

北大发起Open-Sora计划:旨在复现Sora模型_tiknovel-最新最全的nft,web3,AI技术资讯技术社区
北大发起Open-Sora计划:旨在复现Sora模型
北京大学Yuangroup团队发起了一个 Open-Sora开源计划,旨在复制OpenAI(close AI)的视频生成模型sora。
本项目希望通过开源社区的力量复现Sora,由北大-兔展AIGC联合实验室共同发起,当前资源有限仅搭建了基础架构,无法进行完整训练,希望通过开源社区逐步增加模块并筹集资源进行训练,当前版本离目标差距巨大,仍需持续完善和快速迭代。
Open-Sora框架由以下组成部分组成
1. Video VQ-VAE:这是一个压缩视频到时间和空间维度的潜在表示的组件。它可以将高分辨率视频压缩成低维度的表示,便于后续的处理和生成。
2.Denoising Diffusion Transformer:去噪扩散变换器(Denoising Diffusion Transformer)这个组件用于从潜在表示中生成视频,通过逐步减少噪声来恢复视频的详细内容。
3.Condition Encoder:条件编码器(Condition Encoder)支持多种条件输入,允许模型根据不同的文本描述或其他条件生成视频内容。

Open sora 实现细节
1.可变长宽比
北大团队参考FIT实施了一种动态掩码策略, 以并行批量训练的同时保持灵活的长宽比。具体来说, 将高分辨率视频在保持长宽比的同时下采样至最长边为256像素, 然后在右侧和底部用零填充至一致的256x256分辨率。这样便于videovae以批量编码视频, 以及便于扩散模型使用注意力掩码对批量潜变量进行去噪。
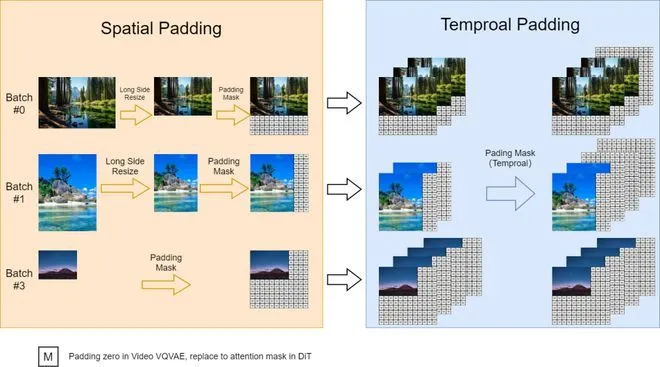
2.可变分辨率
在推理过程中, 尽管目前是在固定的256x256分辨率上进行训练, 但北大团队使用位置插值可以实现可变分辨率采样。将可变分辨率噪声潜变量的位置索引从[0, seq_length-1]下调到[0, 255],以使其与预训练范围对齐。这种调整使得基于注意力的扩散模型能够处理更高分辨率的序列
3.可变时长
北大团队使用VideoGPT中的Video VQ-VAE, 将视频压缩至潜在空间, 并且支持变时长生成。同时扩展空间位置插值至时空维度, 实现对变时长视频的处理

结语
该项目旨在创建一个简单且可扩展的存储库,以重现Sora(OpenAI,但我们更喜欢称其为“CloseAI”)。然而,北大团队的资源有限,研究人员衷心希望所有开源社区都能为这个项目做出贡献。
Prev Chapter:看完马斯克控诉OpenAI的万字报告,感觉他可能被骗惨了
Next Chapter:为了AGI,全员主动996!OpenAI员工自曝3年工作感受
评论区
- 这篇文章还没有收到评论,赶紧来抢沙发吧~
【随机内容】

