超越GPT-4后,更聪明更安全的Claude 3让企业级AI应用成为可能
北京时间3月5日凌晨,OpenAI的主要竞争对手Anthropic发布了最新的大模型Claude 3,这个模型系列分为三个版本:Claude 3 Haiku、Claude 3 Sonnet和Claude 3 Opus。最大也最强的Claude 3 Opus在Anthropic发布的测试成绩中全面超越了OpenAI的GPT-4与谷歌的Gemini Ultra 1.0,尤其在数学、编程、多语言理解、视觉等方面。

Claude 3在多模态,复杂推理和数学能力上的飞跃,让GPT-4不再一枝独秀,让创业公司和AI原生应用开发者们有了更多选择,也让企业级AI应用成为可能。
本文,我们将分别讨论:1.Claude3在哪些方面具有优势。2.Claude3怎样拓宽AI的应用范围。3.头部公司在模型层面不停迭代,对于创业者意味着什么?

Claude 3在复杂推理和数学能力上大幅超越GPT-4
Claude 3 Opus是Anthropic目前能力最强的模型,它能处理高度复杂的任务,应对各种开放式提示和未知场景,Anthropic表示,Claude 3 Opus拥有人类本科生水平的知识。
Claude 3 Sonnet在在能力和速度之间取得了理想的平衡,它在提供强大性能的同时成本更低,而且安全稳定。
Claude 3 Haiku是整个系列最快速、最轻便的模型,它可以几乎实时的响应需求,解答简单的问题,带给用户真人互动般的体验。
更强的复杂推理能力
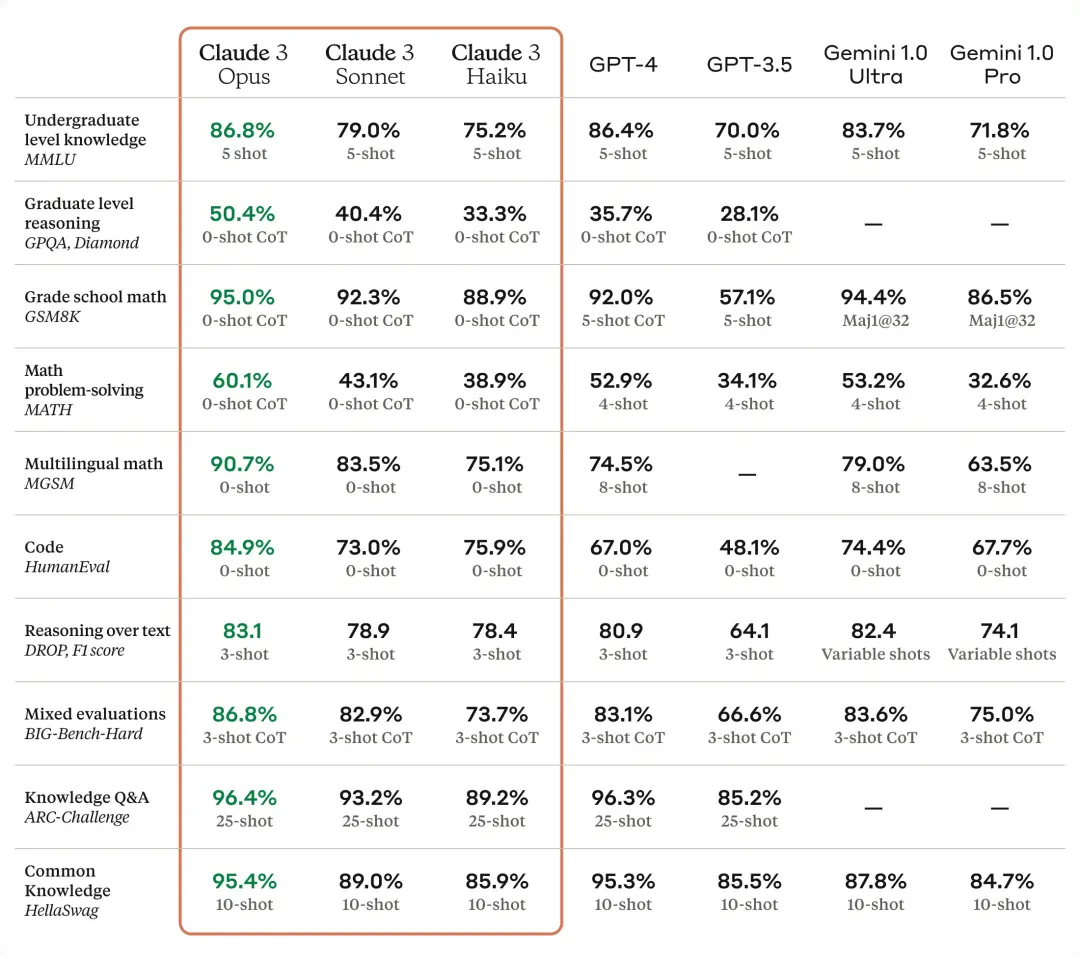
从Anthropic公布的测试成绩看,Claude3 Opus在多项测试中都超越了GPT-4,尤其是在推理、数学、编码等方面的优势更大;甚至Claude 3 Sonnet在数学和编码上相对GPT-4也有优势。
请放大图片观看
尤其值得注意的是GPQA、MATH、MGSM和HumanEval这四个测试。
GPQA是研究生水平的专业知识和推理,Anthropic选择了钻石级问题集,在这个测试中Claude 3 Opus和Claude 3 Sonnet都超越了GPT-4。
