谷歌工程师硬核长篇预测,证实黄仁勋观点:AGI或在2029年出现
英伟达CEO黄仁勋在最近的斯坦福活动上预测说,AI会在五年内通过人类测试,AGI将很快到来。而谷歌一位工程师前不久恰巧发出了一篇长文硬核分析,认为2028年有10%概率实现AGI,佐证了老黄的观点。
最近,英伟达CEO黄仁勋表示,AI会在五年内通过人类测试,AGI将很快到来!

在斯坦福大学举行的一个经济论坛上,黄仁勋回答了这个问题:人类何时能创造像人类一样思考的计算机?
这也是硅谷的长期目标之一。
老黄是这样回答的:答案很大程度上取决于我们如何定义这个目标。
如果我们对「像人类一样思考的计算机」的定义,是通过人体测试能力,那么AGI很快就会到来。
五年后,AI将通过人类测试
老黄认为,如果我们把能想象到的每一个测试都列出一个清单,把它放在计算机科学行业面前,让AI去完成,那么不出五年,AI会把每个测试都做得很好。
截至目前,AI可以通过律师考试等测试,但是在胃肠病学等专业医疗测试中,它依然举步维艰。
但在老黄看来,五年后,它应该能通过这些测试中的任何一个。
不过他也承认,如果根据其他定义,AGI可能还很遥远,因为目前专家们对于描述人类思维如何运作方面,仍然存在分歧。
因此,如果从工程师的角度,实现AGI是比较难的,因为工程师需要明确的目标。
另外,黄仁勋还回答了另外一个重要问题——我们还需要多少晶圆厂,来支持AI产业的扩张。
最近,OpenAI CEO Sam Altman的七万亿计划震惊了全世界,他认为,我们还需要更多的晶圆厂。

而在黄仁勋看来,我们的确需要更多芯片,但随着时间推移,每块芯片的性能就会变得更强,这也就限制了我们所需芯片的数量。
他表示:「我们将需要更多的晶圆厂。但是,请记住,随着时间的推移,我们也在极大地改进AI的算法和处理。」
计算效率的提高,需求并不会像今天这么大。
「我会在10年内,将计算能力提高了一百万倍。」
谷歌工程师:2028年有10%概率实现AGI
而谷歌机器人团队的软件工程师Alex Irpan,在LLM领域出现进展后发现,AGI的到来会比自己预想的更快。
Irpan对于AGI的定义如下——
一个人工智能系统,在几乎所有(95%+)具有经济价值的工作上,都能与人类相匹配或超过人类。
4年前,他对于AGI的预测是——
2035年出现的几率为10%;
2045年出现的几率有50%;
2070年出现的几率有90%。
然而现在,当GPT-4、Gemini、Claude等模型出现后,他重新审视了自己的判断。
现在他对于AGI的预测是——
2028年出现的几率为10%;
2035年出现的几率为25%;
2045年出现的几率为50%;
2070年出现的几率为90%。
对于自己的预测, Irpan在下面给出了详尽的解释。
计算的作用
关于AGI,Irpan认为存在两个主要的观点。
观点1:仅仅通过增加模型的规模就足以实现AGI。
目前很多看起来难以克服的问题,在模型规模大到一定程度时,就会自然消失。虽然扩大模型的规模并非易事,但相关的技术挑战预计将在不久的将来就会得到解决,随后AGI的实现也将顺理成章。
观点2:仅仅依靠扩大现有模型的规模是不够的。
虽然增加规模非常重要,但我们最终会发现,即便规模再大也无法实现AGI。这时,就需要跳出当前的技术范式,寻找全新的思路来取得进一步的突破。而这也将会是一个长期的过程。

