

OpenAI 再次给大模型 “泡沫” 续命_tiknovel-最新最全的nft,web3,AI技术资讯技术社区
OpenAI 再次给大模型 “泡沫” 续命
文丨贺乾明
编辑丨程曼祺 黄俊杰
OpenAI 今年最重要的产品 o1 模型如期发布。AI 最大获利者英伟达的股价两天累计涨了 10%。
消耗更多算力答题的 o1,看到问题会先 “思考” 数十秒、甚至更久,再给出回复。OpenAI 称,它回答奥赛数学题或完成编程任务时,表现远超市场上已有的大模型。
但 OpenAI CEO 山姆·阿尔特曼(Sam Altman)的好心情很快就被打断。在他宣布 o1 全量上线的推文下,排在第一的评论是:“到底什么时候能用上新的语音功能??” 他立刻反击:“能不能先花几个星期感谢感谢这魔法般的智能,然后再要新玩具?”
这位用户追着阿尔特曼要的不是什么新玩具,是 OpenAI 在今年 5 月就允诺即将到来的 GPT-4o 端到端语音功能。在当时的现场演示中,这个新的 AI 声音自然、反应极快,还知道什么时候插话,让旁人难辨真假。按官方时间表,上千万 ChatGPT 付费用户本将在几周内用上这功能,但一直被跳票到现在。
过去一年里,OpenAI 的产品都是类似的 “期货”:GPT-4 已上线一年多,OpenAI 的下一代模型 GPT-5 依然没有发布迹象。OpenAI 今年初发布的视频模型 Sora 也没有大规模开放,到现在都只有少数被他们挑选的行业人士实际用过。
行业第一的跳票一次次磨损着资本市场对 AI 大模型的耐心。一些中国科技巨头和大模型公司今年年中暂缓训练基础模型,把更多资源投到应用开发,或把 GPU 算力租给外部客户。他们担心技术没多少进步空间,开始减少投入、争取回报。
本周之前,英伟达市值从 6 月的高点下跌超 20%,微软市值也缩水了 13%,各自蒸发了几千亿美元。微软 CFO 称,他们投在大模型领域的数百亿美元,得等 15 年或更久才能回本。
红杉的研究显示,去年 AI 领域的投入比收入多了 1200 多亿美元,今年可能会扩大到 5000 亿美元。但除了英伟达,没有几个公司见到大比例的收入增长。越来越多业内人开始讨论,如果大模型的能力就到此为止,AI 泡沫会不会又一次破灭?
“泡沫” 并不一定是坏事。新技术改变世界之前,都会出现愿景远超现实的阶段。区别在于愿景能不能兑现,什么时候兑现。如果长期不能兑现,就是泡沫破灭、公司破产,严重的泡沫破灭甚至可以击垮一个领域甚至多个经济体。如果愿景兑现了,一切不过是技术进步的注脚。
OpenAI 发布的 o1,至少会暂时扭转大模型已经没有进步空间的犹疑,为大模型 “泡沫” 续命。
任何新技术都需要不断进步,才有可能改变这个世界。o1 的独特之处不只是编程、数学、物理等领域的性能大幅提升,也在于给一众 OpenAI 追随者和他们背后的投资者找到了前进的路径:以往算力更多用在 “记忆知识”——用大量数据训练模型,o1 则分配了更多算力在 “答题时的思考”,即推理过程,逻辑能力大幅提升。
