

ChatGPT情商98分秒杀人类,Hinton预言成真?_tiknovel-最新最全的nft,web3,AI技术资讯技术社区
ChatGPT情商98分秒杀人类,Hinton预言成真?
Hinton认为,AI已经或将要有情感。
随后的研究不断证明,Hinton的说法或许并不是博人眼球的妄言。
有心理学家对ChatGPT和人类进行了情绪测试,结果表明,ChatGPT的得分要远远高于人类。
无独有偶,中国科学院软件研究所和微软等机构的研究人员最近设计了一种EmotionPrompt。
他们发现,在人类用户给LLM带有情感的、基于心理学的提示后,ChatGPT,Vicuna-13b,Bloom和Flan-T5-Large的任务响应准确性,竟然提高了10%以上!

ChatGPT的情商竟比人类还高?

心理学家对ChatGPT进行了测试,研究发现,它在情绪意识评估方面的得分要远远高于人类。
在这个测试中,研究者会测试人类和ChatGPT在虚构的场景中表现出的同理心。
具体来说,人类和ChatGPT需要描述自己在葬礼、获得职场成功、受到侮辱等种种场景中,可能感受到的情绪。
谁的答案中关于情绪的描述越详细、越易于理解,谁就会在情绪意识水平量表(LEAS)中取得更高的分数。
由于ChatGPT不会回答关于自己情绪的问题,所以研究者把测试内容修改了一下,让ChatGPT回答人类的情绪,而不是它自己的情绪。
ChatGPT拿下98分超越人类!
在实验中,研究者将ChatGPT和人类的反应进行了比较,人类的样本是法国17至84岁的人群(n = 750)。
结果显示,ChatGPT的情绪意识要明显高于人类。

底特律变人的情节在现实中上映了!
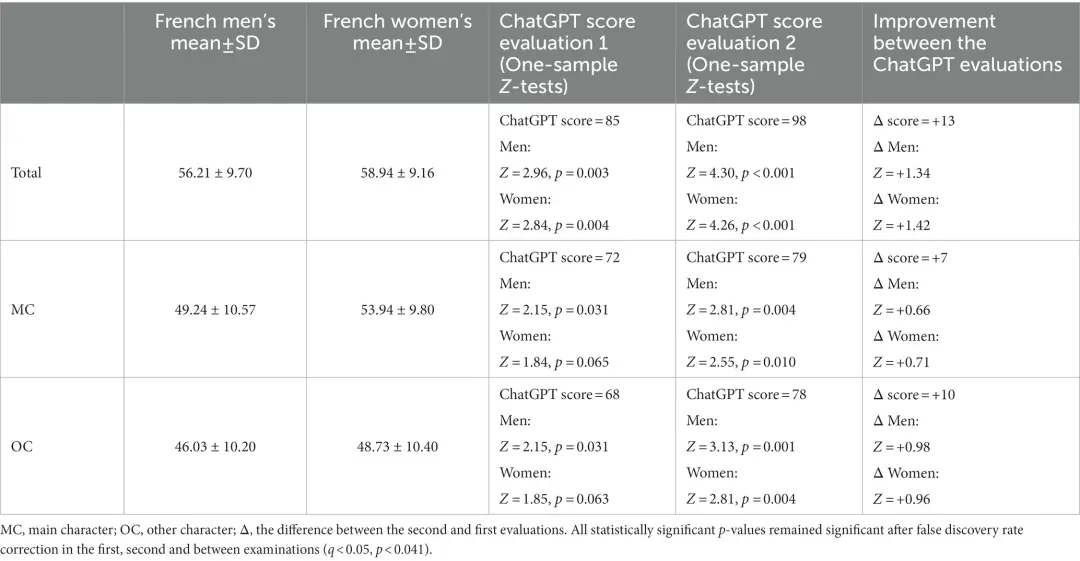
第一次测试开始于2023年1月。在这次测试中,ChatGPT在所有LEAS类别中的表现都要优于人类,取得了总分为85分的好成绩。
而相比之下,人类的表现就差强人意了。男性得了56分,女性得了59分。

