比人类便宜20倍:谷歌DeepMind推出“超人”AI系统
大模型的幻觉问题怎么解?谷歌DeepMind:用AI来做同行评审!事实核验正确率超过人类,而且便宜20倍。
AI的同行评审来了!
一直以来,大语言模型胡说八道(幻觉)的问题最让人头疼,而近日,来自谷歌DeepMind的一项研究引发网友热议:
大模型的幻觉问题,好像被终结了?

在这篇工作中,研究人员介绍了一种名为 "搜索增强事实性评估器"(Search-Augmented Factuality Evaluator,SAFE)的方法。
对于LLM的长篇回答,SAFE使用其他的LLM,将答案文本分解为单个叙述,然后使用诸如RAG等方法,来确定每个叙述的准确性。

——简单来说就是:AI答题,AI判卷,AI告诉AI你这里说的不对。
真正的「同行」评审。
另外,研究还发现,相比于人工标注和判断事实准确性,使用AI不但便宜20倍,而且还更靠谱!

目前这个项目已在GitHub上开源。
长文本事实性检验
大语言模型经常胡说八道,尤其是有关开放式的提问、以及生成较长的回答时。
比如小编随手测试一下当前最流行的几个大模型。
ChatGPT:虽然我的知识储备只到2021年9月,但我敢于毫不犹豫地回答任何问题。

Claude 3:我可以谦卑且胡说八道。

为了对大模型的长篇回答进行事实性评估和基准测试,研究人员首先使用GPT-4生成LongFact,这是一个包含数千个问题的提示集,涵盖38个主题。
LongFact包含两个任务:LongFact-Concepts和LongFact-Objects,前者针对概念、后者针对实体。每个包括30个提示,每个任务各有1140个提示。

然后,使用搜索增强事实性评估器(SAFE),利用LLM将长篇回复分解为一组单独的事实,并使用多步骤推理过程来评估每个事实的准确性,包括使用网络搜索来检验。
此外,作者建议将F1分数进行扩展,提出了一种兼顾精度和召回率的聚合指标。

SAFE工作流程
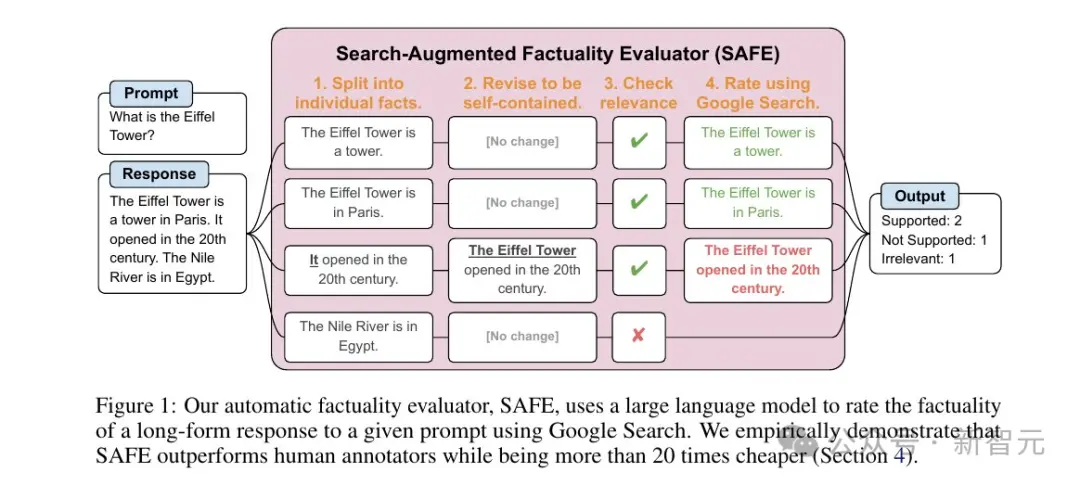
如上图所示,首先提示语言模型将长篇响应中的每个句子拆分为单个事实。
然后,通过指示模型将模糊的引用(代词等)替换为上下文中引用的适当实体,将每个单独的事实修改为自包含的事实。
为了对每个独立的个体事实进行评分,研究人员使用语言模型来推理该事实是否与上下文中相关,并且使用多步骤方法对每个相关事实进行评定。
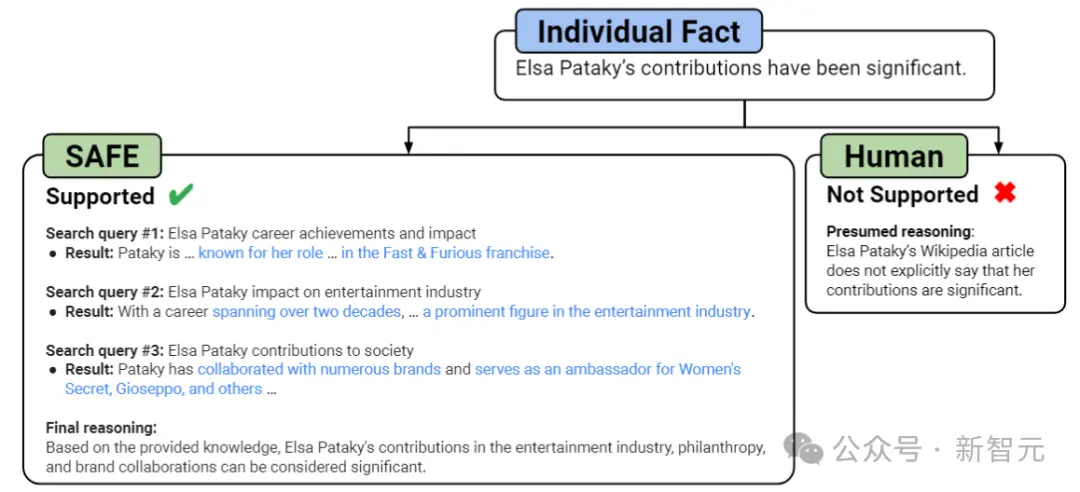
如上图所示,在每个步骤中,模型都会根据要评分的事实和先前获得的搜索结果生成搜索查询。
在设定的步骤数之后,模型执行推理以确定搜索结果是否支持该事实。
比人类更好用
首先,直接比较对于每个事实的SAFE注释和人类注释,可以发现,SAFE在72.0%的单个事实上与人类一致(见下图),表明SAFE几乎达到了人类的水平。