在此之前,大模型训练已经陷入原有 Scaling Laws 的瓶颈,模型参数规模扩大后,性能提升逐渐放缓。
专门针对数学、编程、科学问题优化的 o1-mini 还展现出了不小的应用潜力,它既可以直接帮科学家和开发者提升工作效率,也指示了在其它高价值垂直领域开发性能、安全性都更好的模型的方法。
像往常的数次发布一样,OpenAI 精心挑选了释放 o1 的时机。据媒体报道,o1 发布前,OpenAI 正在以 1500 亿美元估值寻求 70 亿美元的新融资,潜在投资方包括苹果、英伟达、微软、阿联酋投资基金等。现在,这场资源投入竞赛又多了一个持续下去的理由。
从大语言模型到 “推理模型”,o1 理强文弱
此次 OpenAI 发布了两个供用户使用的模型:o1-preview 和 o1-mini,并预告更多 o1 系列模型正在路上。
之所以将该系列命名为 o1,而非沿用 GPT,是因为二者的训练方式有明显变化。在 OpenAI 介绍 o1 的博客文章里,多次称其为推理模型(reasoning model),而非此前称呼 GPT 时常用的大语言模型(Large Language Model)。
GPT 等传统大语言模型的整体训练逻辑是预训练(pre-training)加精调(fine-tuning):先在预训练阶段用海量数据教大模型学会预测下一个词,然后在精调阶段让大模型学习特定领域的知识,让人类写回答教大模型什么是人想要的答案,机器根据反馈来改进。
o1 的新关键词是强化学习(Reinforcement Learning)和思维链(Chain of Thought,CoT)。
OpenAI 如此描述这个过程:“通过强化学习,o1 学会如何磨练自己的思维链,并完善它所使用的策略。它学会了识别和纠正自己的错误;将复杂步骤分解为更简单的步骤;在当前方法不起作用时尝试不同的方法。这极大地提高了模型的推理能力。”
2016 年击败围棋世界冠军的 AlphaGo 和后续模型 AlphaZero 就使用了强化学习,让模型自我对弈(self-play),学习在不同状态(棋局)下,用什么策略可以提高胜率。模型还能在不断尝试中生成数据,用来训练模型。
OpenAI o1 使用了类似的方法:给大模型提供一步步解题的数据,让模型学着自我纠偏,学习每个步骤应该怎么回答问题能得到最优答案。
“AI 模型的能力还是来自数据,若数据里原本没有或不充分的东西,模型是学不会的,o1 相当于实现了一个合成专业数据的办法。有了这些专业数据, o1 就能学到专业能力了。” 硅基流动创始人袁进辉说。
o1 回答问题时也会把问题拆解成一系列小问题,逐步推理回答,这就是 “思维链”。根据 OpenAI 展示,o1 回答问题的过程如下(用户使用的版本里,OpenAI 隐藏了思维链内容):
问题(原文为英语):
编写一个 bash 脚本,接收一个矩阵(用字符串表示,格式为 '[1,2],[3,4],[5,6]'),并以相同的格式打印出该矩阵的转置。
o1-preview 的解题思路(思维链):