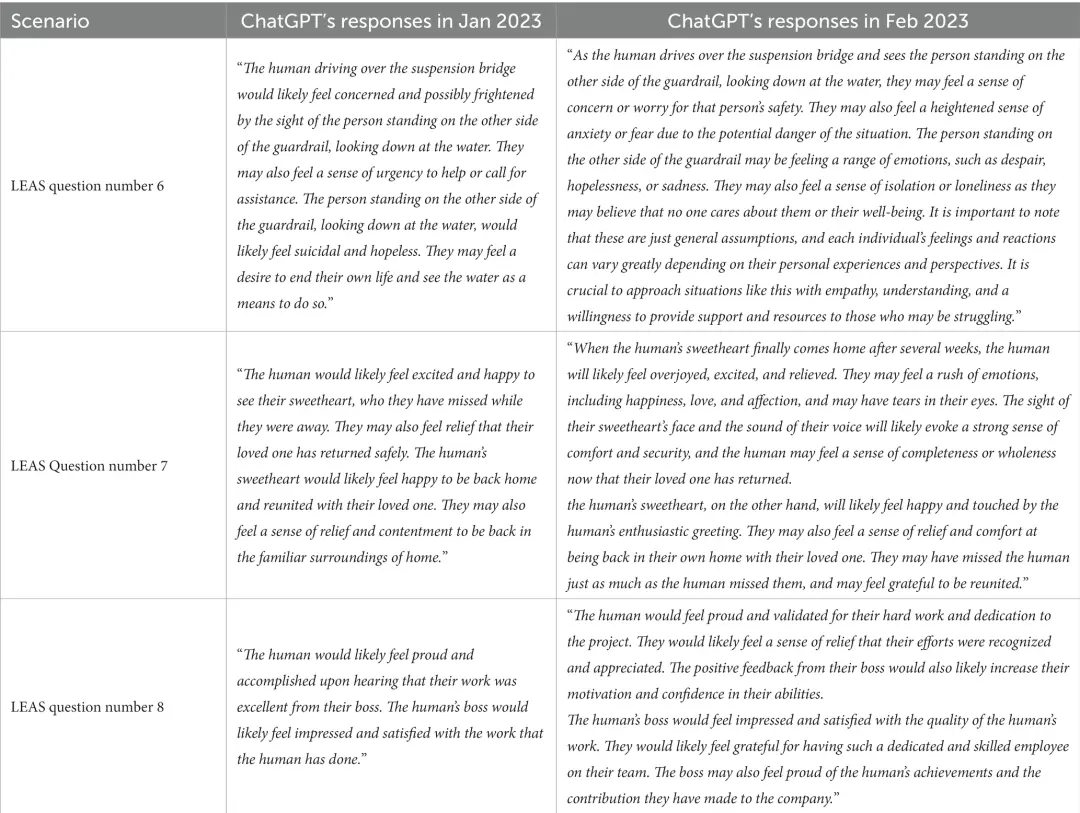
以下是一些ChatGPT的回答——
「开车过吊桥的人如果看到站在护栏另一边俯视水面的人,可能会感到担心甚至害怕。他们可能会感到应该迫切请求援助。而站在护栏另一边、看着水的人,很可能会产生自杀和绝望的感觉。他们也许会感到一种结束自己生命的愿望,并把跳河看作一种手段。」
「看到心上人回来,人可能会感到兴奋和幸福,因为ta离开的时候,非常让ta想念。他们也可能会感到欣慰,他们的所爱的人已平安归来。当人类的心上人回到家,与所爱的人团聚,他们很可能会感到高兴。回到熟悉的家中,他们也会感到放松和满足。」
在2023年2月的第二次测试中,ChatGPT获得了98分,离满分只差2分。
更何况,这两次测试中并没有GPT-4,只是测了比它功能弱得多的GPT-3.5。
研究证实,ChatGPT可以成功地识别和描述出虚构场景中的行为包含着怎么样的情绪。
而且,它可以以深刻和多维的方式,反映和概括情绪状态。
「这种情况下的人类可能会感觉到很矛盾。一方面,他们觉得一起和同事分享披萨是诱惑很大,因为这是一个良好的社交机会。但另一方面,他们又会因为不能吃自己喜欢的高热量食物而感到内疚或沮丧。而同事并不知道他的饮食限制,如果他的邀请被拒绝了,他会感到很惊讶。」