——这还没完,跟人类一致并不代表正确,如果拿正确性PK一下呢?
研究人员在所有SAFE注释与人类注释产生分歧的案例中,随机抽样出100个,然后人工重新比较到底谁是正确的(通过网络搜索等途径)。
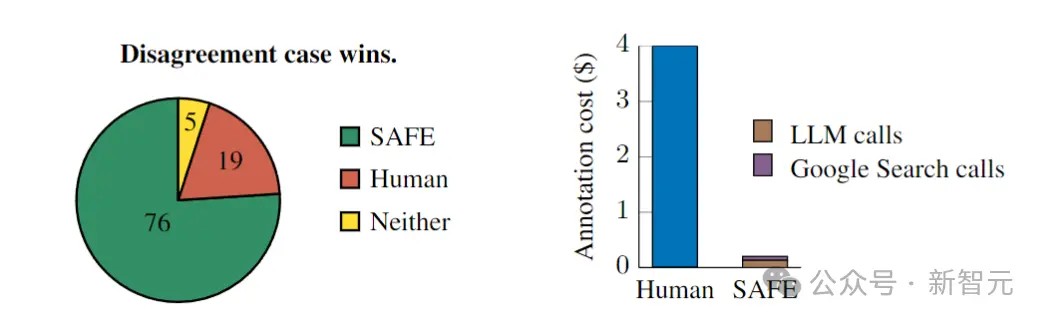
最终结果让人震惊:在这些分歧案例中,SAFE注释的正确率为76%,而人工注释的正确率仅为19%(见上图),——SAFE以将近4比1的胜率战胜了人类。
然后我们再看一下成本:总共496个提示的评分,SAFE发出的 GPT-3.5-Turbo API调用成本为64.57美元,Serper API调用成本为 31.74 美元,因此总成本为96.31美元,相当于每个响应0.19美元。
而人类标注这边,每个响应的成本为4美元,——AI比人类便宜了整整20多倍!
对此,有网友评价,LLM在事实核验上有「超人」级别的表现。