2020年时,作者忽然发现,第一个观点(即通过扩大规模来实现AGI的假设)的重要性愈发凸显,因此他决定调整自己的「AGI时间线」。
而到了2024年,「规模扩大时才会发生涌现」的观点更是成为了主流。
如果缩放定律继续下去,AGI将不会再花那么长时间。而迄今为止的证据表明,缩放定律更有可能是正确的。
如果有什么没有被提到,那就是预测下一个token的灵活性。
事实证明,如果你对足够多的「指令示例」数据进行微调,那么预测下一个token就足以让AI表现得仿佛它能理解并遵循指令一样,而这已经非常接近于真正的理解了。
基于这种指令微调,可以让一个1.5B模型的表现超越一个没有微调的175B模型。而这就是让ChatGPT在当前的计算资源条件下得以实现的关键。
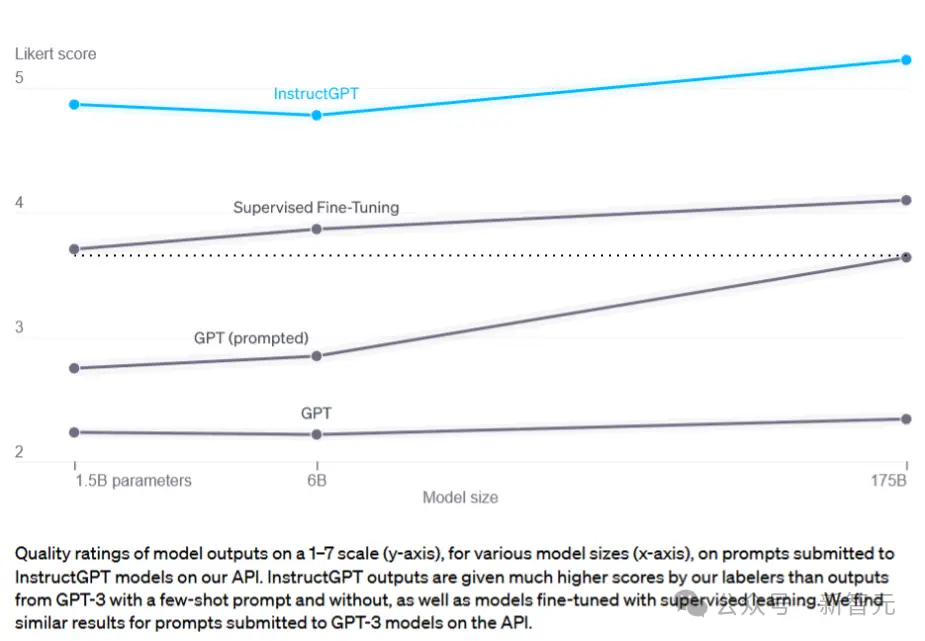
随着时间的推移,仅仅依靠大规模的算力和正确的数据集,就能够实现从初步概念到成熟产品之间的飞跃的可能性越来越大。
现在,作者开始认为,在这一进程中,80%依赖于算力,20%需要更加创新的思想。
当然,创新思想依然至关重要——例如「思维链」就极大地推动了我们能够更加有效地利用大语言模型。

论文地址:https://arxiv.org/abs/2309.03409
至少在当前阶段,找到更好的利用大语言模型的方法仍然是一个需要不断创新的领域。
无监督学习
想当年,在迁移学习领域,大家都为一篇能同时处理5个任务,并且展示了如何在第6个任务上快速学习的论文感到兴奋。
但现在,大家的焦点都放在了如何通过足够多轮次的下一个token预测,以零样本的方式处理多种任务的大语言模型上。换句话说就是:「LLM是能够识别各种模式的通用机器」。
相比之下,像PCGrad这样的专用迁移学习技术,不仅没人使用,甚至也没人去研究了。
如今,无监督和自监督方法仍然是推动每一个LLM和多模态模型发展的「暗物质」。只要将数据和计算任务「投入」这个无底洞,它就能给出我们需要的答案。

论文地址:https://arxiv.org/abs/2307.04721
与此同时,监督学习和强化学习仍然发挥着它们的作用,尽管热度已经大不如前。
当初,深度强化学习就曾经被指效率极其低下。的确,从头开始进行深度强化学习是有些不切实际,但它却是评估的一个有效途径。
时间快速流逝到现在,研究基于人类反馈的强化学习(RLHF)的人表示,只要有高质量的偏好数据,几乎任何强化学习算法都能得到不错的结果。
相比之下,最关键的问题则是,强化学习算法本身。

回顾Yann LeCun在2016年NeurIPS上的演讲中提到的那张著名的「蛋糕幻灯片」。人们虽然对上面的「樱桃」表示尊重,但更关注的是「蛋糕」本身。
作者依然相信,更好的通用强化学习算法是存在的,这些算法能够提升基于人类反馈的强化学习(RLHF)的效果。
然而,当你可以将额外的计算资源用于预训练或监督微调时,去寻找这些算法的必要性就变得相对较小了。
特别是机器学习领域正在逐渐偏向于采用模仿学习这种方法,因为它更易于实施且能更高效地利用计算资源。
至少在当前的研究环境中,我们正从通用的强化学习方法转向利用偏好数据结构的方法,例如动态偏好优化(DPO)等等。
更好的工具
在工具发展方面,随着Transformers技术成为越来越多人的首选,相关的工具变得更专业、更集中。
比如,人们会更倾向于使用那些「已经集成了LLaMa或Whisper」的代码库,而不是那些通用的机器学习框架。
与此同时,API的受众也变得更加广泛,包括业余爱好者、开发者和研究人员等等,这让供应商有了更多的经济动力去改善用户体验。
随着AI变得更加流行和易于获取,提出研究想法的人群会增长,这无疑加速了技术的发展。
缩放定律
一开始公认的模型缩放规律是基于2020年Kaplan等人的研究,这些规律还有很大的改进空间。
两年后,Hoffman等人在2022年提出了「Chinchilla缩放规律」,即在给定的算力(FLOPs)下,只要数据集足够大,模型的规模可以大幅缩小。

论文地址:https://arxiv.org/abs/2203.15556
值得注意的是,Chinchilla缩放规律基于的是这样一个假设:训练一个模型后,在基准测试上仅运行一次推理。
但在实际应用中,大型模型通常会被多次用于推理(作为产品或API的一部分),这种情况下,考虑到推理成本,延长训练时间比Chinchilla建议的更为经济。
随后,Thaddée Yann TYL的博客进一步分析认为,模型的规模甚至可以比以前假设的更小。