MATH和MGSM都是关于数学能力的,其中MATH测试的是数学能力而MGSM是多语言数学能力。Claude 3 Opus在这两个测试中都超越GPT-4,而且MGSM测试中的领先幅度相当大(90.7% VS 74.5%)。另外值得注意的是,在这项测试中Claude 3是在0 shot(零样本提示)的条件下测试的,而GPT-4是在4 shot和8 shot的条件下测试。
在代表编码能力的HumanEval测试中,Claude 3的3个尺寸模型都超越了GPT-4,尤其是Claude 3 Opus相对GPT-4的领先优势达到17.9%,这会让很多AI编程领域的创业公司考虑更换基础模型。

毫无疑问,Claude 3是一个多模态模型,它支持图像和视频输入,在解决复杂多模态推理方面处于领先地位,在与OpenAI及谷歌的先进多模态大模型对比时,它的数项能力都更强。
尤其是在AI2D科学图表基准测试中,它的得分基本比GPT-4V和Gemini有8-10%的领先优势,而且它的Claude 3 Sonnet模型的得分最高,体现出这个模型在能力、尺寸和成本上的优秀平衡性。
更长的上下文窗口
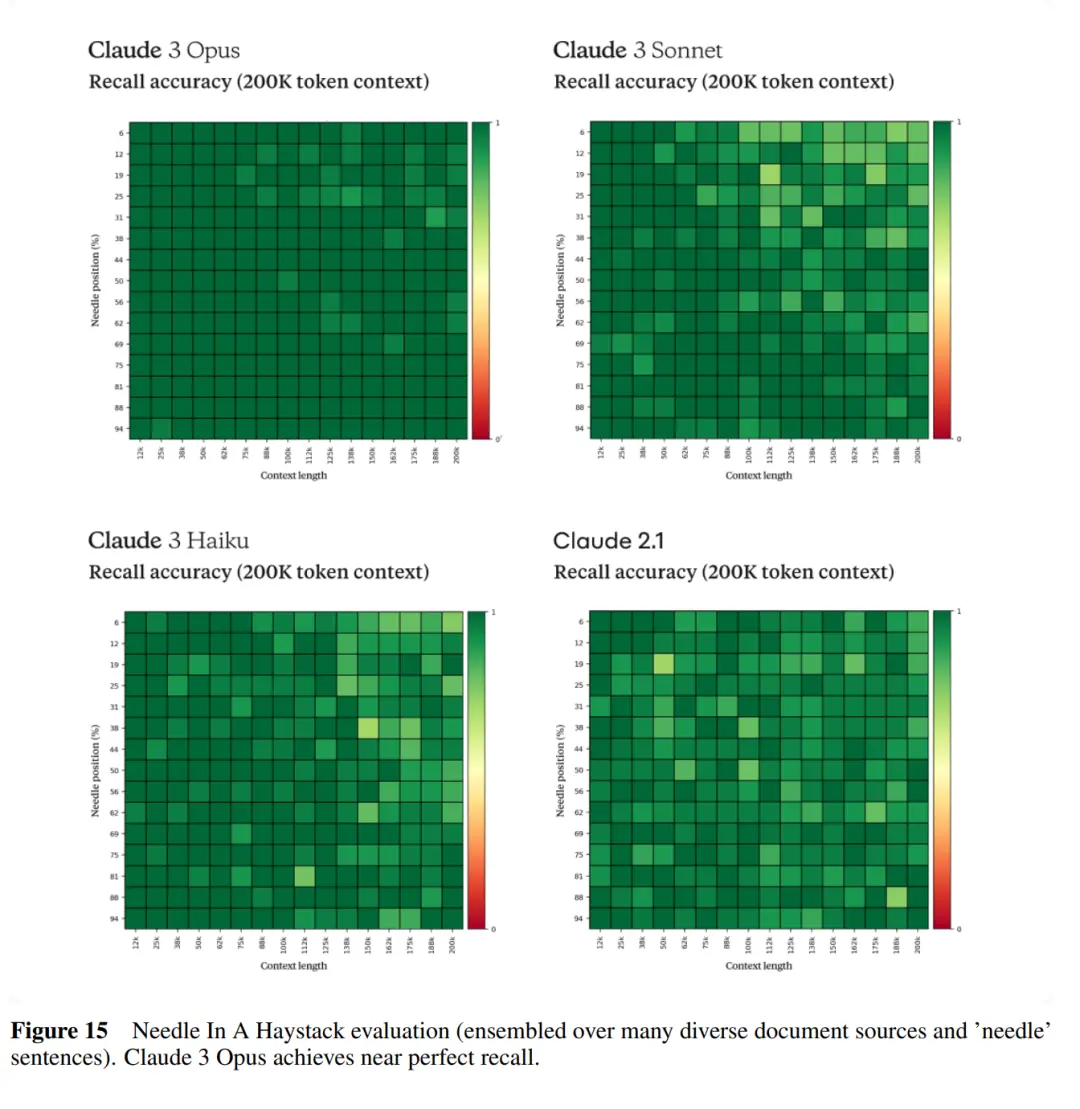
Claude3也延续了长上下文窗口的强项,其初始阶段支持200K token上下文窗口,Anthropic考虑为需要更大上下文窗口的特定客户开放100万token的输入。
在200K token的「大海捞针」(NIAH)测试中,Claude 3 Opus准确率超过99%。
更好的安全及可控性
相比OpenAI,Anthropic一直强调自己模型的安全性与合规性。对于Claude 3系列模型,它强调了自己在训练数据,模型保护和训练基础设施的安全保护。其中值得一提的是它的宪法AI,这一算法确保Claude 3的输出有用、诚实且无害,符合人类社会的伦理和行为原则,尤其是减少性别歧视、种族歧视以及其他不道德的输出。