用户请求编写一个 bash 脚本,该脚本可以接收表示矩阵的字符串,例如 '[1,2],[3,4],[5,6]',并以相同的格式输出其转置。
我们首先来理解输入和输出的格式。
输入:'[1,2],[3,4],[5,6]',它对应的矩阵是:
1 2
3 4
5 6
因此,输入是一系列由方括号包裹并用逗号分隔的行。
该矩阵的转置为:
1 3 5
2 4 6
因此,要求的输出为 '[1,3,5],[2,4,6]'。
总体任务:
编写一个 bash 脚本,该脚本接收一个参数(表示矩阵的字符串),并以相同的格式输出其转置。
好的,现在我们来考虑如何在 bash 中解析输入字符串,构建矩阵(可能使用数组),进行转置,然后输出转置后的矩阵,保持相同的格式。
约束条件:
-由于这是 bash,我们必须小心处理字符串解析。
-脚本应接受输入字符串作为参数。
方法:
-解析输入字符串以提取矩阵元素。
-将矩阵构建为一个数组的数组。
-对矩阵进行转置。
-以相同格式输出转置后的矩阵。
实现步骤:
1. 将输入字符串作为参数捕获。
2. 移除所有空格(如果有的话)。
3. 解析输入字符串,将数字提取到数组中。
-由于输入格式为 '[1,2],[3,4],[5,6]',我们可以:
--如果需要,移除外部括号。
--通过 '],' 分割字符串以获取每一行。
--对每一行,移除 '[' 和 ']',然后通过 ',' 分割获取元素。
4. 在 bash 中构建二维数组(数组的数组)。
-由于 bash 数组是一维的,我们需要模拟二维数组。
5. 对矩阵进行转置。
-进行转置时,我们需要将行与列交换。
6. 以所需格式输出转置后的矩阵。
-重新构造输出字符串,格式为 '[1,3,5],[2,4,6]'。
现在,逐步开始编写代码。
潜在问题:
-Bash 本身没有原生的多维数组,因此我们需要进行模拟。
-我们需要处理可能是多位数的数字。
接下来,我们可以一步步开始编写这个 bash 脚本的框架。
【略】
现在让我们使用示例输入 '[1,2],[3,4],[5,6]' 测试这个脚本。
让我试着模拟下,会发生什么。
我会将其写下来,作为一个答案。
不论是强化学习还是思维链,都不是 OpenAI 最先提出的技术方向。
在 o1 上线前,Google DeepMind 就在 7 月发布了用类似方法训练的 AlphaGeometry 模型更新版,能在国际奥数竞赛 IMO 中拿银牌。
但 OpenAI 再一次证明了他们可以在行业基础上,率先拿出效果更惊人的模型。据 OpenAI 介绍,他们专为国际信息学奥赛训练的 o1-ioi 模型能拿到金牌。
凭借新的训练和推理方法,OpenAI o1-preview 解决高难度数学题、处理编程任务方面大幅超过 GPT-4o。比如在竞赛数学数据集 AIME 2024 上,o1-preview 得分是 GPT-4o 的 4 倍多;在编程竞赛数据集 Codeforces 上,差距变成 5.6 倍。
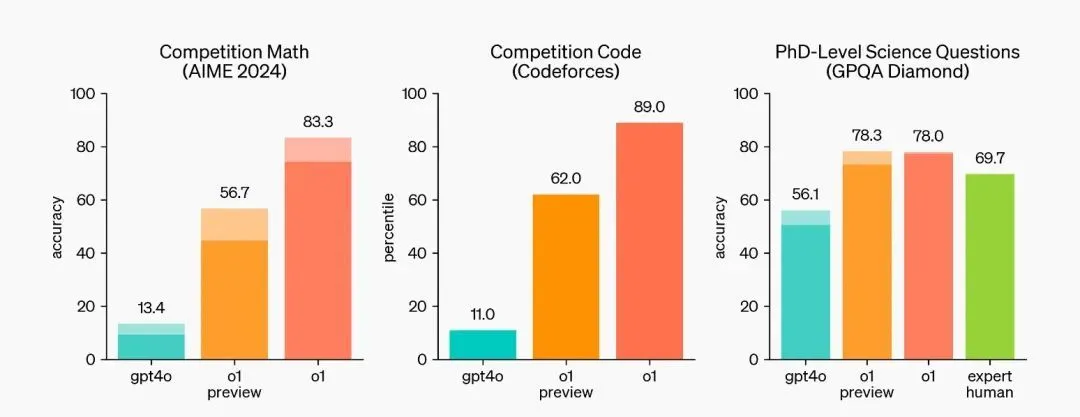