文章地址:https://espadrine.github.io/blog/posts/chinchilla-s-death.html
不过,作者认为,对于模型的能力来说,缩放规律的调整并不那么重要——效率的提升虽有,但并不明显。
相比之下,算力和数据仍是主要瓶颈。
在作者看来,目前最重要的变化是,推理时间大大缩短了——更小的规模再加上更加成熟的量化技术,模型可以在时间或内存受限的情况下变得更小。
而这也让如今的大模型产品比Chinchilla出现之前运行得更快。
回想2010年代初,谷歌曾深入研究延迟对搜索引擎使用影响的问题,得出的结论是:「这非常重要」。
当搜索引擎反应慢时,人们就会减少使用,即使搜索结果的质量值得等待。
机器学习产品也是如此。

产品周期兴起
2020年,作者设想了这样一个未来。其中,除了扩大规模之外,几乎不需要什么新的想法。
有人开发了一款对普通人来说足够有用的AI驱动应用程序。
这种极大提升工作效率的工具,基于的可能是GPT-3或更大规模的模型。就像最早的电脑、Lotus Notes或Microsoft Excel一样,改变了商业世界。
假设这个应用程序可以挣到足够的收入,来维持自己的改进。
如果这种提高效率的方式足够有价值,并且在考虑到运算和训练成本之后还能赚取利润,那么你就真正成功了。大公司会购买你的工具,付费客户的增加会带来更多的资金和投资。然后,这些资金又可以用于购买更多的硬件,从而能够进行更大规模的训练。
这种基于规模的思路意味着,研究会更加集中于少数几个有效的想法上。
随着模型变得越来越大、性能越来越好,研究将会聚集在一小部分已经证明能随着计算能力增长而有效扩展的方法上。这种现象已经在深度学习领域发生,并且仍在继续。当更多领域采用相同的技术时,知识的共享会变得更加频繁,从而促进了更优质的研究成果的诞生。或许在未来五年内,我们会有一个新的术语来接替深度学习的位置。
现在看来,作者认为不太可能的一切,都成真了。
ChatGPT已经迅速走红,并激发了大批竞争对手。它虽然不是最强的生产力工具,但已足以让人们愿意为此付费。
虽然大多数AI服务虽有盈利潜力,但为了追求增长还是选择亏损经营。据说,微软会因为Github Copilot上每增加一位用户而每月亏损20美元,不过Midjourney已经实现了盈利。

不过,这已经足够让科技巨头和风投公司投入数十亿美元,来购买硬件和招募机器学习人才了。
深度学习已成昨日黄花——现在,人们谈论的是「大语言模型」、「生成式AI」,以及「提示工程」。
现在看来,Transformer将比机器学习历史上的任何架构都要走得更远。

试着再次说不
现在,让我们再来探讨一下:「假设通用人工智能(AGI)会在不久的将来成为可能,我们将如何实现?」
首先,依然可以认为,进步主要来自更强的计力和更大的规模。可能不是基于现有的Transformer技术,而是某种更为高效的「Transformer替代者」。(比如Mamba或其他状态空间模型)
只要有足够的算力和数据,增加代码中的参数量并不难,因此,主要的瓶颈还是在于算力和数据的获取上。
当前的现状是这样一个循环:机器学习推动产品的发展,产品带来资金,资金又进一步推动机器学习的进步。
问题在于,是否有什么因素会让这种「缩放定律」失效。

论文地址:https://arxiv.org/abs/2312.00752
芯片方面,就算价格持续上升,甚至到了限制模型进一步扩大的地步,人们也仍然会希望在自己的手机上运行GPT-4大小的模型。
相比之下,数据的获取似乎是更大的挑战。
相关内容
- 2024-11-23 黄仁勋获港科大荣誉博士,演讲大秀中文,称AI可能是人类历史上最重要的技术
- 2024-11-22 第一批用AI的外贸人已经赢麻了
- 2024-11-21 谷歌前CEO改口称美国ai落后中国了
- 2024-11-19 阿里海外,要靠AI打响效率之战
- 2024-11-18 谷歌前CEO:AI性能将继续高速增长,潜在威胁不容忽视
点击排行
- 105-17OpenAI多位重量级高管离职,质疑再次涌向Sam Altman
- 206-22RTranslator: 全球第一个开源实时翻译应用程序
- 303-07ChatGPT-Plus,AI 助手全套开源解决方案,自带运营管理后台,开箱即用。
- 410-18诺奖得主哈萨比斯最新访谈:仅仅将AI视作一种技术是错误的
- 505-17马斯克称OpenAI最新模型慢得离谱
- 606-23OpenAI CTO:GPT-5可能会在2025年底或2026年初推出
- 706-23企业家自曝用了ChatGPT后裁员近1/10:管理效率大幅提升
- 805-17GPT-4o被全球网友玩坏了 谷歌:终究是错付了
- 906-23高通开放AI模型,助力开发者打造骁龙X Elite平台智能应用
- 1005-17谷歌Gemini AI 计划为学校提供额外的数据保护和隐私