不过,Claude 3系列模型的价格目前并不便宜,能力最强的Claude 3 Opus比GPT-4 Turbo要贵得多:GPT-4 Turbo每百万token输入/输出收费为10/30美元 ;而Claude 3 Opus为15/75美元。Claude 3 Sonnet则是3美元/15美元,Claude 3 Haiku是0.25美元/1.25美元,考虑到后两种模型的性能,他们对于企业搭建中等和轻量应用的性价比是相当高的。

具有多模态和复杂推理能力的Claude 3让企业级AI应用成为可能
尽管目前大语言模型被用于建立各种各样的AI原生应用中,但是这些应用都有各种各样的局限性。这些局限性使得大语言模型支持的应用,大多都是轻度应用或单一用途应用,很难被用于处理复杂和涉及多个模态的复合企业级应用。
Claude 3(GPT-4V也具有这个能力)的出现,一定程度缓解了这个问题,可以看出来这个系列的模型就是为了应对企业级的复杂任务而设计的。
首先,它拥有更强的逻辑推理能力和数学能力,具有处理更复杂能力的基础。并且它的这种能力是可以在0 shot的条件下发挥出来,这不仅能够提高效率,而且能让它更好地适应那些对容错率有要求的行业。
其次是它的长文本能力,更长的上下文能够让用户处理更复杂的任务,能够一次性把数据和文本输入,而无需批量输入,并且经过几代的迭代后,新模型的长文本处理准确率也有了提高。
最后就是Claude3在安全性和可控性方面做的努力,更安全(模型不会被外部远程控制)和更可控(模型更少输出高风险或有毒内容)能够让模型被企业,尤其是大企业更放心的使用,因为能够满足它们对于安全与合规的高要求。
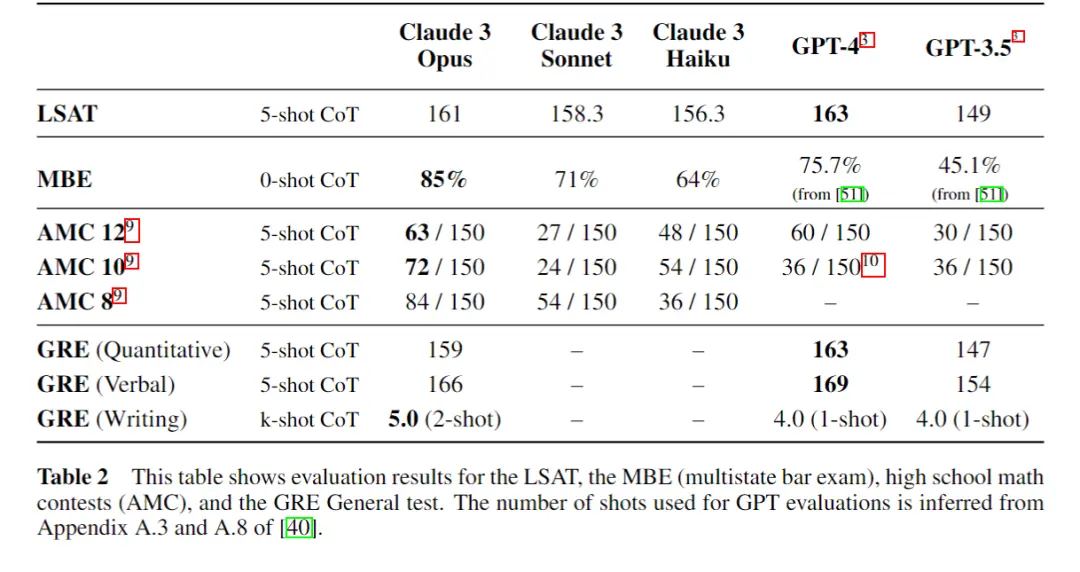
针对细分细分市场能力,Claude3在法学院入学考试(LSAT)、多州律师资格考试(MBE)方面也取得了良好的表现,持平或超过了GPT-4,而法律应用是目前最活跃的创业方向之一,已经产生了多家增长迅速的头部创业公司。

越来越强的基础模型能力对创业者意味着什么?
对于创业者,OpenAI,Anthropic,乃至谷歌、Meta这些公司在基础模型上“卷”,是好事还是坏事?
显然应该是好事,一方面,Meta等公司开源先进的基础模型,让创业者节省高昂的模型训练费用。而当OpenAI有了真正能威胁它领先地位的竞争对手,创业者们就可能用上更便宜的GPT-4或其他先进模型。