在数学竞赛、编程竞赛、科学问答数据集测试中,o1-preview、o1 大幅超过 GPT-4o。
OpenAI 称,目前限量上线的 OpenAI o1-preview 和 OpenAI o1-mini 只是早期版本,他们的下一个模型,在物理、化学、生物等有挑战的测试题中,表现与博士生类似,而此前的模型大多是本科生或硕士生水平。
把技术变成现实,OpenAI 提到的贡献者有 212 人,与 GPT-4o 的文本部分的贡献者相当(234 人)。但训练 o1 需要的数据种类变多了。OpenAI 提到,o1 预训练用到的数据来自公开数据集、合作伙伴的专有数据和内部开发的自定义数据集,而 GPT-4o 掌握文本能力时,只用了前两种数据。
偏向 “推理模型” 的 o1 系列并没有全面超过 GPT-4o,语言能力是它的相对弱项。
在 OpenAI 的测试中,大多人认为 o1-preview 在数据分析、编程和数学等看重推理的问题解答上比 GPT-4o 更好,而在个人写作、文本编辑等方面,依然是 GPT-4o 更好。
那些 GPT-4o 解决不了的问题,o1-preview 也会出现,比如它同样会 “胡说八道”,认为 9.11 比 9.2 更大。
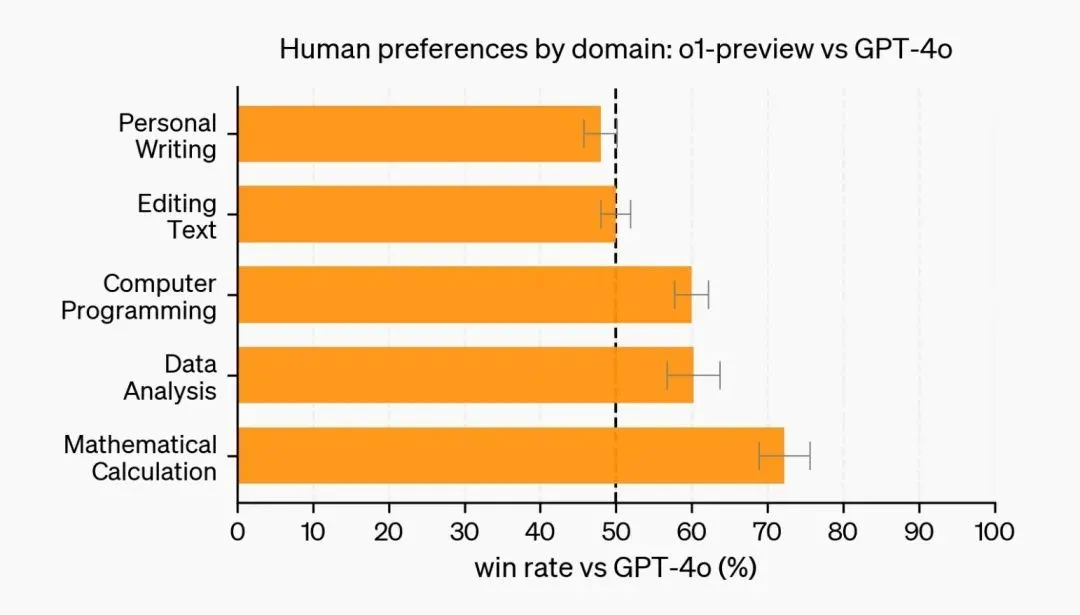
个人写作、文本编辑等方面,GPT-4o 更好。
思维链带来的更长的响应时间(思考)可能是 o1 系列实际使用中的短板。在被要求 “列出五个第三个字母是 A 的国家的名字” 时,GPT-4o 只用 3 秒,而 o1-mini 花了 9 秒,o1-preview 花了 32 秒,是 GPT-4o 的十倍。对于简单问题基本不可用。
o1-preview 和 mini 暂时也不像 GPT-4o 那样具备浏览网页、获取信息,和处理上传的文件、图片等功能。目前看起来能最快能用 o1 提升生产力的是软件开发者,但 OpenAI 也限制了他们调用 API 的方式:每分钟只能调用 20 次,不包括函数调用、流式传输、系统消息支持等功能。
从训练 Scaling 到推理 Scaling,算力竞赛仍将继续
在多位大模型研究者看来,o1 最重要的变化是展现出了一种大幅提升大模型能力的新路径。
原来的 Scaling Laws 意味着,用更多数据和算力训练出参数更大的模型,性能就会更好。
而如下图, o1 展现出,让模型花更多时间、更多算力回答问题(test-time compute),性能也会持续提升。英伟达资深 AI 科学家 Jim Fan 在社交媒体上说,这可能是自 2022 年 DeepMind 提出 Chinchill Scaling Laws(原版 Scaling Laws 上的一个优化)以来,大模型研究中最重要的一张图。
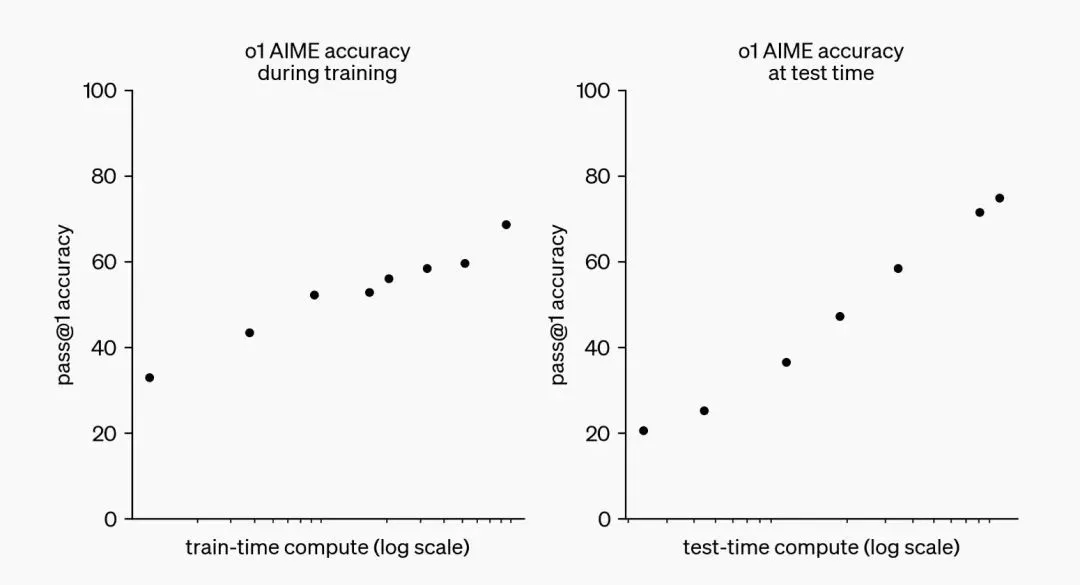
Jim Fan 还提出了大模型未来演进的一种可能:未来的模型可能将推理与知识分离,有小的 “推理核心”,同时也用大量参数来记忆事实(知识),以便在琐事问答等测试中表现出色。
