

OpenAI活动第二弹:“强化微调”打造领域专家AI模型,阿尔特曼称其为今年最大惊喜_tiknovel-最新最全的nft,web3,AI技术资讯技术社区
OpenAI活动第二弹:“强化微调”打造领域专家AI模型,阿尔特曼称其为今年最大惊喜
2024-12-07 19:19:10 浏览:83 作者:管理员
OpenAI活动第二弹:“强化微调”打造领域专家AI模型,阿尔特曼称其为今年最大惊喜
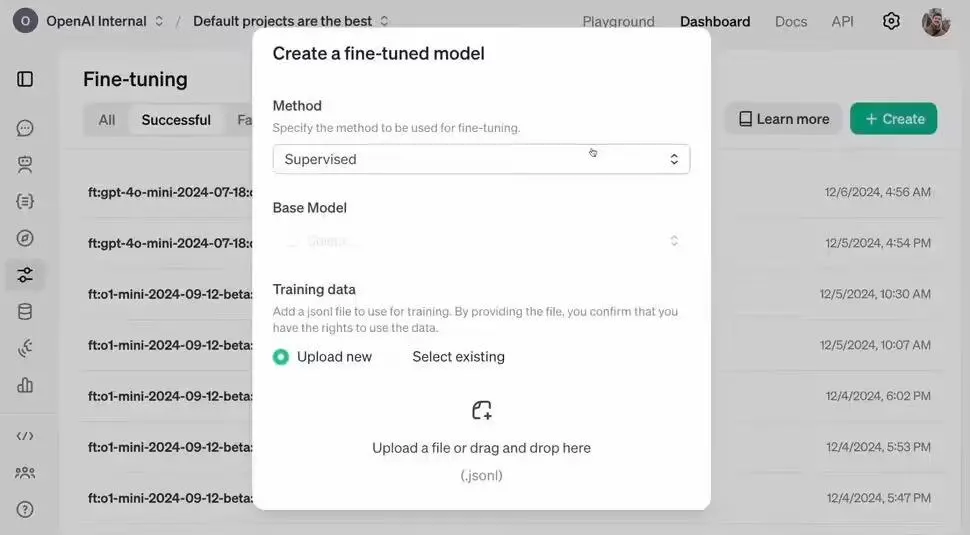

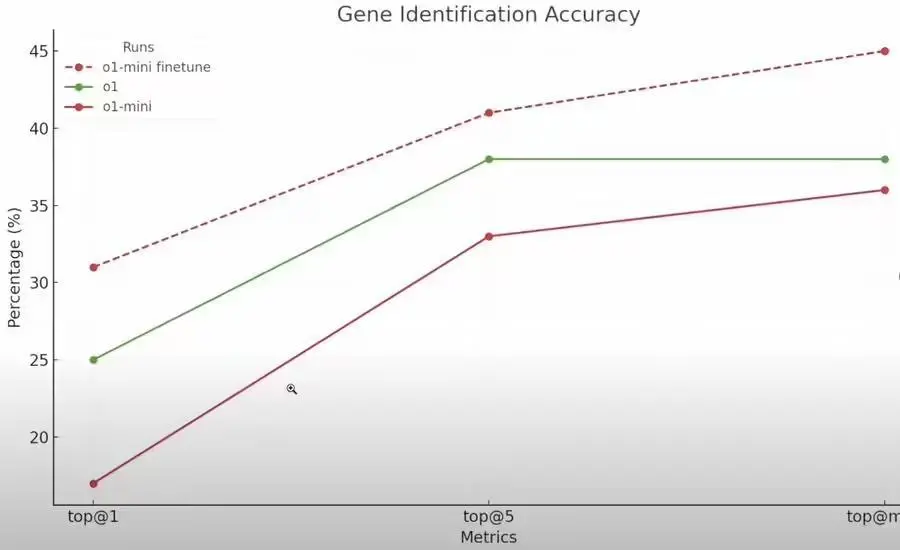
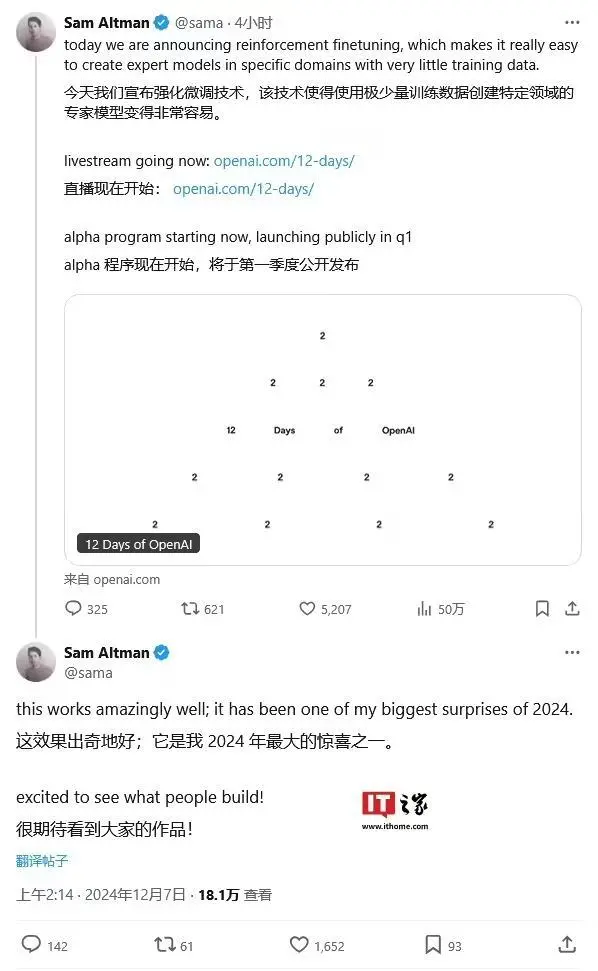
Prev Chapter:SaaS不会被AI颠覆,而是加速鞭策
Next Chapter:OpenAI狂飙突进!仅12个例子就能打造专属AI专家,核心技术竟来自字节?
评论区
共 0 条评论
- 这篇文章还没有收到评论,赶紧来抢沙发吧~
【随机内容】
-

Journey To Become A True God Chapter 765 - Unexpected Betrayal (1)
2024-11-20 -
2024-04-19
-
Dragon-Marked War God Chapter 388 – A Large Teleport Formation
2024-11-23 -
I Shall Seal the Heavens Chapter 252
2024-11-19