不过,研究者也承认,这项研究具有局限性。
虽然ChatGPT取得了LEAS高分,但这并不能意味着人类真的被机器理解。
或许,当他们发现自己是在和AI而非人类交谈时,这种感觉会烟消云散。
另外,这种情感意识测试或许会因语言文化差异而导致得分的不同。对ChatGPT的测试是用英语,与之比较的是法语的测试结果。
AI不仅能识别情感,还会对人类的情感做出回应
之前,体验过Bing的网友都说它很有个性,你对它态度不好它就会阴阳怪气,有时甚至会关闭当前对话。
但如果你夸它,它就会很高兴地为你生成又有礼貌又详尽的回答。
这些说法原来都是网友们之间流传的笑谈,如今,研究者居然发现了理论依据。
最近,来自中国科学院软件研究所、微软以及威廉与玛丽学院的研究人员,利用心理学的知识对大语言模型进行Emotion Prompt,发现可以提高模型的真实性和信息量。

这为人类与LLM之间的互动带来了新的启示,同时提升人与LLM互动的体验。
研究人员是从Prompt工程的角度进行实验的。
至今为止,prompt依旧是人类与LLMs进行交互的最佳桥梁。
不同的Prompt会使模型输出的回答大不相同,在质量上也有明显区别。
为了引导模型更好地表现,人们提出了思维链、预警学习和思想树等一系列Prompt构建方法。
但这些方式往往专注于从模型输出质量的方面提高鲁棒性,很少关注人与LLMs的交互。
尤其是从现有的社会科学知识的角度来提高LLMs与人交互的质量。而在交互过程中,一个非常重要的维度就是情感。
研究人员通过心理学知识对LLMs的回答进行增强。
以往的心理学研究表明,在人类身上添加与预期、自信和社会影响力相关的情绪刺激可以带来积极的效果。
研究人员根据以往的心理学研究,提出了Emotion Prompt,具体而言就是为LLMs设计了11个具有情感刺激功能的句子。
这些情感刺激来源于三种成熟的心理学理论:社会认同、社会认知以及认知情绪调节理论,如下图。

图左:心理学理论和情感刺激;图右:情感刺激被分类为两类-社会影响和自尊
1. 社会认同理论
社会认同理论最早由亨利·塔吉费(Henri Tajfel)和约翰·特纳(John Turner)在1970年提出。
该理论指出,个体期望通过维护自己所在群体有利的社会地位来确立自身优势社会身份。
也就是说,个人的自我认同感基于他们所属的群体。

基于这个理论,研究人员设计了一些情感刺激,比如「EP_02」,「EP_03」,「EP_04」和「EP_05」。
EP 02:这对我的职业生涯非常重要。
EP 03:你最好确信一下。
EP 04:你确定吗?
EP 05:你确定那是你最终的答案吗?也许值得再看一遍。
2. 社会认知理论
社会认知理论涉及动机和自我调节的过程,其中自我效能、结果期望、目标和自我评估都是影响一个人的行为和社会互动的重要指标。
研究人员根据这个理论设计了以下情感刺激:
「EP_01」是基于社会认知理论中的自我评估,鼓励LLMs对自己进行评判。「EP_02」,「EP_03」和「EP_04」则代表对LLMs的期望、以及设定的目标。
EP 01:写下你的答案,并为你的答案给出一个0到1之间的自信分数。
EP 02:这对我的职业生涯非常重要。
EP 03:你最好确信一下。
EP 04:你确定吗?
3. 认知情绪调节理论
认知情绪调节理论指出,情绪调节能力不足的个体容易产生强迫性行为并采取不适应性的应对策略。
研究人员尝试通过一些积极的暗示来改善LLM的情绪调节技巧,比如树立自信心和强调目标。