有一种说法是,随着“巨头”越来越强,它们的某一次升级,就可能让一群创业公司“死亡”,那么如何避免这种情况?
这时候就得拼专注力,专业能力和易用性了。巨头们通常会追求平台化和生态化,大而全。但是它做每一类应用的团队,很难拼得过专注在一个方向的优秀创业团队。
再举个例子,ChatGPT也可以用网络,也有搜索的插件,但是专注AI搜索的PerplexityAI还是成功了,最近又将获得新一轮融资,估值超10亿美元。
律师们也能用ChatGPT等处理法律文件,但是基于GPT-4的法律人工智能工具Harvey们却同样顺利的获得融资并被大律所采用。
所以当巨头们的模型们越来越强时,创业公司只要能有很强的行业能力,并在易用性上做到极致,那么巨头的模型能力就是创业者手中披荆斩棘的利剑。
相关内容
- 2024-12-20 AI也会得老年痴呆!最新研究:AI版本越老越糊涂
- 2024-12-19 传AI集成到苹果iPhone 腾讯大涨4% 字节概念股涨停
- 2024-12-19 AI创企暴雷!90后女创始人欺诈被捕:涉案7000万,或面临40年刑期
- 2024-12-19 AI成“吞电巨兽”!美监管机构警告:部分地区最早明年将电力短缺
- 2024-12-19 刚刚,AI颠覆物理模拟:一句话精准仿真,学术圈半壁江山联手耗时24个月研究成果
点击排行
- 105-17OpenAI多位重量级高管离职,质疑再次涌向Sam Altman
- 203-07ChatGPT-Plus,AI 助手全套开源解决方案,自带运营管理后台,开箱即用。
- 306-22RTranslator: 全球第一个开源实时翻译应用程序
- 410-18诺奖得主哈萨比斯最新访谈:仅仅将AI视作一种技术是错误的
- 505-17马斯克称OpenAI最新模型慢得离谱
- 606-23OpenAI CTO:GPT-5可能会在2025年底或2026年初推出
- 706-23企业家自曝用了ChatGPT后裁员近1/10:管理效率大幅提升
- 805-17GPT-4o被全球网友玩坏了 谷歌:终究是错付了
- 906-23高通开放AI模型,助力开发者打造骁龙X Elite平台智能应用
- 1005-17谷歌Gemini AI 计划为学校提供额外的数据保护和隐私