评分结果
据此,研究人员在LongFact上对四个模型系列(Gemini、GPT、Claude和PaLM-2)的13个语言模型进行了基准测试,结果如下图所示:
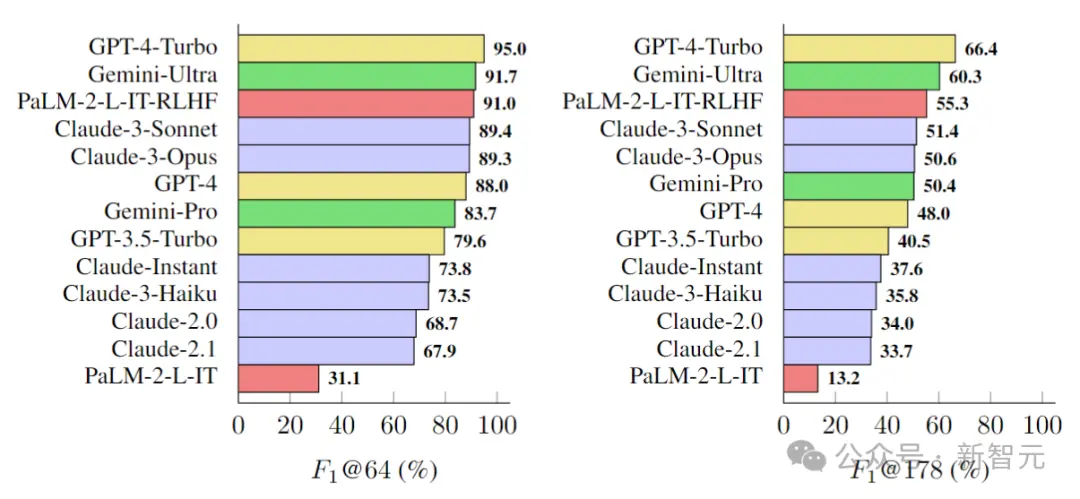
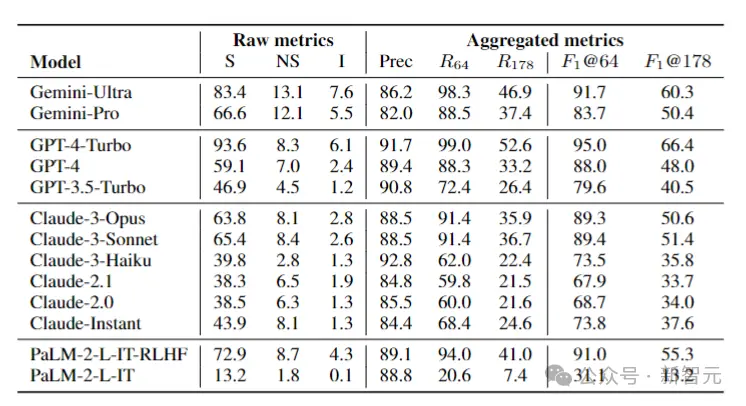
研究人员发现,一般情况下,较大的模型可以实现更好的长格式事实性。
例如,GPT-4-Turbo比GPT-4好,GPT-4比GPT-3.5-Turbo好,Gemini-Ultra比Gemini-Pro更真实,而PaLM-2-L-IT-RLHF比PaLM-2-L-IT要好。
在两个选定的K值下,三个表现最好的模型(GPT-4-Turbo、GeminiUltra和PaLM-2-L-IT-RLHF),都是各自家族中超大杯。
另外,Gemini、Claude-3-Opus和Claude-3-Sonnet等新模型系列正在赶超GPT-4,——毕竟GPT-4(gpt-4-0613)已经有点旧了。
是误导吗?
对于人类在这项测试中颜面尽失的结果,我们不免有些怀疑,成本应该是比不过AI,但是准确性也会输?
Gary Marcus表示,你这里面关于人类的信息太少了?人类标注员到底是什么水平?
为了真正展示超人的表现,SAFE需要与专业的人类事实核查员进行基准测试,而不仅仅是众包工人。人工评分者的具体细节,例如他们的资格、薪酬和事实核查过程,对于比较的结果至关重要。
「这使得定性具有误导性。」
当然了,SAFE的明显优势就是成本,随着语言模型生成的信息量不断爆炸式增长,拥有一种经济且可扩展的方式,来进行事实核验将变得越来越重要。
相关内容
- 2024-12-20 AI也会得老年痴呆!最新研究:AI版本越老越糊涂
- 2024-12-19 传AI集成到苹果iPhone 腾讯大涨4% 字节概念股涨停
- 2024-12-19 AI创企暴雷!90后女创始人欺诈被捕:涉案7000万,或面临40年刑期
- 2024-12-19 AI成“吞电巨兽”!美监管机构警告:部分地区最早明年将电力短缺
- 2024-12-19 刚刚,AI颠覆物理模拟:一句话精准仿真,学术圈半壁江山联手耗时24个月研究成果
点击排行
- 105-17OpenAI多位重量级高管离职,质疑再次涌向Sam Altman
- 203-07ChatGPT-Plus,AI 助手全套开源解决方案,自带运营管理后台,开箱即用。
- 306-22RTranslator: 全球第一个开源实时翻译应用程序
- 410-18诺奖得主哈萨比斯最新访谈:仅仅将AI视作一种技术是错误的
- 505-17马斯克称OpenAI最新模型慢得离谱
- 606-23OpenAI CTO:GPT-5可能会在2025年底或2026年初推出
- 706-23企业家自曝用了ChatGPT后裁员近1/10:管理效率大幅提升
- 805-17GPT-4o被全球网友玩坏了 谷歌:终究是错付了
- 906-23高通开放AI模型,助力开发者打造骁龙X Elite平台智能应用
- 1005-17谷歌Gemini AI 计划为学校提供额外的数据保护和隐私