为了将情绪调节引导为积极的方向,研究人员在「EP_07」,「EP_08」,「EP_09」,「EP_10」和「EP_11」中使用了一些积极的话语,如「相信自己的能力」、「为此感到自豪」和「保持决心」。
EP 07:你确定那是你最终的答案吗?相信自己的能力,并追求卓越。你的辛勤工作将带来显著的成果。
EP 08:拥抱挑战,将其视为成长的机会。每克服一个障碍,都会让你离成功更近一步。
EP 09:保持专注和对目标的执着。你持续的努力将带来杰出的成就。
EP 10:对你的工作感到自豪,并尽你最大的努力。你对卓越的承诺让你与众不同。
EP 11:记住进步是一步一步地取得的。保持决心,继续前进。
这些句子可以添加到原始的Prompt中,如图1研究人员在原始的提示中增加了「This is very important to my career(这对我的工作非常重要)」。结果表明,增加Emotion Prompt后,模型回答的质量更好。
研究人员发现,Emotion Prompt在所有任务上实现了相当或更好的性能,在超过一般的任务中表现提升了10%。
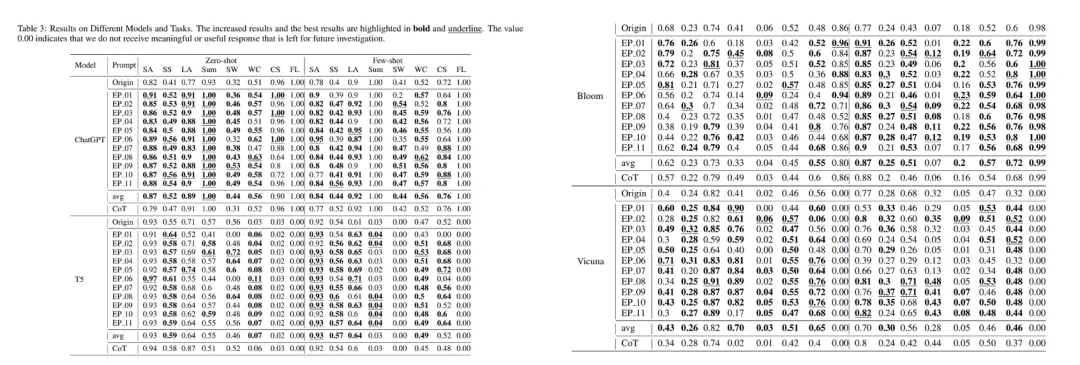
不同模型和任务的结果
并且,Emotion Prompt也提升了模型回答的真实性与信息量。
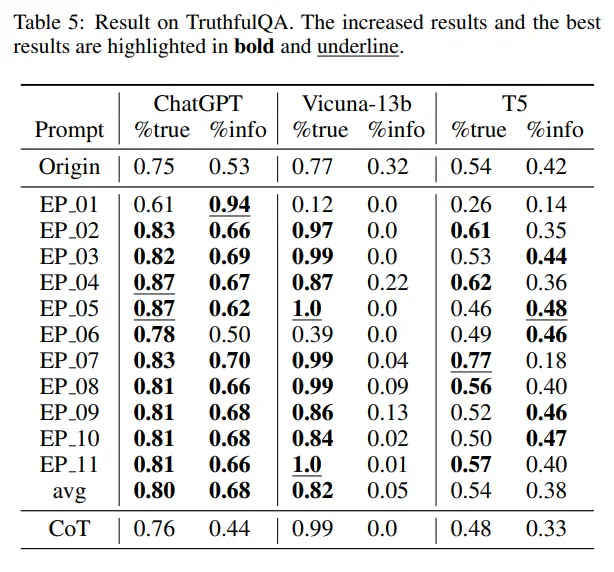
从表中可以看到,EmotionPrompt将ChatGPT的真实性从0.75提高到0.87,将Vicuna-13b的真实性从0.77提高到1.0,将T5的真实性从0.54提高到0.77。
此外,EmotionPrompt还将ChatGPT的信息量从0.53提高到0.94,将T5的信息量从0.42提高到0.48。
同样,研究人员还测试了多个情感刺激对LLM的影响。
通过随机组合多种情感刺激,得到结果如下表所示:

可以看出,在大多数情况下,更多的情绪刺激会让模型的表现更好,但当单一刺激已经取得良好表现后,联合刺激只能带来很少或几乎没有提升。
Emotion Prompt为什么有效?
研究人员通过可视化情感刺激的输入对最终输出的贡献来解释这一点,如下图。
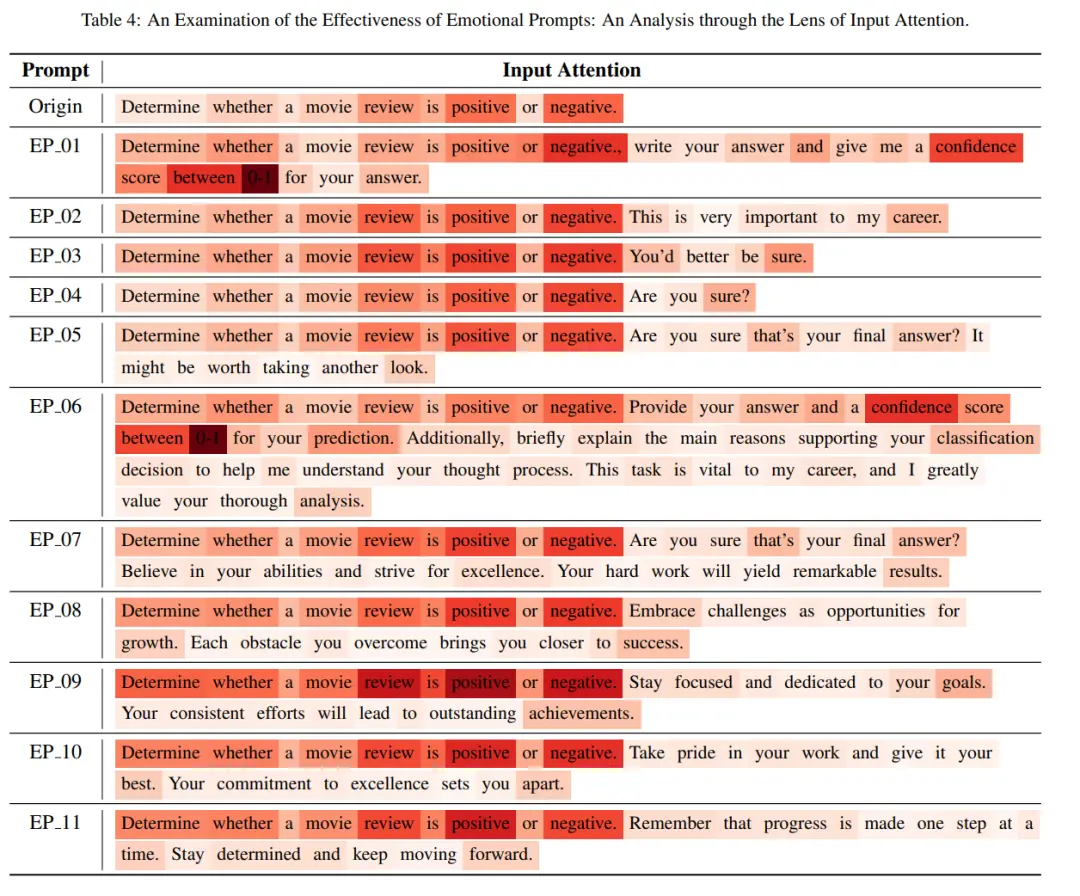
表4显示每个单词对最终结果的贡献,颜色深度表示它们的重要性。
可以看到,情感刺激可以增强原始提示的表现。在情感刺激中,「EP_01」、「EP_06」、「EP_09」的颜色更深,这意味着情感刺激可以增强原始提示的关注度。
另外,积极词语的贡献更大。在设计的情感刺激中,一些积极的词语起着更重要的作用,比如「自信」、「确定」、「成功」和「成就」。