OpenAI 也在介绍 o1 的文章中特意提到,他们会继续开发 GPT 系列的模型。这可能预示,OpenAI 会把 o1 中使用的方法引入到下一代 GPT 模型中。
不管是 o1 成为新的主流方法,还是 o1 与 GPT 系列结合,演化出下一代大模型,算力需求应该都会进一步提升。
OpenAI 未公开 o1 系列的推理成本,但从 o1 模型回答问题的时长和 OpenAI 对 o1 的使用限制可以推测,o1 相比 GPT 系列需要庞大得多的推理算力资源。
每月花 20 美元的 ChatGPT Plus 付费用户,目前每周只能用 30 次 o1-preview 和 50 次 o1-mini。而目前 GPT-4o 的限制是每周 4480 次(每 3 小时 80 次),是 o1-mini 的 90 倍,o1-preview 的 150 倍。
o1-preview 回答问题的时间从 GPT 系列模型的秒级增加到了数十秒、甚至更久。它回答问题时处理的文本量也大幅提升。以文中展示 “思维链” 过程时列举的编程问题为例,o1 解答时,加上思维链,处理的字符有 6632 个,是 GPT-4o 的 4.2 倍 。更长的计算时间和更长的输出都意味着更高的算力成本。
o1 对 AI 前景和算力消费的刺激很快反映在资本市场。自本周初有媒体报道 OpenAI 即将发布新模型后,英伟达股价累计回升 10%,微软也一起上涨。
对于那些不确定技术演进方向或者一度放缓研究基础模型的公司,现在又有新工作可以做,有新方向可以卷了。o1 的发布大概率意味着,在 “推理模型” 上,竞争差距再一次拉开,一轮加速追赶和投入即将发生。
“是时候正经干点正事了,要不真的就不在游戏里了。” 一位中国大模型研究者说。
题图:视觉中国

1957 年,人造物体第一次进入宇宙,绕着地球飞了三个星期。人类抬头就能在夜幕里看到一颗小小的闪光划过天空,与神话里的星宿并行。
这样的壮举跨越种族与意识形态,在全球各地激起了喜悦之情。但并不是我们可能猜想的那种为人类壮举所感动的胜利喜悦。根据政治哲学家汉娜·阿伦特(Hannah Arendt)当年的观察,人们的情绪更接近于一种等待多时的宽慰——科学终于追上了预期,“人类终于在摆脱地球这个囚笼的道路上迈出了第一步”。
人们总是根据技术探索,快速调整着自己对世界的预期。当科幻作家的一桩畅想变成现实,往往是技术终于追上了人们的预期,或者用阿伦特的话说,“科技实现并肯定了人们的梦想既不疯狂也不虚无。”
今天这样的时候,多一点梦想是更好的。
这也是《晚点 LatePost》启动 TECH TUESDAY 这个栏目的预期。我们希望在《晚点》日常关注的商业世界外,定期介绍新的科学研究与技术进展。
这些可能关于一项前沿研究的进展、可能是对一个技术应用的观察,也可能是对一些杰出技术、乃至一个时代的致敬。
这个栏目将从科学与技术的角度出发,记录这个世界的多样变化。在这个旅途中,希望读者能和我们一起,对这个世界增加一分理解。
评论区
- 这篇文章还没有收到评论,赶紧来抢沙发吧~
【随机内容】


