的获取和标注又是如何完成的?)
其次在算力方面,初创企业难以复刻OpenAI「大力出奇迹」的路径,奥特曼近期一系列押注算力的计划也再度印证了算力的稀缺性。随着大模型的发展速度更快,算力成本是否能如奥特曼所想的那样降低,二者之间谁的速度更快,这一速度线往往就是初创企业的生死线。
尽管焦虑,但并非没有路可走。如一位开发者所言:“OpenAI画了一条「模糊」的路,但有了这条模糊的路,大家就可以去尝试,从而画出通往视频生成的正确的清晰的路。”
南洋理工大学研究工程师周弈帆就认为从技术贡献上来看,Sora其中一项创新就是使用了一种不限制输入形状的DiT。“DiT能支持不同形状的输入,大概率是因为它以视频的3D位置生成位置编码,打破了一维编码的分辨率限制。后续大家或许会逐渐从U-Net转向DiT来建模扩散模型的去噪模型。”(注:UNet是一种流行的卷积神经网络架构,特别适合图像分割任务)
而对一些内容创作者而言,他们关心的不仅是技术,也有开源问题。实验电影人、AIGC艺术家@海辛在即刻中写道:“我还是更相信开源社区,OpenAI总是提供很好的范式,DallE2,GPT,Sora.. 但至今你都没办法让DallE2画具体某个游戏画风的角色/场景,由于数据集本身的多样性不够,导致没有办法做具体的项目风格,风格没有办法自定义,对于大多数商业项目来说就没有意义,即实用性很低。”
如人们所预测的2024,无疑是AI视频大年,Sora提供了一种新的技术路线和方向,也为内容创作者提供了新的工具,新的追赶开始了,新的竞争与创意也从此刻开始,也正在发生。
相关内容
- 2024-11-23 黄仁勋获港科大荣誉博士,演讲大秀中文,称AI可能是人类历史上最重要的技术
- 2024-11-22 第一批用AI的外贸人已经赢麻了
- 2024-11-21 谷歌前CEO改口称美国ai落后中国了
- 2024-11-19 阿里海外,要靠AI打响效率之战
- 2024-11-18 谷歌前CEO:AI性能将继续高速增长,潜在威胁不容忽视
点击排行
- 105-17OpenAI多位重量级高管离职,质疑再次涌向Sam Altman
- 206-22RTranslator: 全球第一个开源实时翻译应用程序
- 303-07ChatGPT-Plus,AI 助手全套开源解决方案,自带运营管理后台,开箱即用。
- 410-18诺奖得主哈萨比斯最新访谈:仅仅将AI视作一种技术是错误的
- 505-17马斯克称OpenAI最新模型慢得离谱
- 606-23OpenAI CTO:GPT-5可能会在2025年底或2026年初推出
- 706-23企业家自曝用了ChatGPT后裁员近1/10:管理效率大幅提升
- 805-17GPT-4o被全球网友玩坏了 谷歌:终究是错付了
- 905-17谷歌Gemini AI 计划为学校提供额外的数据保护和隐私
- 1006-23高通开放AI模型,助力开发者打造骁龙X Elite平台智能应用