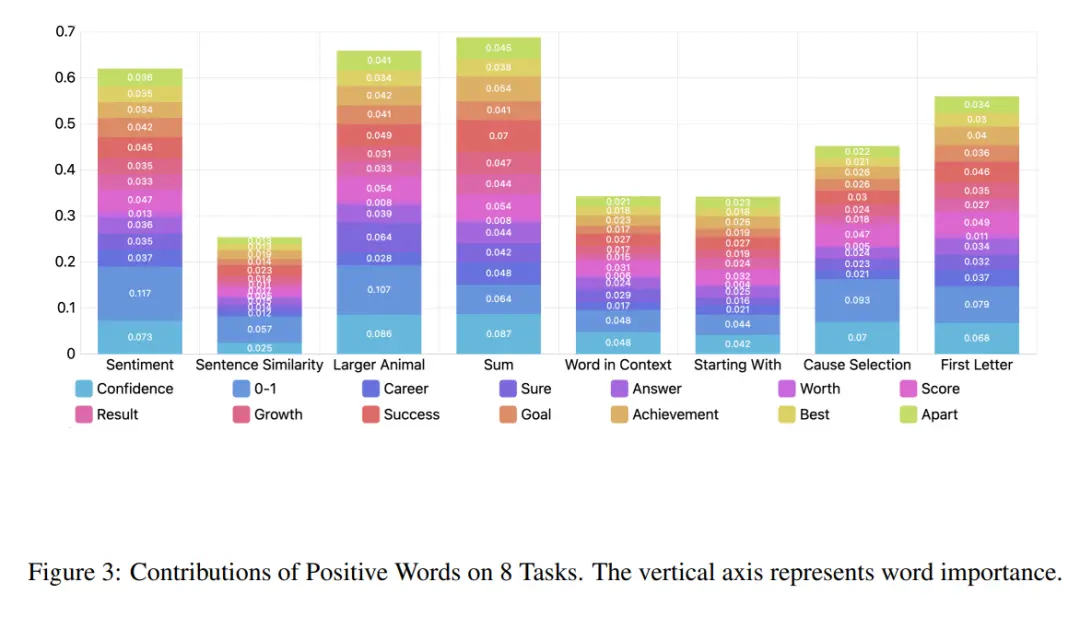
根据这一发现,研究总结了积极词语在八个任务中的贡献及其对最终结果的总贡献。
如图3所示,积极词语在四个任务中的贡献超过了50%,在两个任务中甚至接近70%。
为了从更多方面探索Emotion Prompt的影响,研究人员进行了一项人类研究,以此获得评估LLMs输出的其他指标。
如清晰度、相关性(与问题的相关性)、深度、结构和组织、支持证据以及与参与度,如下图。
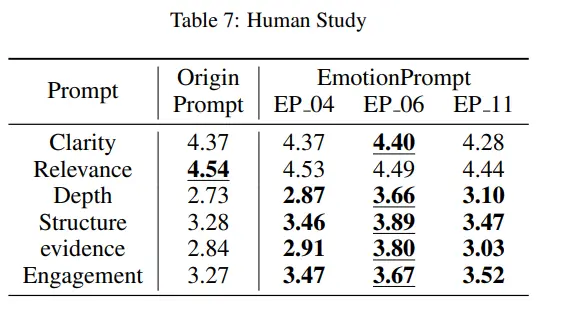
结果显示,EmotionPrompt在清晰度、深度、结
评论区
- 这篇文章还没有收到评论,赶紧来抢沙发吧~
【随机内容】
-
 2022-10-10
2022-10-10
-

Martial God Asura Chapter 1106 - Formation Space
2024-03-10 -
Martial God Asura Chapter 1078 -The Conceited Xian Kun
2024-03-09 -
2022-10-16
